 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoordinating Policies Among Multiple Agents via an Intelligent Communication Channel
May 25, 2022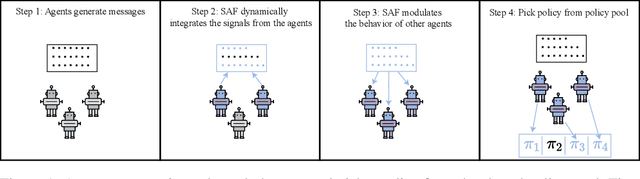


In Multi-Agent Reinforcement Learning (MARL), specialized channels are often introduced that allow agents to communicate directly with one another. In this paper, we propose an alternative approach whereby agents communicate through an intelligent facilitator that learns to sift through and interpret signals provided by all agents to improve the agents' collective performance. To ensure that this facilitator does not become a centralized controller, agents are incentivized to reduce their dependence on the messages it conveys, and the messages can only influence the selection of a policy from a fixed set, not instantaneous actions given the policy. We demonstrate the strength of this architecture over existing baselines on several cooperative MARL environments.
FedILC: Weighted Geometric Mean and Invariant Gradient Covariance for Federated Learning on Non-IID Data
May 19, 2022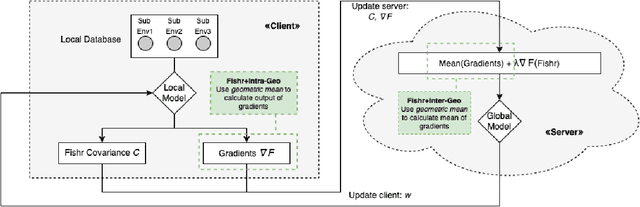

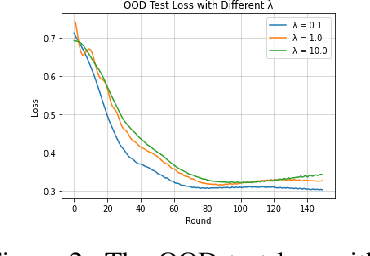
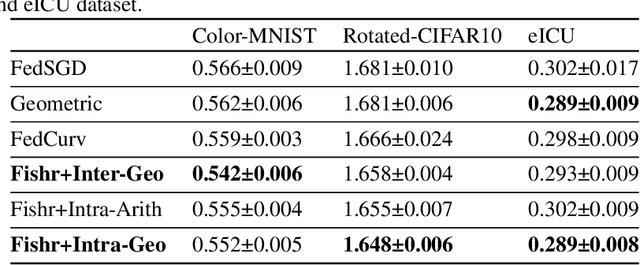
Federated learning is a distributed machine learning approach which enables a shared server model to learn by aggregating the locally-computed parameter updates with the training data from spatially-distributed client silos. Though successfully possessing advantages in both scale and privacy, federated learning is hurt by domain shift problems, where the learning models are unable to generalize to unseen domains whose data distribution is non-i.i.d. with respect to the training domains. In this study, we propose the Federated Invariant Learning Consistency (FedILC) approach, which leverages the gradient covariance and the geometric mean of Hessians to capture both inter-silo and intra-silo consistencies of environments and unravel the domain shift problems in federated networks. The benchmark and real-world dataset experiments bring evidence that our proposed algorithm outperforms conventional baselines and similar federated learning algorithms. This is relevant to various fields such as medical healthcare, computer vision, and the Internet of Things (IoT). The code is released at https://github.com/mikemikezhu/FedILC.
A Highly Adaptive Acoustic Model for Accurate Multi-Dialect Speech Recognition
May 06, 2022
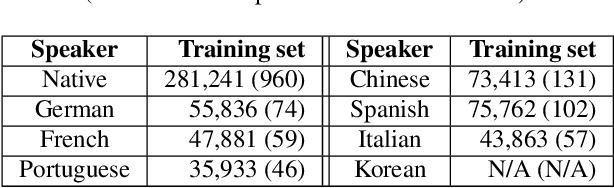
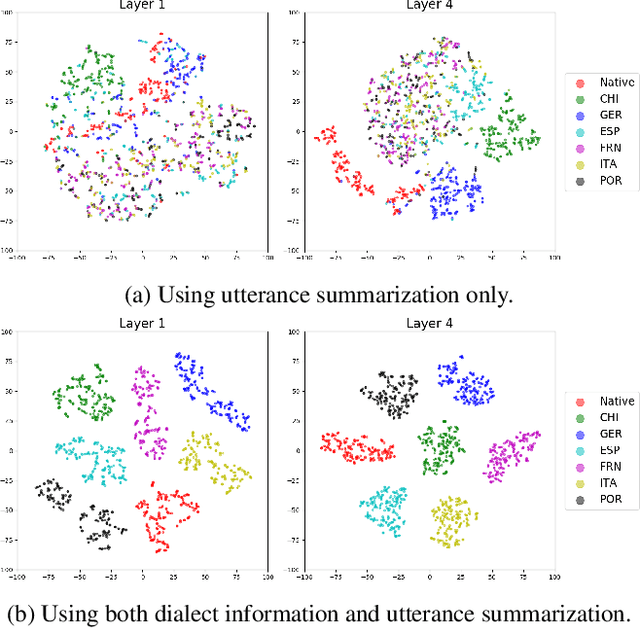
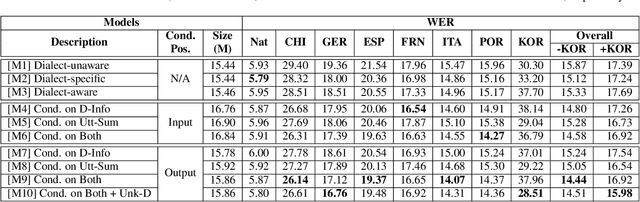
Despite the success of deep learning in speech recognition, multi-dialect speech recognition remains a difficult problem. Although dialect-specific acoustic models are known to perform well in general, they are not easy to maintain when dialect-specific data is scarce and the number of dialects for each language is large. Therefore, a single unified acoustic model (AM) that generalizes well for many dialects has been in demand. In this paper, we propose a novel acoustic modeling technique for accurate multi-dialect speech recognition with a single AM. Our proposed AM is dynamically adapted based on both dialect information and its internal representation, which results in a highly adaptive AM for handling multiple dialects simultaneously. We also propose a simple but effective training method to deal with unseen dialects. The experimental results on large scale speech datasets show that the proposed AM outperforms all the previous ones, reducing word error rates (WERs) by 8.11% relative compared to a single all-dialects AM and by 7.31% relative compared to dialect-specific AMs.
Temporal Abstractions-Augmented Temporally Contrastive Learning: An Alternative to the Laplacian in RL
Mar 21, 2022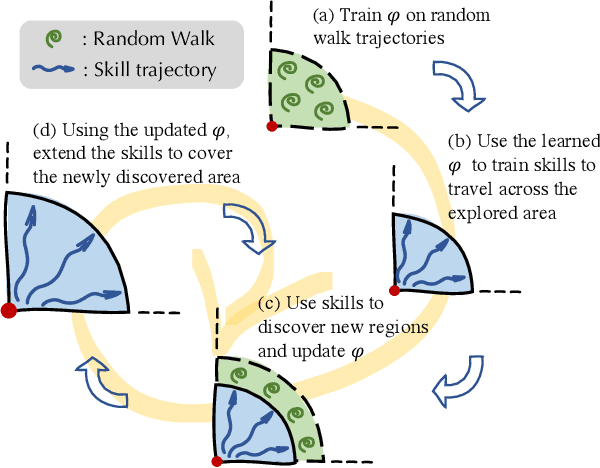
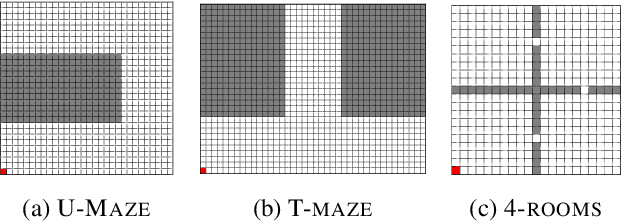

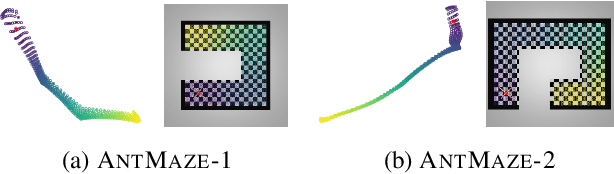
In reinforcement learning, the graph Laplacian has proved to be a valuable tool in the task-agnostic setting, with applications ranging from skill discovery to reward shaping. Recently, learning the Laplacian representation has been framed as the optimization of a temporally-contrastive objective to overcome its computational limitations in large (or continuous) state spaces. However, this approach requires uniform access to all states in the state space, overlooking the exploration problem that emerges during the representation learning process. In this work, we propose an alternative method that is able to recover, in a non-uniform-prior setting, the expressiveness and the desired properties of the Laplacian representation. We do so by combining the representation learning with a skill-based covering policy, which provides a better training distribution to extend and refine the representation. We also show that a simple augmentation of the representation objective with the learned temporal abstractions improves dynamics-awareness and helps exploration. We find that our method succeeds as an alternative to the Laplacian in the non-uniform setting and scales to challenging continuous control environments. Finally, even if our method is not optimized for skill discovery, the learned skills can successfully solve difficult continuous navigation tasks with sparse rewards, where standard skill discovery approaches are no so effective.
A New Era: Intelligent Tutoring Systems Will Transform Online Learning for Millions
Mar 03, 2022
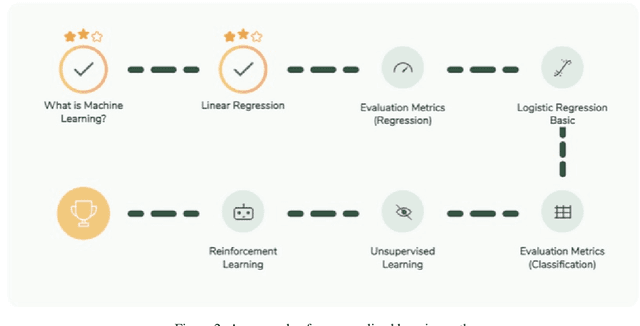
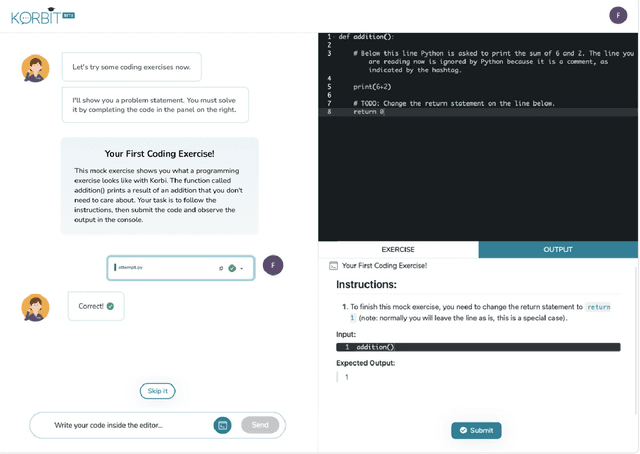
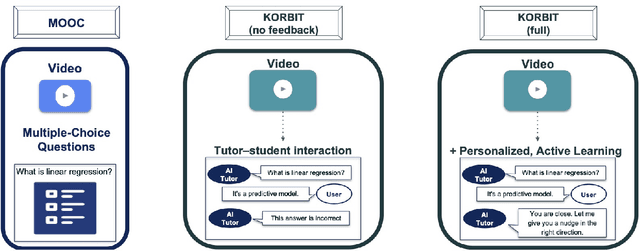
Despite artificial intelligence (AI) having transformed major aspects of our society, less than a fraction of its potential has been explored, let alone deployed, for education. AI-powered learning can provide millions of learners with a highly personalized, active and practical learning experience, which is key to successful learning. This is especially relevant in the context of online learning platforms. In this paper, we present the results of a comparative head-to-head study on learning outcomes for two popular online learning platforms (n=199 participants): A MOOC platform following a traditional model delivering content using lecture videos and multiple-choice quizzes, and the Korbit learning platform providing a highly personalized, active and practical learning experience. We observe a huge and statistically significant increase in the learning outcomes, with students on the Korbit platform providing full feedback resulting in higher course completion rates and achieving learning gains 2 to 2.5 times higher than both students on the MOOC platform and students in a control group who don't receive personalized feedback on the Korbit platform. The results demonstrate the tremendous impact that can be achieved with a personalized, active learning AI-powered system. Making this technology and learning experience available to millions of learners around the world will represent a significant leap forward towards the democratization of education.
Continuous-Time Meta-Learning with Forward Mode Differentiation
Mar 02, 2022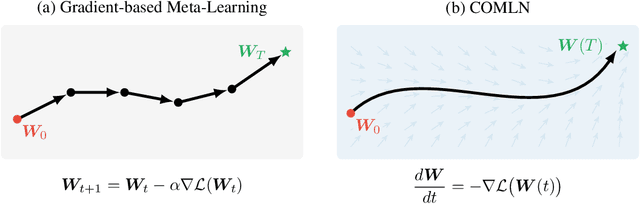
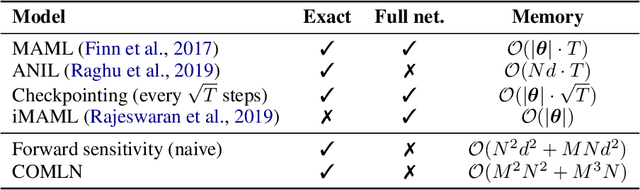
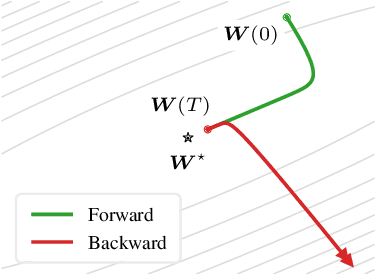
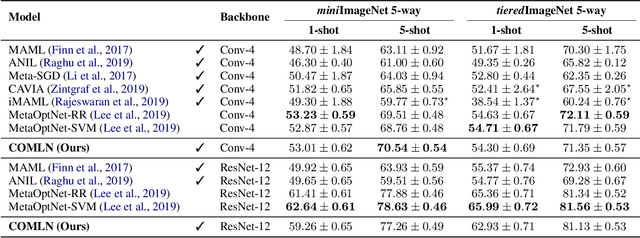
Drawing inspiration from gradient-based meta-learning methods with infinitely small gradient steps, we introduce Continuous-Time Meta-Learning (COMLN), a meta-learning algorithm where adaptation follows the dynamics of a gradient vector field. Specifically, representations of the inputs are meta-learned such that a task-specific linear classifier is obtained as a solution of an ordinary differential equation (ODE). Treating the learning process as an ODE offers the notable advantage that the length of the trajectory is now continuous, as opposed to a fixed and discrete number of gradient steps. As a consequence, we can optimize the amount of adaptation necessary to solve a new task using stochastic gradient descent, in addition to learning the initial conditions as is standard practice in gradient-based meta-learning. Importantly, in order to compute the exact meta-gradients required for the outer-loop updates, we devise an efficient algorithm based on forward mode differentiation, whose memory requirements do not scale with the length of the learning trajectory, thus allowing longer adaptation in constant memory. We provide analytical guarantees for the stability of COMLN, we show empirically its efficiency in terms of runtime and memory usage, and we illustrate its effectiveness on a range of few-shot image classification problems.
Biological Sequence Design with GFlowNets
Mar 02, 2022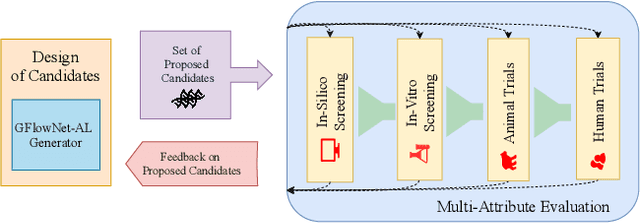
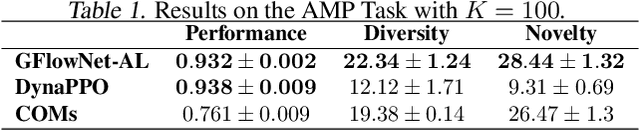
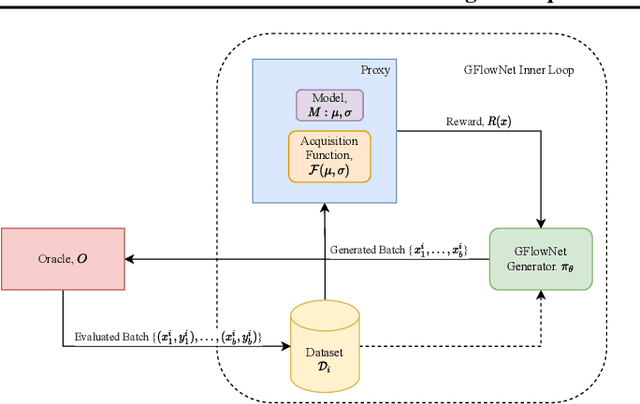
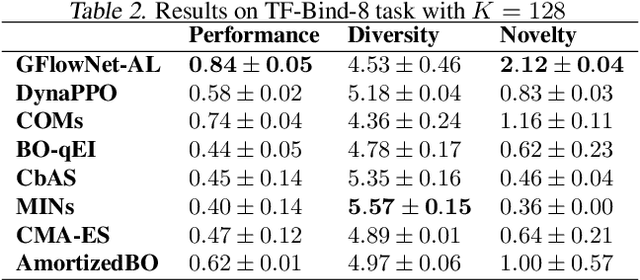
Design of de novo biological sequences with desired properties, like protein and DNA sequences, often involves an active loop with several rounds of molecule ideation and expensive wet-lab evaluations. These experiments can consist of multiple stages, with increasing levels of precision and cost of evaluation, where candidates are filtered. This makes the diversity of proposed candidates a key consideration in the ideation phase. In this work, we propose an active learning algorithm leveraging epistemic uncertainty estimation and the recently proposed GFlowNets as a generator of diverse candidate solutions, with the objective to obtain a diverse batch of useful (as defined by some utility function, for example, the predicted anti-microbial activity of a peptide) and informative candidates after each round. We also propose a scheme to incorporate existing labeled datasets of candidates, in addition to a reward function, to speed up learning in GFlowNets. We present empirical results on several biological sequence design tasks, and we find that our method generates more diverse and novel batches with high scoring candidates compared to existing approaches.
Combining Modular Skills in Multitask Learning
Mar 01, 2022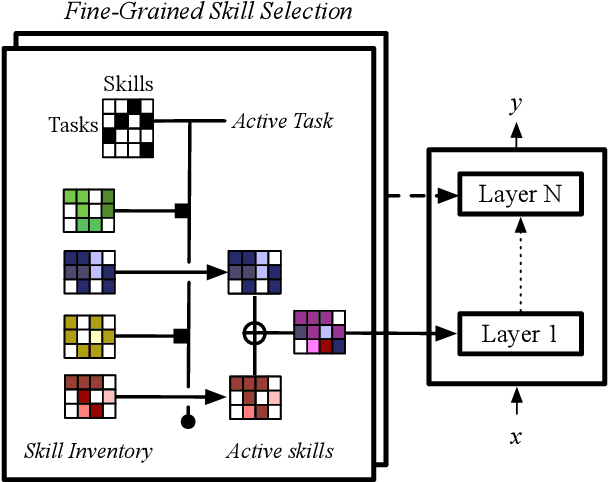
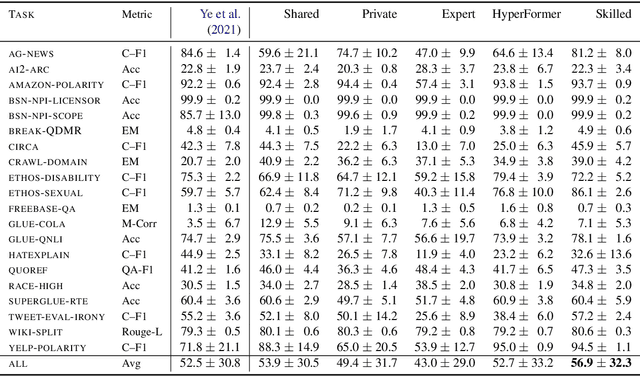
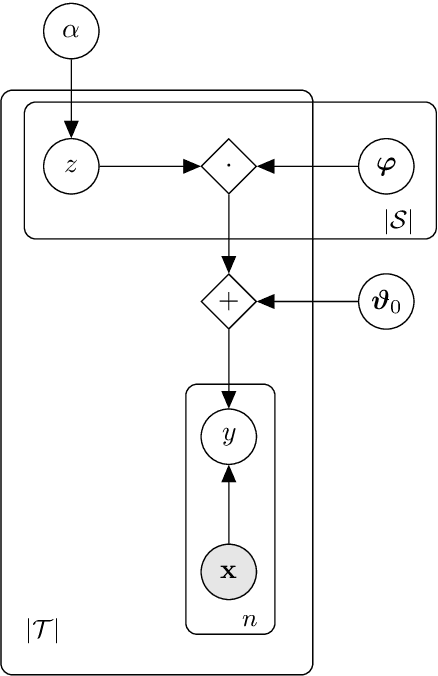
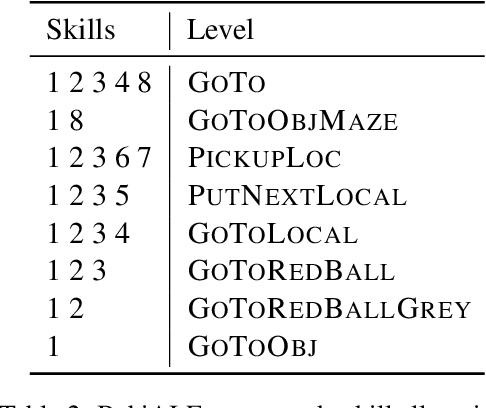
A modular design encourages neural models to disentangle and recombine different facets of knowledge to generalise more systematically to new tasks. In this work, we assume that each task is associated with a subset of latent discrete skills from a (potentially small) inventory. In turn, skills correspond to parameter-efficient (sparse / low-rank) model parameterisations. By jointly learning these and a task-skill allocation matrix, the network for each task is instantiated as the average of the parameters of active skills. To favour non-trivial soft partitions of skills across tasks, we experiment with a series of inductive biases, such as an Indian Buffet Process prior and a two-speed learning rate. We evaluate our latent-skill model on two main settings: 1) multitask reinforcement learning for grounded instruction following on 8 levels of the BabyAI platform; and 2) few-shot adaptation of pre-trained text-to-text generative models on CrossFit, a benchmark comprising 160 NLP tasks. We find that the modular design of a network significantly increases sample efficiency in reinforcement learning and few-shot generalisation in supervised learning, compared to baselines with fully shared, task-specific, or conditionally generated parameters where knowledge is entangled across tasks. In addition, we show how discrete skills help interpretability, as they yield an explicit hierarchy of tasks.
Bayesian Structure Learning with Generative Flow Networks
Feb 28, 2022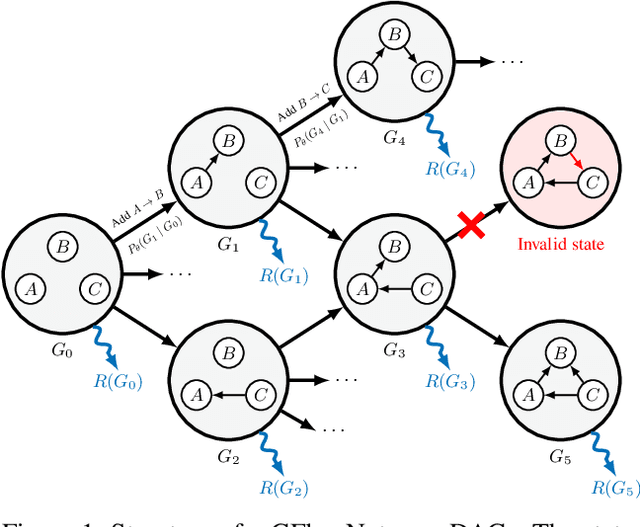
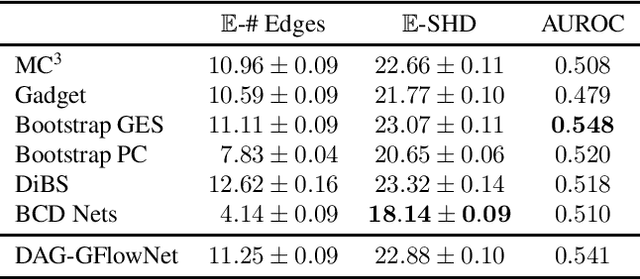
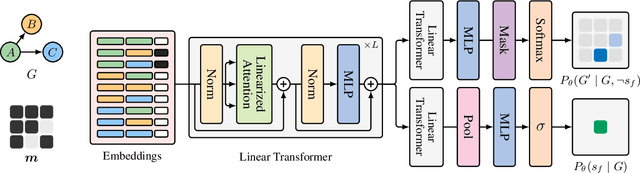
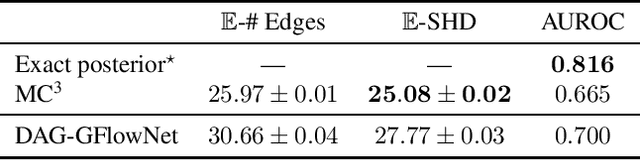
In Bayesian structure learning, we are interested in inferring a distribution over the directed acyclic graph (DAG) structure of Bayesian networks, from data. Defining such a distribution is very challenging, due to the combinatorially large sample space, and approximations based on MCMC are often required. Recently, a novel class of probabilistic models, called Generative Flow Networks (GFlowNets), have been introduced as a general framework for generative modeling of discrete and composite objects, such as graphs. In this work, we propose to use a GFlowNet as an alternative to MCMC for approximating the posterior distribution over the structure of Bayesian networks, given a dataset of observations. Generating a sample DAG from this approximate distribution is viewed as a sequential decision problem, where the graph is constructed one edge at a time, based on learned transition probabilities. Through evaluation on both simulated and real data, we show that our approach, called DAG-GFlowNet, provides an accurate approximation of the posterior over DAGs, and it compares favorably against other methods based on MCMC or variational inference.
RECOVER: sequential model optimization platform for combination drug repurposing identifies novel synergistic compounds in vitro
Feb 07, 2022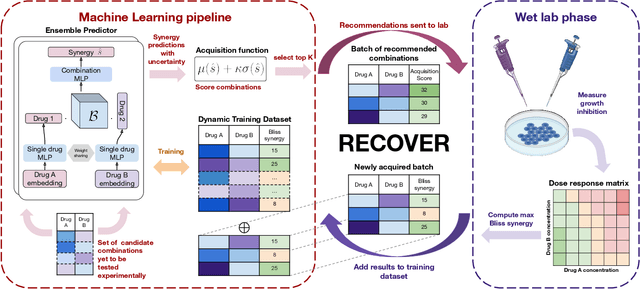

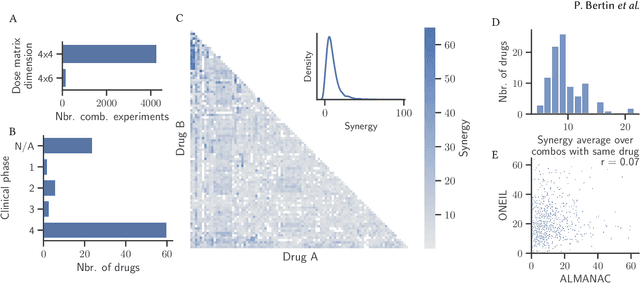

Selecting optimal drug repurposing combinations for further preclinical development is a challenging technical feat. Due to the toxicity of many therapeutic agents (e.g., chemotherapy), practitioners have favoured selection of synergistic compounds whereby lower doses can be used whilst maintaining high efficacy. For a fixed small molecule library, an exhaustive combinatorial chemical screen becomes infeasible to perform for academic and industry laboratories alike. Deep learning models have achieved state-of-the-art results in silico for the prediction of synergy scores. However, databases of drug combinations are highly biased towards synergistic agents and these results do not necessarily generalise out of distribution. We employ a sequential model optimization search applied to a deep learning model to quickly discover highly synergistic drug combinations active against a cancer cell line, while requiring substantially less screening than an exhaustive evaluation. Through iteratively adapting the model to newly acquired data, after only 3 rounds of ML-guided experimentation (including a calibration round), we find that the set of combinations queried by our model is enriched for highly synergistic combinations. Remarkably, we rediscovered a synergistic drug combination that was later confirmed to be under study within clinical trials.