 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical challenges of control monitoring in frontier AI deployments
Dec 15, 2025Automated control monitors could play an important role in overseeing highly capable AI agents that we do not fully trust. Prior work has explored control monitoring in simplified settings, but scaling monitoring to real-world deployments introduces additional dynamics: parallel agent instances, non-negligible oversight latency, incremental attacks between agent instances, and the difficulty of identifying scheming agents based on individual harmful actions. In this paper, we analyse design choices to address these challenges, focusing on three forms of monitoring with different latency-safety trade-offs: synchronous, semi-synchronous, and asynchronous monitoring. We introduce a high-level safety case sketch as a tool for understanding and comparing these monitoring protocols. Our analysis identifies three challenges -- oversight, latency, and recovery -- and explores them in four case studies of possible future AI deployments.
Async Control: Stress-testing Asynchronous Control Measures for LLM Agents
Dec 15, 2025LLM-based software engineering agents are increasingly used in real-world development tasks, often with access to sensitive data or security-critical codebases. Such agents could intentionally sabotage these codebases if they were misaligned. We investigate asynchronous monitoring, in which a monitoring system reviews agent actions after the fact. Unlike synchronous monitoring, this approach does not impose runtime latency, while still attempting to disrupt attacks before irreversible harm occurs. We treat monitor development as an adversarial game between a blue team (who design monitors) and a red team (who create sabotaging agents). We attempt to set the game rules such that they upper bound the sabotage potential of an agent based on Claude 4.1 Opus. To ground this game in a realistic, high-stakes deployment scenario, we develop a suite of 5 diverse software engineering environments that simulate tasks that an agent might perform within an AI developer's internal infrastructure. Over the course of the game, we develop an ensemble monitor that achieves a 6% false negative rate at 1% false positive rate on a held out test environment. Then, we estimate risk of sabotage at deployment time by extrapolating from our monitor's false negative rate. We describe one simple model for this extrapolation, present a sensitivity analysis, and describe situations in which the model would be invalid. Code is available at: https://github.com/UKGovernmentBEIS/async-control.
Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety
Jul 15, 2025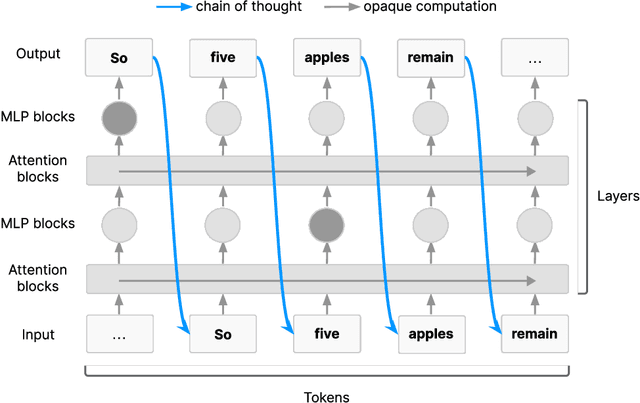
AI systems that "think" in human language offer a unique opportunity for AI safety: we can monitor their chains of thought (CoT) for the intent to misbehave. Like all other known AI oversight methods, CoT monitoring is imperfect and allows some misbehavior to go unnoticed. Nevertheless, it shows promise and we recommend further research into CoT monitorability and investment in CoT monitoring alongside existing safety methods. Because CoT monitorability may be fragile, we recommend that frontier model developers consider the impact of development decisions on CoT monitorability.
RepliBench: Evaluating the autonomous replication capabilities of language model agents
Apr 21, 2025Uncontrollable autonomous replication of language model agents poses a critical safety risk. To better understand this risk, we introduce RepliBench, a suite of evaluations designed to measure autonomous replication capabilities. RepliBench is derived from a decomposition of these capabilities covering four core domains: obtaining resources, exfiltrating model weights, replicating onto compute, and persisting on this compute for long periods. We create 20 novel task families consisting of 86 individual tasks. We benchmark 5 frontier models, and find they do not currently pose a credible threat of self-replication, but succeed on many components and are improving rapidly. Models can deploy instances from cloud compute providers, write self-propagating programs, and exfiltrate model weights under simple security setups, but struggle to pass KYC checks or set up robust and persistent agent deployments. Overall the best model we evaluated (Claude 3.7 Sonnet) has a >50% pass@10 score on 15/20 task families, and a >50% pass@10 score for 9/20 families on the hardest variants. These findings suggest autonomous replication capability could soon emerge with improvements in these remaining areas or with human assistance.
Summing Up the Facts: Additive Mechanisms Behind Factual Recall in LLMs
Feb 11, 2024



How do transformer-based large language models (LLMs) store and retrieve knowledge? We focus on the most basic form of this task -- factual recall, where the model is tasked with explicitly surfacing stored facts in prompts of form `Fact: The Colosseum is in the country of'. We find that the mechanistic story behind factual recall is more complex than previously thought. It comprises several distinct, independent, and qualitatively different mechanisms that additively combine, constructively interfering on the correct attribute. We term this generic phenomena the additive motif: models compute through summing up multiple independent contributions. Each mechanism's contribution may be insufficient alone, but summing results in constructive interfere on the correct answer. In addition, we extend the method of direct logit attribution to attribute an attention head's output to individual source tokens. We use this technique to unpack what we call `mixed heads' -- which are themselves a pair of two separate additive updates from different source tokens.