 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGTPT: Group-based Token Pruning Transformer for Efficient Human Pose Estimation
Jul 16, 2024



In recent years, 2D human pose estimation has made significant progress on public benchmarks. However, many of these approaches face challenges of less applicability in the industrial community due to the large number of parametric quantities and computational overhead. Efficient human pose estimation remains a hurdle, especially for whole-body pose estimation with numerous keypoints. While most current methods for efficient human pose estimation primarily rely on CNNs, we propose the Group-based Token Pruning Transformer (GTPT) that fully harnesses the advantages of the Transformer. GTPT alleviates the computational burden by gradually introducing keypoints in a coarse-to-fine manner. It minimizes the computation overhead while ensuring high performance. Besides, GTPT groups keypoint tokens and prunes visual tokens to improve model performance while reducing redundancy. We propose the Multi-Head Group Attention (MHGA) between different groups to achieve global interaction with little computational overhead. We conducted experiments on COCO and COCO-WholeBody. Compared to other methods, the experimental results show that GTPT can achieve higher performance with less computation, especially in whole-body with numerous keypoints.
PruningBench: A Comprehensive Benchmark of Structural Pruning
Jun 18, 2024



Structural pruning has emerged as a promising approach for producing more efficient models. Nevertheless, the community suffers from a lack of standardized benchmarks and metrics, leaving the progress in this area not fully comprehended. To fill this gap, we present the first comprehensive benchmark, termed \textit{PruningBench}, for structural pruning. PruningBench showcases the following three characteristics: 1) PruningBench employs a unified and consistent framework for evaluating the effectiveness of diverse structural pruning techniques; 2) PruningBench systematically evaluates 16 existing pruning methods, encompassing a wide array of models (e.g., CNNs and ViTs) and tasks (e.g., classification and detection); 3) PruningBench provides easily implementable interfaces to facilitate the implementation of future pruning methods, and enables the subsequent researchers to incorporate their work into our leaderboards. We provide an online pruning platform http://pruning.vipazoo.cn for customizing pruning tasks and reproducing all results in this paper. Codes will be made publicly available.
Direct Alignment of Language Models via Quality-Aware Self-Refinement
May 31, 2024
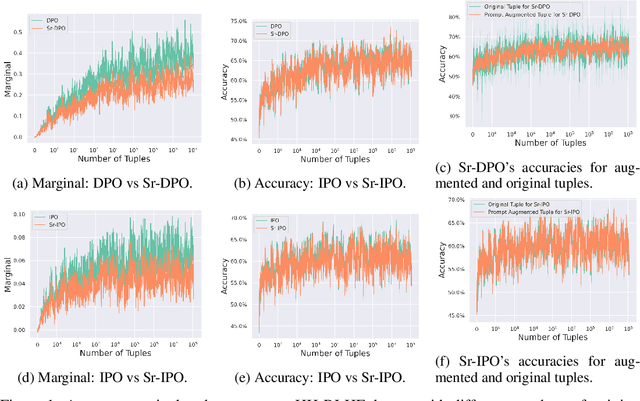
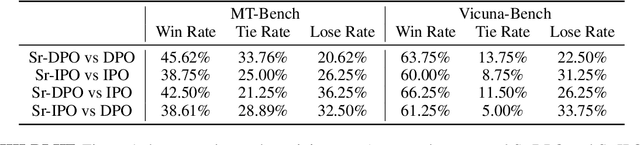
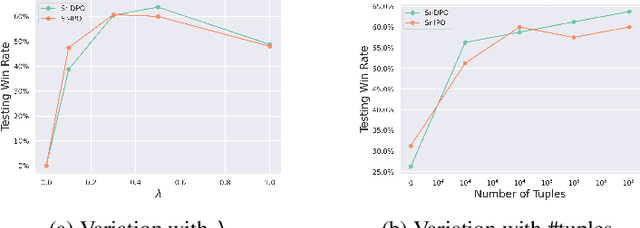
Reinforcement Learning from Human Feedback (RLHF) has been commonly used to align the behaviors of Large Language Models (LLMs) with human preferences. Recently, a popular alternative is Direct Policy Optimization (DPO), which replaces an LLM-based reward model with the policy itself, thus obviating the need for extra memory and training time to learn the reward model. However, DPO does not consider the relative qualities of the positive and negative responses, and can lead to sub-optimal training outcomes. To alleviate this problem, we investigate the use of intrinsic knowledge within the on-the-fly fine-tuning LLM to obtain relative qualities and help to refine the loss function. Specifically, we leverage the knowledge of the LLM to design a refinement function to estimate the quality of both the positive and negative responses. We show that the constructed refinement function can help self-refine the loss function under mild assumptions. The refinement function is integrated into DPO and its variant Identity Policy Optimization (IPO). Experiments across various evaluators indicate that they can improve the performance of the fine-tuned models over DPO and IPO.
Boosting X-formers with Structured Matrix for Long Sequence Time Series Forecasting
May 22, 2024Transformer-based models for long sequence time series forecasting (LSTF) problems have gained significant attention due to their exceptional forecasting precision. As the cornerstone of these models, the self-attention mechanism poses a challenge to efficient training and inference due to its quadratic time complexity. In this article, we propose a novel architectural design for Transformer-based models in LSTF, leveraging a substitution framework that incorporates Surrogate Attention Blocks and Surrogate FFN Blocks. The framework aims to boost any well-designed model's efficiency without sacrificing its accuracy. We further establish the equivalence of the Surrogate Attention Block to the self-attention mechanism in terms of both expressiveness and trainability. Through extensive experiments encompassing nine Transformer-based models across five time series tasks, we observe an average performance improvement of 9.45% while achieving a significant reduction in model size by 46%
MLP: Motion Label Prior for Temporal Sentence Localization in Untrimmed 3D Human Motions
Apr 21, 2024In this paper, we address the unexplored question of temporal sentence localization in human motions (TSLM), aiming to locate a target moment from a 3D human motion that semantically corresponds to a text query. Considering that 3D human motions are captured using specialized motion capture devices, motions with only a few joints lack complex scene information like objects and lighting. Due to this character, motion data has low contextual richness and semantic ambiguity between frames, which limits the accuracy of predictions made by current video localization frameworks extended to TSLM to only a rough level. To refine this, we devise two novel label-prior-assisted training schemes: one embed prior knowledge of foreground and background to highlight the localization chances of target moments, and the other forces the originally rough predictions to overlap with the more accurate predictions obtained from the flipped start/end prior label sequences during recovery training. We show that injecting label-prior knowledge into the model is crucial for improving performance at high IoU. In our constructed TSLM benchmark, our model termed MLP achieves a recall of 44.13 at IoU@0.7 on the BABEL dataset and 71.17 on HumanML3D (Restore), outperforming prior works. Finally, we showcase the potential of our approach in corpus-level moment retrieval. Our source code is openly accessible at https://github.com/eanson023/mlp.
On the Concept Trustworthiness in Concept Bottleneck Models
Mar 21, 2024



Concept Bottleneck Models (CBMs), which break down the reasoning process into the input-to-concept mapping and the concept-to-label prediction, have garnered significant attention due to their remarkable interpretability achieved by the interpretable concept bottleneck. However, despite the transparency of the concept-to-label prediction, the mapping from the input to the intermediate concept remains a black box, giving rise to concerns about the trustworthiness of the learned concepts (i.e., these concepts may be predicted based on spurious cues). The issue of concept untrustworthiness greatly hampers the interpretability of CBMs, thereby hindering their further advancement. To conduct a comprehensive analysis on this issue, in this study we establish a benchmark to assess the trustworthiness of concepts in CBMs. A pioneering metric, referred to as concept trustworthiness score, is proposed to gauge whether the concepts are derived from relevant regions. Additionally, an enhanced CBM is introduced, enabling concept predictions to be made specifically from distinct parts of the feature map, thereby facilitating the exploration of their related regions. Besides, we introduce three modules, namely the cross-layer alignment (CLA) module, the cross-image alignment (CIA) module, and the prediction alignment (PA) module, to further enhance the concept trustworthiness within the elaborated CBM. The experiments on five datasets across ten architectures demonstrate that without using any concept localization annotations during training, our model improves the concept trustworthiness by a large margin, meanwhile achieving superior accuracy to the state-of-the-arts. Our code is available at https://github.com/hqhQAQ/ProtoCBM.
Training-Free Pretrained Model Merging
Mar 15, 2024



Recently, model merging techniques have surfaced as a solution to combine multiple single-talent models into a single multi-talent model. However, previous endeavors in this field have either necessitated additional training or fine-tuning processes, or require that the models possess the same pre-trained initialization. In this work, we identify a common drawback in prior works w.r.t. the inconsistency of unit similarity in the weight space and the activation space. To address this inconsistency, we propose an innovative model merging framework, coined as merging under dual-space constraints (MuDSC). Specifically, instead of solely maximizing the objective of a single space, we advocate for the exploration of permutation matrices situated in a region with a unified high similarity in the dual space, achieved through the linear combination of activation and weight similarity matrices. In order to enhance usability, we have also incorporated adaptations for group structure, including Multi-Head Attention and Group Normalization. Comprehensive experimental comparisons demonstrate that MuDSC can significantly boost the performance of merged models with various task combinations and architectures. Furthermore, the visualization of the merged model within the multi-task loss landscape reveals that MuDSC enables the merged model to reside in the overlapping segment, featuring a unified lower loss for each task. Our code is publicly available at https://github.com/zju-vipa/training_free_model_merging.
Automatic driving lane change safety prediction model based on LSTM
Feb 28, 2024



Autonomous driving technology can improve traffic safety and reduce traffic accidents. In addition, it improves traffic flow, reduces congestion, saves energy and increases travel efficiency. In the relatively mature automatic driving technology, the automatic driving function is divided into several modules: perception, decision-making, planning and control, and a reasonable division of labor can improve the stability of the system. Therefore, autonomous vehicles need to have the ability to predict the trajectory of surrounding vehicles in order to make reasonable decision planning and safety measures to improve driving safety. By using deep learning method, a safety-sensitive deep learning model based on short term memory (LSTM) network is proposed. This model can alleviate the shortcomings of current automatic driving trajectory planning, and the output trajectory not only ensures high accuracy but also improves safety. The cell state simulation algorithm simulates the trackability of the trajectory generated by this model. The research results show that compared with the traditional model-based method, the trajectory prediction method based on LSTM network has obvious advantages in predicting the trajectory in the long time domain. The intention recognition module considering interactive information has higher prediction and accuracy, and the algorithm results show that the trajectory is very smooth based on the premise of safe prediction and efficient lane change. And autonomous vehicles can efficiently and safely complete lane changes.
Construction and application of artificial intelligence crowdsourcing map based on multi-track GPS data
Feb 24, 2024



In recent years, the rapid development of high-precision map technology combined with artificial intelligence has ushered in a new development opportunity in the field of intelligent vehicles. High-precision map technology is an important guarantee for intelligent vehicles to achieve autonomous driving. However, due to the lack of research on high-precision map technology, it is difficult to rationally use this technology in the field of intelligent vehicles. Therefore, relevant researchers studied a fast and effective algorithm to generate high-precision GPS data from a large number of low-precision GPS trajectory data fusion, and generated several key data points to simplify the description of GPS trajectory, and realized the "crowdsourced update" model based on a large number of social vehicles for map data collection came into being. This kind of algorithm has the important significance to improve the data accuracy, reduce the measurement cost and reduce the data storage space. On this basis, this paper analyzes the implementation form of crowdsourcing map, so as to improve the various information data in the high-precision map according to the actual situation, and promote the high-precision map can be reasonably applied to the intelligent car.
EL-VIT: Probing Vision Transformer with Interactive Visualization
Jan 23, 2024



Nowadays, Vision Transformer (ViT) is widely utilized in various computer vision tasks, owing to its unique self-attention mechanism. However, the model architecture of ViT is complex and often challenging to comprehend, leading to a steep learning curve. ViT developers and users frequently encounter difficulties in interpreting its inner workings. Therefore, a visualization system is needed to assist ViT users in understanding its functionality. This paper introduces EL-VIT, an interactive visual analytics system designed to probe the Vision Transformer and facilitate a better understanding of its operations. The system consists of four layers of visualization views. The first three layers include model overview, knowledge background graph, and model detail view. These three layers elucidate the operation process of ViT from three perspectives: the overall model architecture, detailed explanation, and mathematical operations, enabling users to understand the underlying principles and the transition process between layers. The fourth interpretation view helps ViT users and experts gain a deeper understanding by calculating the cosine similarity between patches. Our two usage scenarios demonstrate the effectiveness and usability of EL-VIT in helping ViT users understand the working mechanism of ViT.