 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotionAdapter: Video Motion Transfer via Content-Aware Attention Customization
Jan 05, 2026Recent advances in diffusion-based text-to-video models, particularly those built on the diffusion transformer architecture, have achieved remarkable progress in generating high-quality and temporally coherent videos. However, transferring complex motions between videos remains challenging. In this work, we present MotionAdapter, a content-aware motion transfer framework that enables robust and semantically aligned motion transfer within DiT-based T2V models. Our key insight is that effective motion transfer requires \romannumeral1) explicit disentanglement of motion from appearance and \romannumeral 2) adaptive customization of motion to target content. MotionAdapter first isolates motion by analyzing cross-frame attention within 3D full-attention modules to extract attention-derived motion fields. To bridge the semantic gap between reference and target videos, we further introduce a DINO-guided motion customization module that rearranges and refines motion fields based on content correspondences. The customized motion field is then used to guide the DiT denoising process, ensuring that the synthesized video inherits the reference motion while preserving target appearance and semantics. Extensive experiments demonstrate that MotionAdapter outperforms state-of-the-art methods in both qualitative and quantitative evaluations. Moreover, MotionAdapter naturally supports complex motion transfer and motion editing tasks such as zooming.
AvatarVTON: 4D Virtual Try-On for Animatable Avatars
Oct 06, 2025We propose AvatarVTON, the first 4D virtual try-on framework that generates realistic try-on results from a single in-shop garment image, enabling free pose control, novel-view rendering, and diverse garment choices. Unlike existing methods, AvatarVTON supports dynamic garment interactions under single-view supervision, without relying on multi-view garment captures or physics priors. The framework consists of two key modules: (1) a Reciprocal Flow Rectifier, a prior-free optical-flow correction strategy that stabilizes avatar fitting and ensures temporal coherence; and (2) a Non-Linear Deformer, which decomposes Gaussian maps into view-pose-invariant and view-pose-specific components, enabling adaptive, non-linear garment deformations. To establish a benchmark for 4D virtual try-on, we extend existing baselines with unified modules for fair qualitative and quantitative comparisons. Extensive experiments show that AvatarVTON achieves high fidelity, diversity, and dynamic garment realism, making it well-suited for AR/VR, gaming, and digital-human applications.
Test-Time Reinforcement Learning for GUI Grounding via Region Consistency
Aug 07, 2025Graphical User Interface (GUI) grounding, the task of mapping natural language instructions to precise screen coordinates, is fundamental to autonomous GUI agents. While existing methods achieve strong performance through extensive supervised training or reinforcement learning with labeled rewards, they remain constrained by the cost and availability of pixel-level annotations. We observe that when models generate multiple predictions for the same GUI element, the spatial overlap patterns reveal implicit confidence signals that can guide more accurate localization. Leveraging this insight, we propose GUI-RC (Region Consistency), a test-time scaling method that constructs spatial voting grids from multiple sampled predictions to identify consensus regions where models show highest agreement. Without any training, GUI-RC improves accuracy by 2-3% across various architectures on ScreenSpot benchmarks. We further introduce GUI-RCPO (Region Consistency Policy Optimization), which transforms these consistency patterns into rewards for test-time reinforcement learning. By computing how well each prediction aligns with the collective consensus, GUI-RCPO enables models to iteratively refine their outputs on unlabeled data during inference. Extensive experiments demonstrate the generality of our approach: GUI-RC boosts Qwen2.5-VL-3B-Instruct from 80.11% to 83.57% on ScreenSpot-v2, while GUI-RCPO further improves it to 85.14% through self-supervised optimization. Our approach reveals the untapped potential of test-time scaling and test-time reinforcement learning for GUI grounding, offering a promising path toward more robust and data-efficient GUI agents.
HarmonPaint: Harmonized Training-Free Diffusion Inpainting
Jul 22, 2025Existing inpainting methods often require extensive retraining or fine-tuning to integrate new content seamlessly, yet they struggle to maintain coherence in both structure and style between inpainted regions and the surrounding background. Motivated by these limitations, we introduce HarmonPaint, a training-free inpainting framework that seamlessly integrates with the attention mechanisms of diffusion models to achieve high-quality, harmonized image inpainting without any form of training. By leveraging masking strategies within self-attention, HarmonPaint ensures structural fidelity without model retraining or fine-tuning. Additionally, we exploit intrinsic diffusion model properties to transfer style information from unmasked to masked regions, achieving a harmonious integration of styles. Extensive experiments demonstrate the effectiveness of HarmonPaint across diverse scenes and styles, validating its versatility and performance.
Deep learning-derived arterial input function
May 30, 2025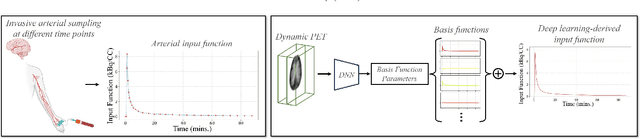

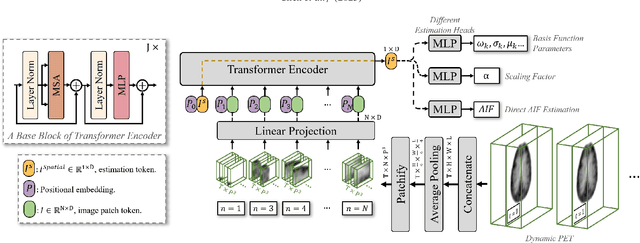
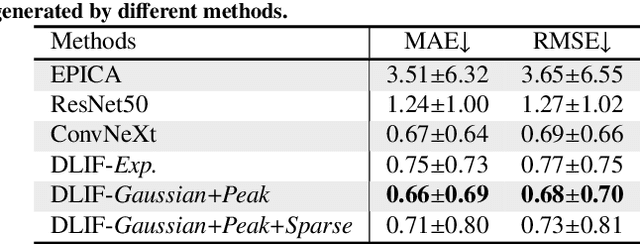
Dynamic positron emission tomography (PET) imaging combined with radiotracer kinetic modeling is a powerful technique for visualizing biological processes in the brain, offering valuable insights into brain functions and neurological disorders such as Alzheimer's and Parkinson's diseases. Accurate kinetic modeling relies heavily on the use of a metabolite-corrected arterial input function (AIF), which typically requires invasive and labor-intensive arterial blood sampling. While alternative non-invasive approaches have been proposed, they often compromise accuracy or still necessitate at least one invasive blood sampling. In this study, we present the deep learning-derived arterial input function (DLIF), a deep learning framework capable of estimating a metabolite-corrected AIF directly from dynamic PET image sequences without any blood sampling. We validated DLIF using existing dynamic PET patient data. We compared DLIF and resulting parametric maps against ground truth measurements. Our evaluation shows that DLIF achieves accurate and robust AIF estimation. By leveraging deep learning's ability to capture complex temporal dynamics and incorporating prior knowledge of typical AIF shapes through basis functions, DLIF provides a rapid, accurate, and entirely non-invasive alternative to traditional AIF measurement methods.
Beyond the LUMIR challenge: The pathway to foundational registration models
May 30, 2025



Medical image challenges have played a transformative role in advancing the field, catalyzing algorithmic innovation and establishing new performance standards across diverse clinical applications. Image registration, a foundational task in neuroimaging pipelines, has similarly benefited from the Learn2Reg initiative. Building on this foundation, we introduce the Large-scale Unsupervised Brain MRI Image Registration (LUMIR) challenge, a next-generation benchmark designed to assess and advance unsupervised brain MRI registration. Distinct from prior challenges that leveraged anatomical label maps for supervision, LUMIR removes this dependency by providing over 4,000 preprocessed T1-weighted brain MRIs for training without any label maps, encouraging biologically plausible deformation modeling through self-supervision. In addition to evaluating performance on 590 held-out test subjects, LUMIR introduces a rigorous suite of zero-shot generalization tasks, spanning out-of-domain imaging modalities (e.g., FLAIR, T2-weighted, T2*-weighted), disease populations (e.g., Alzheimer's disease), acquisition protocols (e.g., 9.4T MRI), and species (e.g., macaque brains). A total of 1,158 subjects and over 4,000 image pairs were included for evaluation. Performance was assessed using both segmentation-based metrics (Dice coefficient, 95th percentile Hausdorff distance) and landmark-based registration accuracy (target registration error). Across both in-domain and zero-shot tasks, deep learning-based methods consistently achieved state-of-the-art accuracy while producing anatomically plausible deformation fields. The top-performing deep learning-based models demonstrated diffeomorphic properties and inverse consistency, outperforming several leading optimization-based methods, and showing strong robustness to most domain shifts, the exception being a drop in performance on out-of-domain contrasts.
Pretraining Deformable Image Registration Networks with Random Images
May 30, 2025Recent advances in deep learning-based medical image registration have shown that training deep neural networks~(DNNs) does not necessarily require medical images. Previous work showed that DNNs trained on randomly generated images with carefully designed noise and contrast properties can still generalize well to unseen medical data. Building on this insight, we propose using registration between random images as a proxy task for pretraining a foundation model for image registration. Empirical results show that our pretraining strategy improves registration accuracy, reduces the amount of domain-specific data needed to achieve competitive performance, and accelerates convergence during downstream training, thereby enhancing computational efficiency.
Correlation Ratio for Unsupervised Learning of Multi-modal Deformable Registration
Apr 16, 2025In recent years, unsupervised learning for deformable image registration has been a major research focus. This approach involves training a registration network using pairs of moving and fixed images, along with a loss function that combines an image similarity measure and deformation regularization. For multi-modal image registration tasks, the correlation ratio has been a widely-used image similarity measure historically, yet it has been underexplored in current deep learning methods. Here, we propose a differentiable correlation ratio to use as a loss function for learning-based multi-modal deformable image registration. This approach extends the traditionally non-differentiable implementation of the correlation ratio by using the Parzen windowing approximation, enabling backpropagation with deep neural networks. We validated the proposed correlation ratio on a multi-modal neuroimaging dataset. In addition, we established a Bayesian training framework to study how the trade-off between the deformation regularizer and similarity measures, including mutual information and our proposed correlation ratio, affects the registration performance.
SITA: Structurally Imperceptible and Transferable Adversarial Attacks for Stylized Image Generation
Mar 25, 2025Image generation technology has brought significant advancements across various fields but has also raised concerns about data misuse and potential rights infringements, particularly with respect to creating visual artworks. Current methods aimed at safeguarding artworks often employ adversarial attacks. However, these methods face challenges such as poor transferability, high computational costs, and the introduction of noticeable noise, which compromises the aesthetic quality of the original artwork. To address these limitations, we propose a Structurally Imperceptible and Transferable Adversarial (SITA) attacks. SITA leverages a CLIP-based destylization loss, which decouples and disrupts the robust style representation of the image. This disruption hinders style extraction during stylized image generation, thereby impairing the overall stylization process. Importantly, SITA eliminates the need for a surrogate diffusion model, leading to significantly reduced computational overhead. The method's robust style feature disruption ensures high transferability across diverse models. Moreover, SITA introduces perturbations by embedding noise within the imperceptible structural details of the image. This approach effectively protects against style extraction without compromising the visual quality of the artwork. Extensive experiments demonstrate that SITA offers superior protection for artworks against unauthorized use in stylized generation. It significantly outperforms existing methods in terms of transferability, computational efficiency, and noise imperceptibility. Code is available at https://github.com/A-raniy-day/SITA.
NexusGS: Sparse View Synthesis with Epipolar Depth Priors in 3D Gaussian Splatting
Mar 24, 2025Neural Radiance Field (NeRF) and 3D Gaussian Splatting (3DGS) have noticeably advanced photo-realistic novel view synthesis using images from densely spaced camera viewpoints. However, these methods struggle in few-shot scenarios due to limited supervision. In this paper, we present NexusGS, a 3DGS-based approach that enhances novel view synthesis from sparse-view images by directly embedding depth information into point clouds, without relying on complex manual regularizations. Exploiting the inherent epipolar geometry of 3DGS, our method introduces a novel point cloud densification strategy that initializes 3DGS with a dense point cloud, reducing randomness in point placement while preventing over-smoothing and overfitting. Specifically, NexusGS comprises three key steps: Epipolar Depth Nexus, Flow-Resilient Depth Blending, and Flow-Filtered Depth Pruning. These steps leverage optical flow and camera poses to compute accurate depth maps, while mitigating the inaccuracies often associated with optical flow. By incorporating epipolar depth priors, NexusGS ensures reliable dense point cloud coverage and supports stable 3DGS training under sparse-view conditions. Experiments demonstrate that NexusGS significantly enhances depth accuracy and rendering quality, surpassing state-of-the-art methods by a considerable margin. Furthermore, we validate the superiority of our generated point clouds by substantially boosting the performance of competing methods. Project page: https://usmizuki.github.io/NexusGS/.