 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Better Deception Probes Using Targeted Instruction Pairs
Feb 01, 2026Linear probes are a promising approach for monitoring AI systems for deceptive behaviour. Previous work has shown that a linear classifier trained on a contrastive instruction pair and a simple dataset can achieve good performance. However, these probes exhibit notable failures even in straightforward scenarios, including spurious correlations and false positives on non-deceptive responses. In this paper, we identify the importance of the instruction pair used during training. Furthermore, we show that targeting specific deceptive behaviors through a human-interpretable taxonomy of deception leads to improved results on evaluation datasets. Our findings reveal that instruction pairs capture deceptive intent rather than content-specific patterns, explaining why prompt choice dominates probe performance (70.6% of variance). Given the heterogeneity of deception types across datasets, we conclude that organizations should design specialized probes targeting their specific threat models rather than seeking a universal deception detector.
Auditing Games for Sandbagging
Dec 08, 2025Future AI systems could conceal their capabilities ('sandbagging') during evaluations, potentially misleading developers and auditors. We stress-tested sandbagging detection techniques using an auditing game. First, a red team fine-tuned five models, some of which conditionally underperformed, as a proxy for sandbagging. Second, a blue team used black-box, model-internals, or training-based approaches to identify sandbagging models. We found that the blue team could not reliably discriminate sandbaggers from benign models. Black-box approaches were defeated by effective imitation of a weaker model. Linear probes, a model-internals approach, showed more promise but their naive application was vulnerable to behaviours instilled by the red team. We also explored capability elicitation as a strategy for detecting sandbagging. Although Prompt-based elicitation was not reliable, training-based elicitation consistently elicited full performance from the sandbagging models, using only a single correct demonstration of the evaluation task. However the performance of benign models was sometimes also raised, so relying on elicitation as a detection strategy was prone to false-positives. In the short-term, we recommend developers remove potential sandbagging using on-distribution training for elicitation. In the longer-term, further research is needed to ensure the efficacy of training-based elicitation, and develop robust methods for sandbagging detection. We open source our model organisms at https://github.com/AI-Safety-Institute/sandbagging_auditing_games and select transcripts and results at https://huggingface.co/datasets/sandbagging-games/evaluation_logs . A demo illustrating the game can be played at https://sandbagging-demo.far.ai/ .
Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety
Jul 15, 2025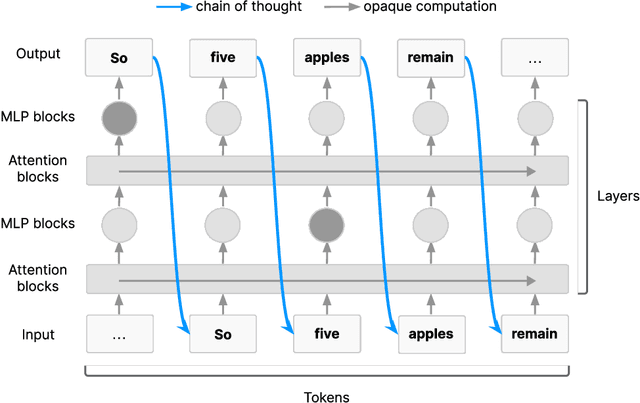
AI systems that "think" in human language offer a unique opportunity for AI safety: we can monitor their chains of thought (CoT) for the intent to misbehave. Like all other known AI oversight methods, CoT monitoring is imperfect and allows some misbehavior to go unnoticed. Nevertheless, it shows promise and we recommend further research into CoT monitorability and investment in CoT monitoring alongside existing safety methods. Because CoT monitorability may be fragile, we recommend that frontier model developers consider the impact of development decisions on CoT monitorability.
SAEBench: A Comprehensive Benchmark for Sparse Autoencoders in Language Model Interpretability
Mar 13, 2025Sparse autoencoders (SAEs) are a popular technique for interpreting language model activations, and there is extensive recent work on improving SAE effectiveness. However, most prior work evaluates progress using unsupervised proxy metrics with unclear practical relevance. We introduce SAEBench, a comprehensive evaluation suite that measures SAE performance across seven diverse metrics, spanning interpretability, feature disentanglement and practical applications like unlearning. To enable systematic comparison, we open-source a suite of over 200 SAEs across eight recently proposed SAE architectures and training algorithms. Our evaluation reveals that gains on proxy metrics do not reliably translate to better practical performance. For instance, while Matryoshka SAEs slightly underperform on existing proxy metrics, they substantially outperform other architectures on feature disentanglement metrics; moreover, this advantage grows with SAE scale. By providing a standardized framework for measuring progress in SAE development, SAEBench enables researchers to study scaling trends and make nuanced comparisons between different SAE architectures and training methodologies. Our interactive interface enables researchers to flexibly visualize relationships between metrics across hundreds of open-source SAEs at: https://saebench.xyz
Sparse Autoencoders Do Not Find Canonical Units of Analysis
Feb 07, 2025



A common goal of mechanistic interpretability is to decompose the activations of neural networks into features: interpretable properties of the input computed by the model. Sparse autoencoders (SAEs) are a popular method for finding these features in LLMs, and it has been postulated that they can be used to find a \textit{canonical} set of units: a unique and complete list of atomic features. We cast doubt on this belief using two novel techniques: SAE stitching to show they are incomplete, and meta-SAEs to show they are not atomic. SAE stitching involves inserting or swapping latents from a larger SAE into a smaller one. Latents from the larger SAE can be divided into two categories: \emph{novel latents}, which improve performance when added to the smaller SAE, indicating they capture novel information, and \emph{reconstruction latents}, which can replace corresponding latents in the smaller SAE that have similar behavior. The existence of novel features indicates incompleteness of smaller SAEs. Using meta-SAEs -- SAEs trained on the decoder matrix of another SAE -- we find that latents in SAEs often decompose into combinations of latents from a smaller SAE, showing that larger SAE latents are not atomic. The resulting decompositions are often interpretable; e.g. a latent representing ``Einstein'' decomposes into ``scientist'', ``Germany'', and ``famous person''. Even if SAEs do not find canonical units of analysis, they may still be useful tools. We suggest that future research should either pursue different approaches for identifying such units, or pragmatically choose the SAE size suited to their task. We provide an interactive dashboard to explore meta-SAEs: https://metasaes.streamlit.app/
Open Problems in Mechanistic Interpretability
Jan 27, 2025



Mechanistic interpretability aims to understand the computational mechanisms underlying neural networks' capabilities in order to accomplish concrete scientific and engineering goals. Progress in this field thus promises to provide greater assurance over AI system behavior and shed light on exciting scientific questions about the nature of intelligence. Despite recent progress toward these goals, there are many open problems in the field that require solutions before many scientific and practical benefits can be realized: Our methods require both conceptual and practical improvements to reveal deeper insights; we must figure out how best to apply our methods in pursuit of specific goals; and the field must grapple with socio-technical challenges that influence and are influenced by our work. This forward-facing review discusses the current frontier of mechanistic interpretability and the open problems that the field may benefit from prioritizing.
A is for Absorption: Studying Feature Splitting and Absorption in Sparse Autoencoders
Sep 25, 2024



Sparse Autoencoders (SAEs) have emerged as a promising approach to decompose the activations of Large Language Models (LLMs) into human-interpretable latents. In this paper, we pose two questions. First, to what extent do SAEs extract monosemantic and interpretable latents? Second, to what extent does varying the sparsity or the size of the SAE affect monosemanticity / interpretability? By investigating these questions in the context of a simple first-letter identification task where we have complete access to ground truth labels for all tokens in the vocabulary, we are able to provide more detail than prior investigations. Critically, we identify a problematic form of feature-splitting we call feature absorption where seemingly monosemantic latents fail to fire in cases where they clearly should. Our investigation suggests that varying SAE size or sparsity is insufficient to solve this issue, and that there are deeper conceptual issues in need of resolution.