 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARNOLD: A Benchmark for Language-Grounded Task Learning With Continuous States in Realistic 3D Scenes
Apr 09, 2023



Understanding the continuous states of objects is essential for task learning and planning in the real world. However, most existing task learning benchmarks assume discrete(e.g., binary) object goal states, which poses challenges for the learning of complex tasks and transferring learned policy from simulated environments to the real world. Furthermore, state discretization limits a robot's ability to follow human instructions based on the grounding of actions and states. To tackle these challenges, we present ARNOLD, a benchmark that evaluates language-grounded task learning with continuous states in realistic 3D scenes. ARNOLD is comprised of 8 language-conditioned tasks that involve understanding object states and learning policies for continuous goals. To promote language-instructed learning, we provide expert demonstrations with template-generated language descriptions. We assess task performance by utilizing the latest language-conditioned policy learning models. Our results indicate that current models for language-conditioned manipulations continue to experience significant challenges in novel goal-state generalizations, scene generalizations, and object generalizations. These findings highlight the need to develop new algorithms that address this gap and underscore the potential for further research in this area. See our project page at: https://arnold-benchmark.github.io
OpenD: A Benchmark for Language-Driven Door and Drawer Opening
Dec 10, 2022



We introduce OPEND, a benchmark for learning how to use a hand to open cabinet doors or drawers in a photo-realistic and physics-reliable simulation environment driven by language instruction. To solve the task, we propose a multi-step planner composed of a deep neural network and rule-base controllers. The network is utilized to capture spatial relationships from images and understand semantic meaning from language instructions. Controllers efficiently execute the plan based on the spatial and semantic understanding. We evaluate our system by measuring its zero-shot performance in test data set. Experimental results demonstrate the effectiveness of decision planning by our multi-step planner for different hands, while suggesting that there is significant room for developing better models to address the challenge brought by language understanding, spatial reasoning, and long-term manipulation. We will release OPEND and host challenges to promote future research in this area.
Alignment-guided Temporal Attention for Video Action Recognition
Sep 30, 2022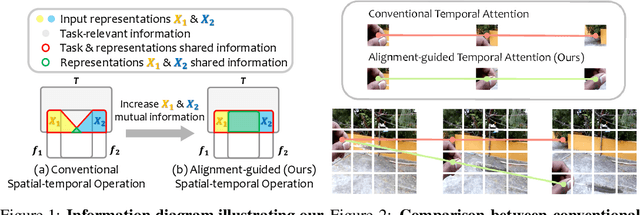
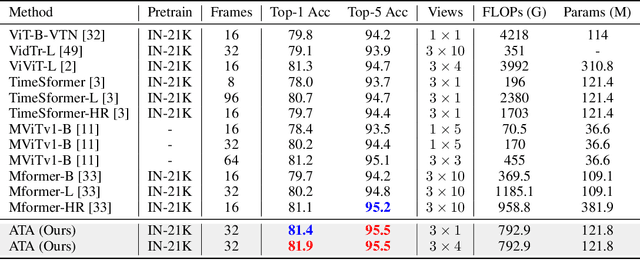
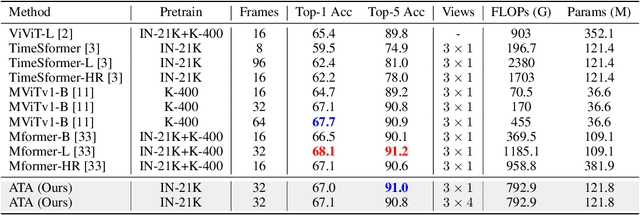
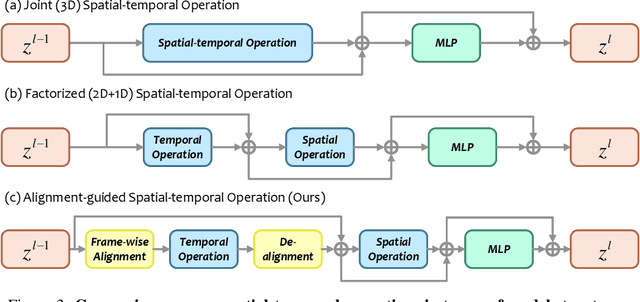
Temporal modeling is crucial for various video learning tasks. Most recent approaches employ either factorized (2D+1D) or joint (3D) spatial-temporal operations to extract temporal contexts from the input frames. While the former is more efficient in computation, the latter often obtains better performance. In this paper, we attribute this to a dilemma between the sufficiency and the efficiency of interactions among various positions in different frames. These interactions affect the extraction of task-relevant information shared among frames. To resolve this issue, we prove that frame-by-frame alignments have the potential to increase the mutual information between frame representations, thereby including more task-relevant information to boost effectiveness. Then we propose Alignment-guided Temporal Attention (ATA) to extend 1-dimensional temporal attention with parameter-free patch-level alignments between neighboring frames. It can act as a general plug-in for image backbones to conduct the action recognition task without any model-specific design. Extensive experiments on multiple benchmarks demonstrate the superiority and generality of our module.
VRKitchen2.0-IndoorKit: A Tutorial for Augmented Indoor Scene Building in Omniverse
Jun 23, 2022

With the recent progress of simulations by 3D modeling software and game engines, many researchers have focused on Embodied AI tasks in the virtual environment. However, the research community lacks a platform that can easily serve both indoor scene synthesis and model benchmarking with various algorithms. Meanwhile, computer graphics-related tasks need a toolkit for implementing advanced synthesizing techniques. To facilitate the study of indoor scene building methods and their potential robotics applications, we introduce INDOORKIT: a built-in toolkit for NVIDIA OMNIVERSE that provides flexible pipelines for indoor scene building, scene randomizing, and animation controls. Besides, combining Python coding in the animation software INDOORKIT assists researchers in creating real-time training and controlling avatars and robotics. The source code for this toolkit is available at https://github.com/realvcla/VRKitchen2.0-Tutorial, and the tutorial along with the toolkit is available at https://vrkitchen20-tutorial.readthedocs.io/en/
Semantic-aligned Fusion Transformer for One-shot Object Detection
Mar 20, 2022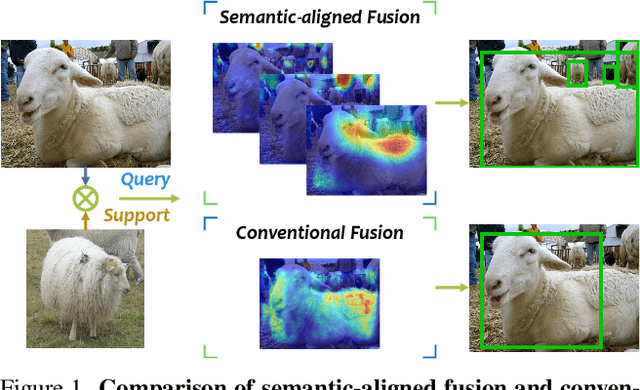


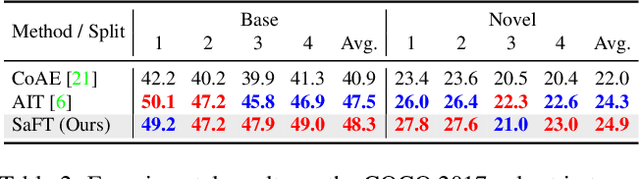
One-shot object detection aims at detecting novel objects according to merely one given instance. With extreme data scarcity, current approaches explore various feature fusions to obtain directly transferable meta-knowledge. Yet, their performances are often unsatisfactory. In this paper, we attribute this to inappropriate correlation methods that misalign query-support semantics by overlooking spatial structures and scale variances. Upon analysis, we leverage the attention mechanism and propose a simple but effective architecture named Semantic-aligned Fusion Transformer (SaFT) to resolve these issues. Specifically, we equip SaFT with a vertical fusion module (VFM) for cross-scale semantic enhancement and a horizontal fusion module (HFM) for cross-sample feature fusion. Together, they broaden the vision for each feature point from the support to a whole augmented feature pyramid from the query, facilitating semantic-aligned associations. Extensive experiments on multiple benchmarks demonstrate the superiority of our framework. Without fine-tuning on novel classes, it brings significant performance gains to one-stage baselines, lifting state-of-the-art results to a higher level.
Triangular Character Animation Sampling with Motion, Emotion, and Relation
Mar 09, 2022
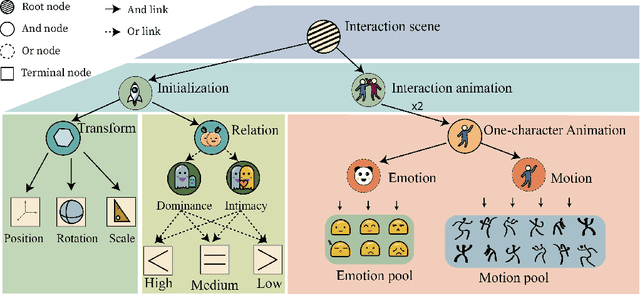

Dramatic progress has been made in animating individual characters. However, we still lack automatic control over activities between characters, especially those involving interactions. In this paper, we present a novel energy-based framework to sample and synthesize animations by associating the characters' body motions, facial expressions, and social relations. We propose a Spatial-Temporal And-Or graph (ST-AOG), a stochastic grammar model, to encode the contextual relationship between motion, emotion, and relation, forming a triangle in a conditional random field. We train our model from a labeled dataset of two-character interactions. Experiments demonstrate that our method can recognize the social relation between two characters and sample new scenes of vivid motion and emotion using Markov Chain Monte Carlo (MCMC) given the social relation. Thus, our method can provide animators with an automatic way to generate 3D character animations, help synthesize interactions between Non-Player Characters (NPCs), and enhance machine emotion intelligence (EQ) in virtual reality (VR).
Learning to Act with Affordance-Aware Multimodal Neural SLAM
Feb 04, 2022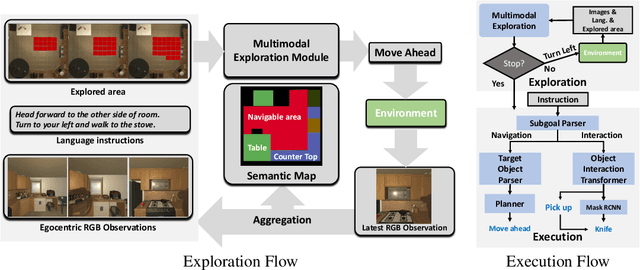

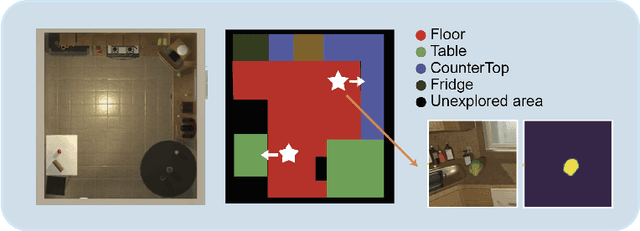
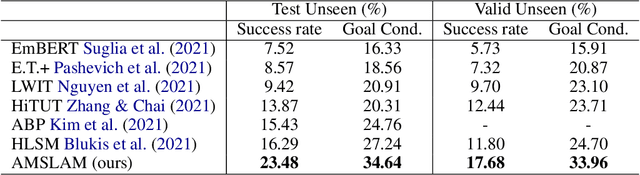
Recent years have witnessed an emerging paradigm shift toward embodied artificial intelligence, in which an agent must learn to solve challenging tasks by interacting with its environment. There are several challenges in solving embodied multimodal tasks, including long-horizon planning, vision-and-language grounding, and efficient exploration. We focus on a critical bottleneck, namely the performance of planning and navigation. To tackle this challenge, we propose a Neural SLAM approach that, for the first time, utilizes several modalities for exploration, predicts an affordance-aware semantic map, and plans over it at the same time. This significantly improves exploration efficiency, leads to robust long-horizon planning, and enables effective vision-and-language grounding. With the proposed Affordance-aware Multimodal Neural SLAM (AMSLAM) approach, we obtain more than $40\%$ improvement over prior published work on the ALFRED benchmark and set a new state-of-the-art generalization performance at a success rate of $23.48\%$ on the test unseen scenes.
ValueNet: A New Dataset for Human Value Driven Dialogue System
Dec 12, 2021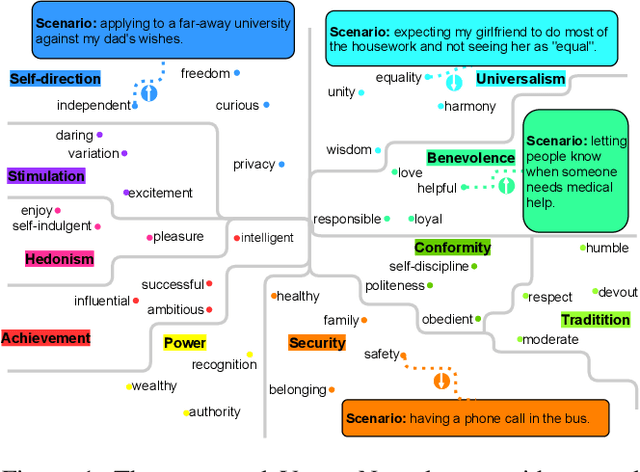
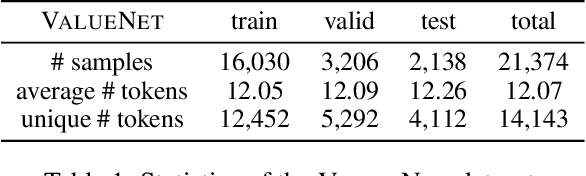
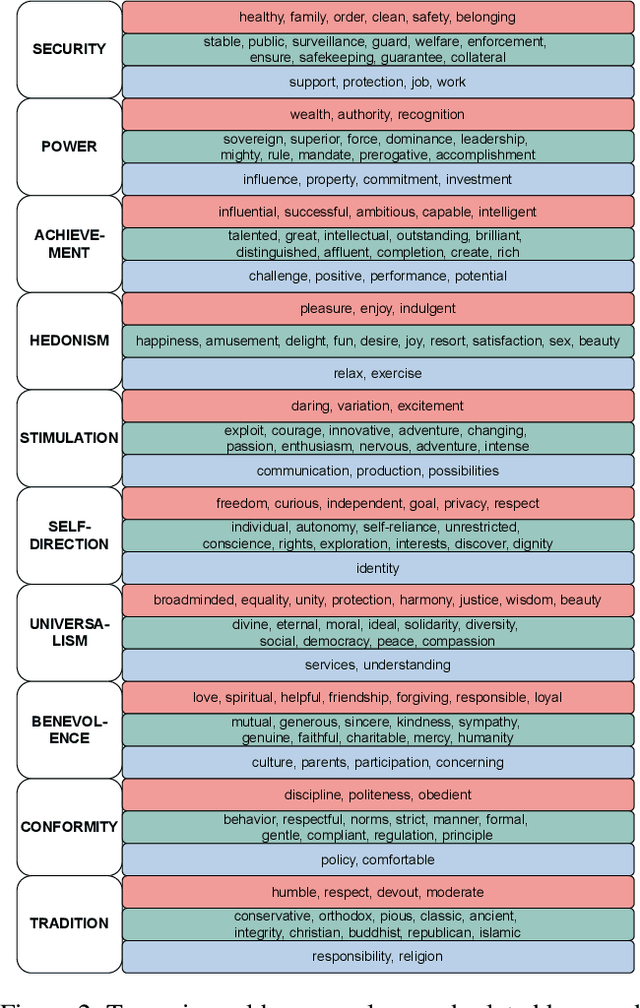
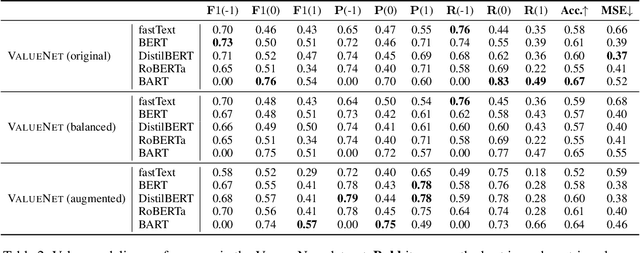
Building a socially intelligent agent involves many challenges, one of which is to teach the agent to speak guided by its value like a human. However, value-driven chatbots are still understudied in the area of dialogue systems. Most existing datasets focus on commonsense reasoning or social norm modeling. In this work, we present a new large-scale human value dataset called ValueNet, which contains human attitudes on 21,374 text scenarios. The dataset is organized in ten dimensions that conform to the basic human value theory in intercultural research. We further develop a Transformer-based value regression model on ValueNet to learn the utility distribution. Comprehensive empirical results show that the learned value model could benefit a wide range of dialogue tasks. For example, by teaching a generative agent with reinforcement learning and the rewards from the value model, our method attains state-of-the-art performance on the personalized dialog generation dataset: Persona-Chat. With values as additional features, existing emotion recognition models enable capturing rich human emotions in the context, which further improves the empathetic response generation performance in the EmpatheticDialogues dataset. To the best of our knowledge, ValueNet is the first large-scale text dataset for human value modeling, and we are the first one trying to incorporate a value model into emotionally intelligent dialogue systems. The dataset is available at https://liang-qiu.github.io/ValueNet/.
Learning from the Tangram to Solve Mini Visual Tasks
Dec 12, 2021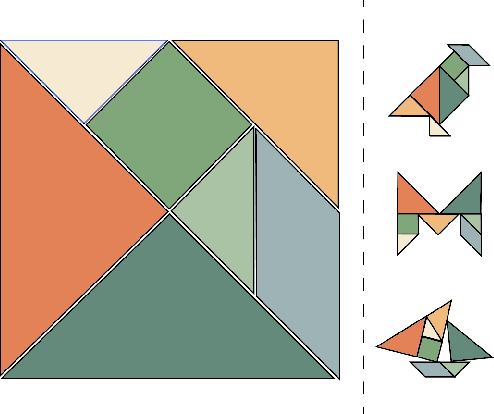
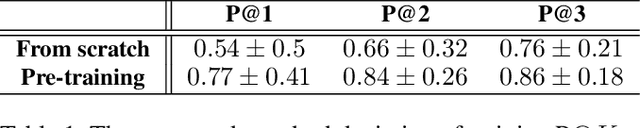
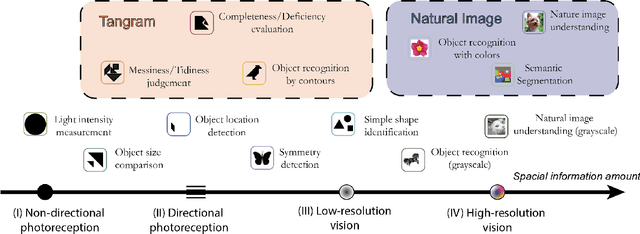
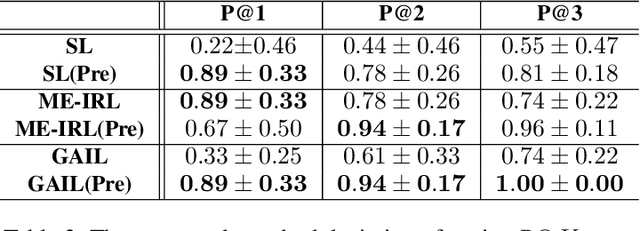
Current pre-training methods in computer vision focus on natural images in the daily-life context. However, abstract diagrams such as icons and symbols are common and important in the real world. This work is inspired by Tangram, a game that requires replicating an abstract pattern from seven dissected shapes. By recording human experience in solving tangram puzzles, we present the Tangram dataset and show that a pre-trained neural model on the Tangram helps solve some mini visual tasks based on low-resolution vision. Extensive experiments demonstrate that our proposed method generates intelligent solutions for aesthetic tasks such as folding clothes and evaluating room layouts. The pre-trained feature extractor can facilitate the convergence of few-shot learning tasks on human handwriting and improve the accuracy in identifying icons by their contours. The Tangram dataset is available at https://github.com/yizhouzhao/Tangram.
LUMINOUS: Indoor Scene Generation for Embodied AI Challenges
Nov 10, 2021

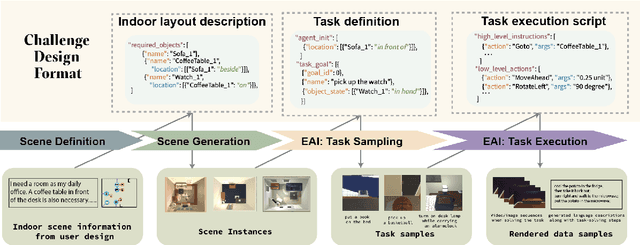
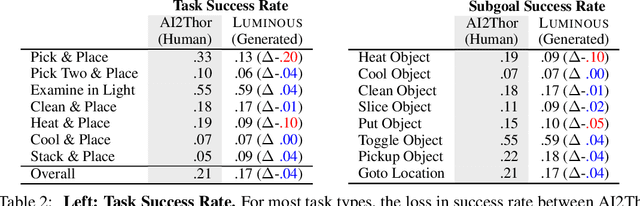
Learning-based methods for training embodied agents typically require a large number of high-quality scenes that contain realistic layouts and support meaningful interactions. However, current simulators for Embodied AI (EAI) challenges only provide simulated indoor scenes with a limited number of layouts. This paper presents Luminous, the first research framework that employs state-of-the-art indoor scene synthesis algorithms to generate large-scale simulated scenes for Embodied AI challenges. Further, we automatically and quantitatively evaluate the quality of generated indoor scenes via their ability to support complex household tasks. Luminous incorporates a novel scene generation algorithm (Constrained Stochastic Scene Generation (CSSG)), which achieves competitive performance with human-designed scenes. Within Luminous, the EAI task executor, task instruction generation module, and video rendering toolkit can collectively generate a massive multimodal dataset of new scenes for the training and evaluation of Embodied AI agents. Extensive experimental results demonstrate the effectiveness of the data generated by Luminous, enabling the comprehensive assessment of embodied agents on generalization and robustness.