 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning by Turning: Neural Architecture Aware Optimisation
Feb 14, 2021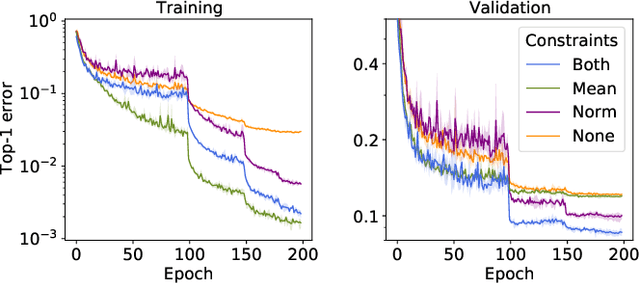

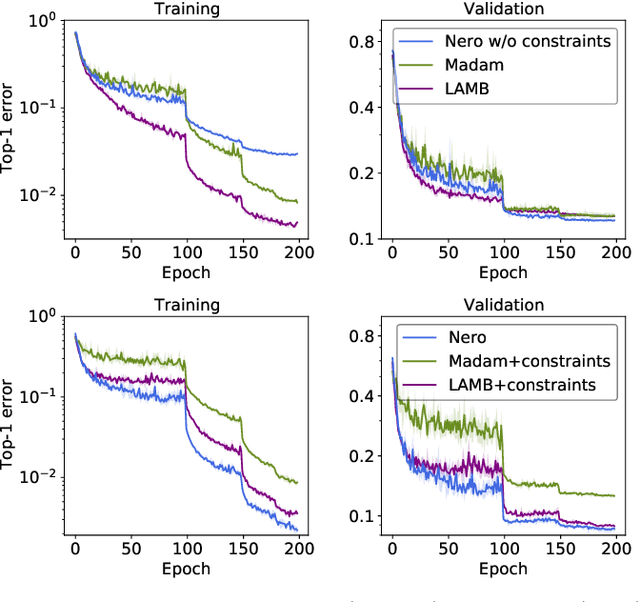
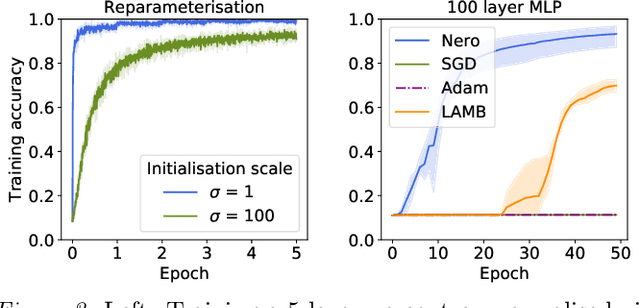
Descent methods for deep networks are notoriously capricious: they require careful tuning of step size, momentum and weight decay, and which method will work best on a new benchmark is a priori unclear. To address this problem, this paper conducts a combined study of neural architecture and optimisation, leading to a new optimiser called Nero: the neuronal rotator. Nero trains reliably without momentum or weight decay, works in situations where Adam and SGD fail, and requires little to no learning rate tuning. Also, Nero's memory footprint is ~ square root that of Adam or LAMB. Nero combines two ideas: (1) projected gradient descent over the space of balanced networks; (2) neuron-specific updates, where the step size sets the angle through which each neuron's hyperplane turns. The paper concludes by discussing how this geometric connection between architecture and optimisation may impact theories of generalisation in deep learning.
Disentangling Observed Causal Effects from Latent Confounders using Method of Moments
Jan 17, 2021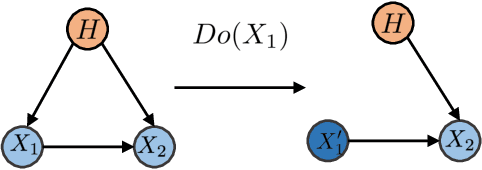
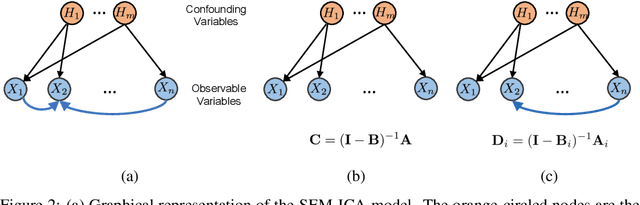
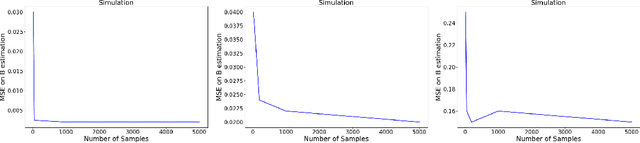
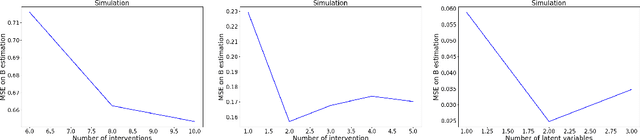
Discovering the complete set of causal relations among a group of variables is a challenging unsupervised learning problem. Often, this challenge is compounded by the fact that there are latent or hidden confounders. When only observational data is available, the problem is ill-posed, i.e. the causal relationships are non-identifiable unless strong modeling assumptions are made. When interventions are available, we provide guarantees on identifiability and learnability under mild assumptions. We assume a linear structural equation model (SEM) with independent latent factors and directed acyclic graph (DAG) relationships among the observables. Since the latent variable inference is based on independent component analysis (ICA), we call this model SEM-ICA. We use the method of moments principle to establish model identifiability. We develop efficient algorithms based on coupled tensor decomposition with linear constraints to obtain scalable and guaranteed solutions. Thus, we provide a principled approach to tackling the joint problem of causal discovery and latent variable inference.
Neural-Swarm2: Planning and Control of Heterogeneous Multirotor Swarms using Learned Interactions
Dec 10, 2020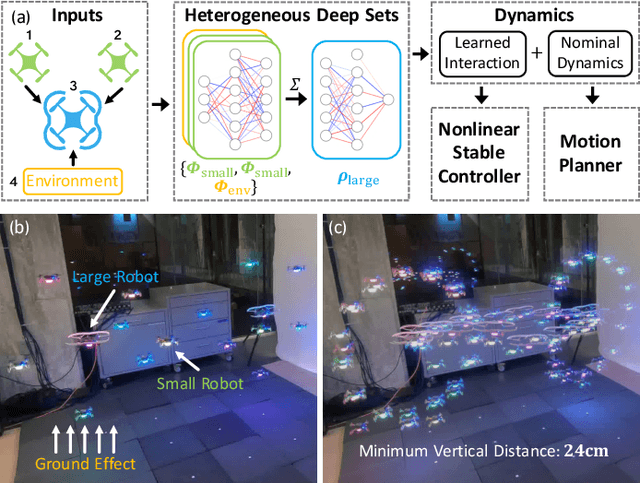
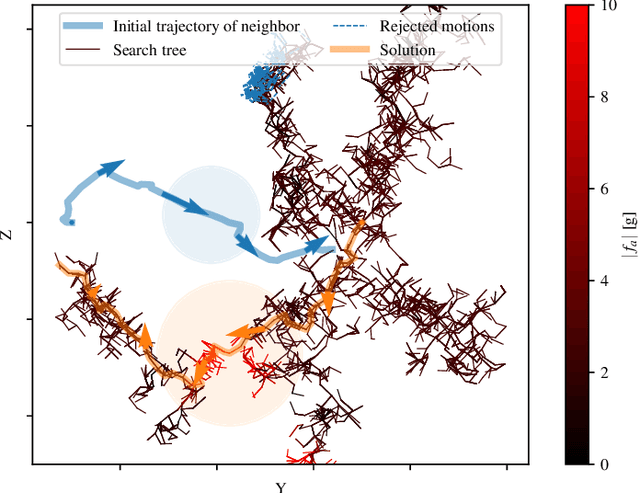
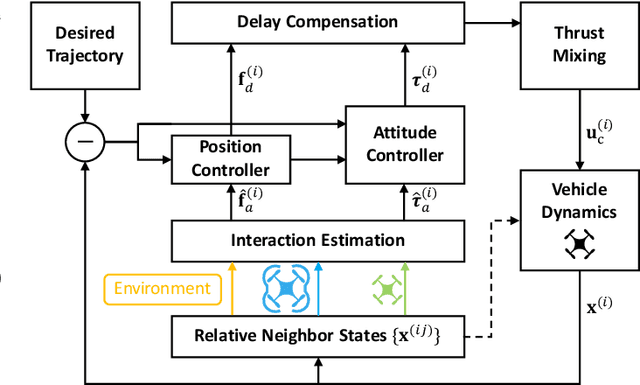
We present Neural-Swarm2, a learning-based method for motion planning and control that allows heterogeneous multirotors in a swarm to safely fly in close proximity. Such operation for drones is challenging due to complex aerodynamic interaction forces, such as downwash generated by nearby drones and ground effect. Conventional planning and control methods neglect capturing these interaction forces, resulting in sparse swarm configuration during flight. Our approach combines a physics-based nominal dynamics model with learned Deep Neural Networks (DNNs) with strong Lipschitz properties. We evolve two techniques to accurately predict the aerodynamic interactions between heterogeneous multirotors: i) spectral normalization for stability and generalization guarantees of unseen data and ii) heterogeneous deep sets for supporting any number of heterogeneous neighbors in a permutation-invariant manner without reducing expressiveness. The learned residual dynamics benefit both the proposed interaction-aware multi-robot motion planning and the nonlinear tracking control designs because the learned interaction forces reduce the modelling errors. Experimental results demonstrate that Neural-Swarm2 is able to generalize to larger swarms beyond training cases and significantly outperforms a baseline nonlinear tracking controller with up to three times reduction in worst-case tracking errors.
Task Programming: Learning Data Efficient Behavior Representations
Nov 27, 2020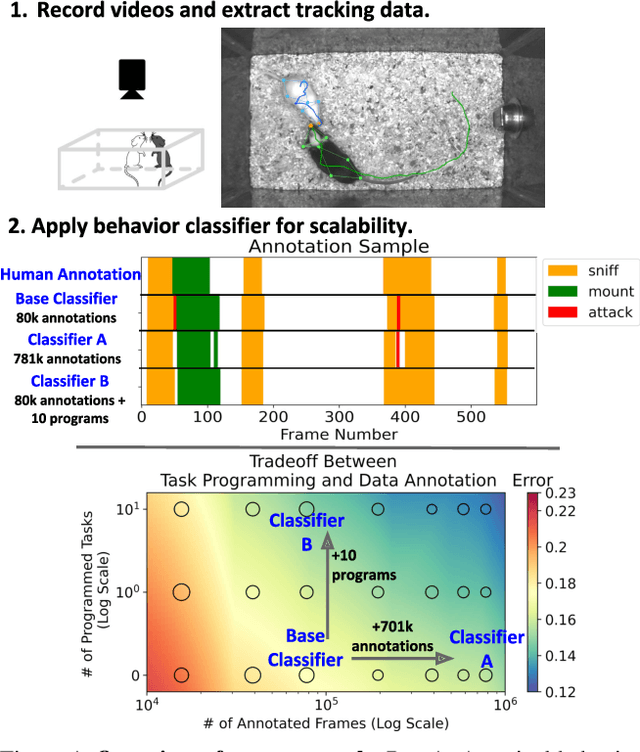
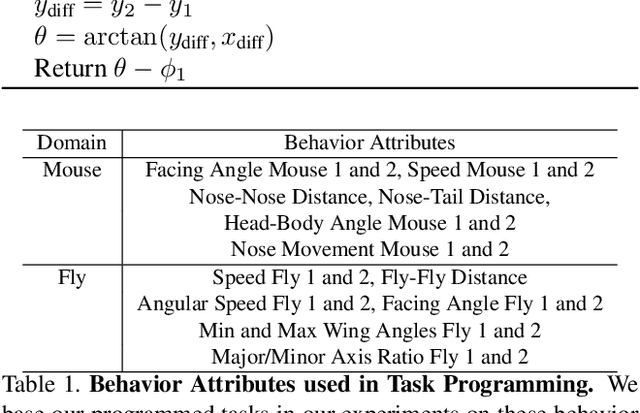
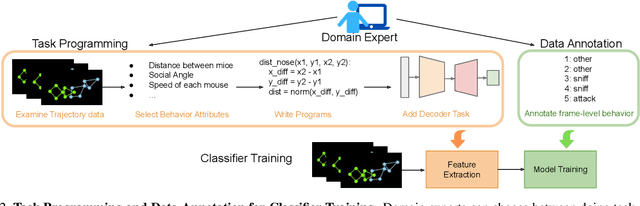
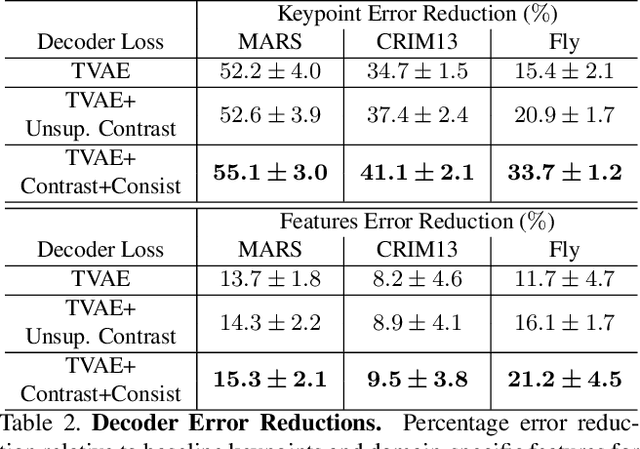
Specialized domain knowledge is often necessary to accurately annotate training sets for in-depth analysis, but can be burdensome and time-consuming to acquire from domain experts. This issue arises prominently in automated behavior analysis, in which agent movements or actions of interest are detected from video tracking data. To reduce annotation effort, we present TREBA: a method to learn annotation-sample efficient trajectory embedding for behavior analysis, based on multi-task self-supervised learning. The tasks in our method can be efficiently engineered by domain experts through a process we call "task programming", which uses programs to explicitly encode structured knowledge from domain experts. Total domain expert effort can be reduced by exchanging data annotation time for the construction of a small number of programmed tasks. We evaluate this trade-off using data from behavioral neuroscience, in which specialized domain knowledge is used to identify behaviors. We present experimental results in three datasets across two domains: mice and fruit flies. Using embeddings from TREBA, we reduce annotation burden by up to a factor of 10 without compromising accuracy compared to state-of-the-art features. Our results thus suggest that task programming can be an effective way to reduce annotation effort for domain experts.
Towards Robust Data-Driven Control Synthesis for Nonlinear Systems with Actuation Uncertainty
Nov 21, 2020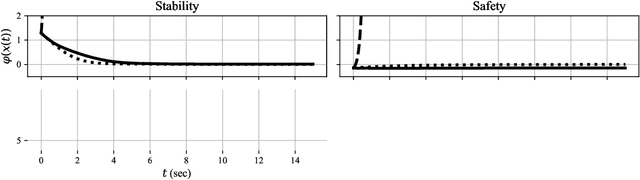
Modern nonlinear control theory seeks to endow systems with properties such as stability and safety, and has been deployed successfully across various domains. Despite this success, model uncertainty remains a significant challenge in ensuring that model-based controllers transfer to real world systems. This paper develops a data-driven approach to robust control synthesis in the presence of model uncertainty using Control Certificate Functions (CCFs), resulting in a convex optimization based controller for achieving properties like stability and safety. An important benefit of our framework is nuanced data-dependent guarantees, which in principle can yield sample-efficient data collection approaches that need not fully determine the input-to-state relationship. This work serves as a starting point for addressing important questions at the intersection of nonlinear control theory and non-parametric learning, both theoretical and in application. We validate the proposed method in simulation with an inverted pendulum in multiple experimental configurations.
On the Benefits of Early Fusion in Multimodal Representation Learning
Nov 14, 2020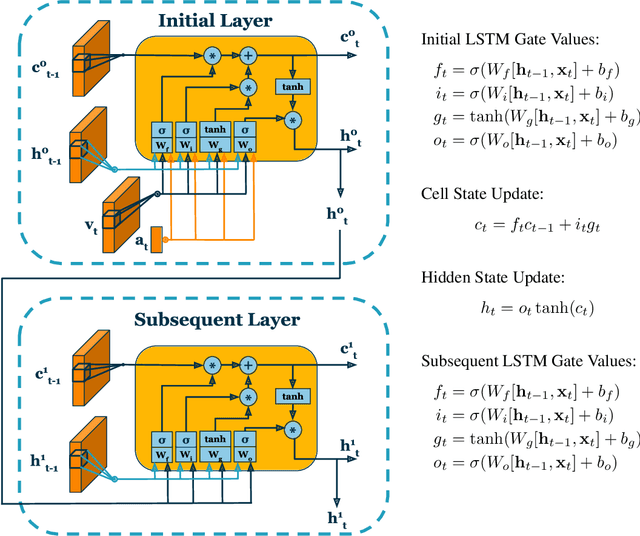
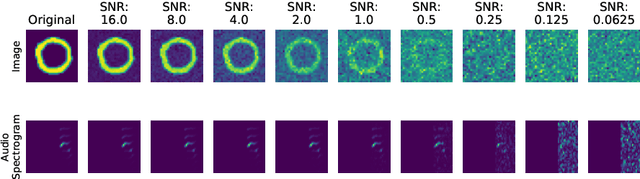
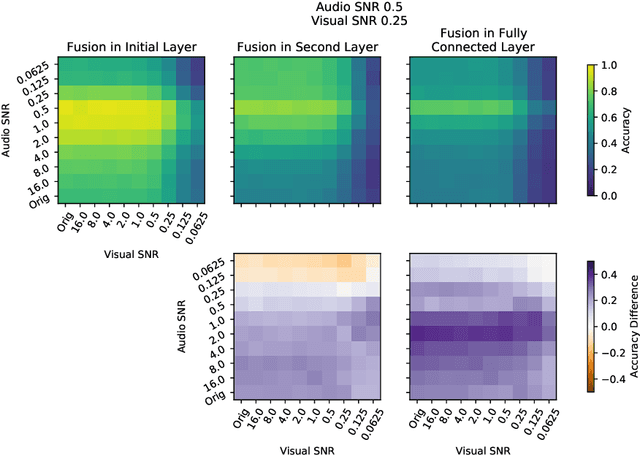
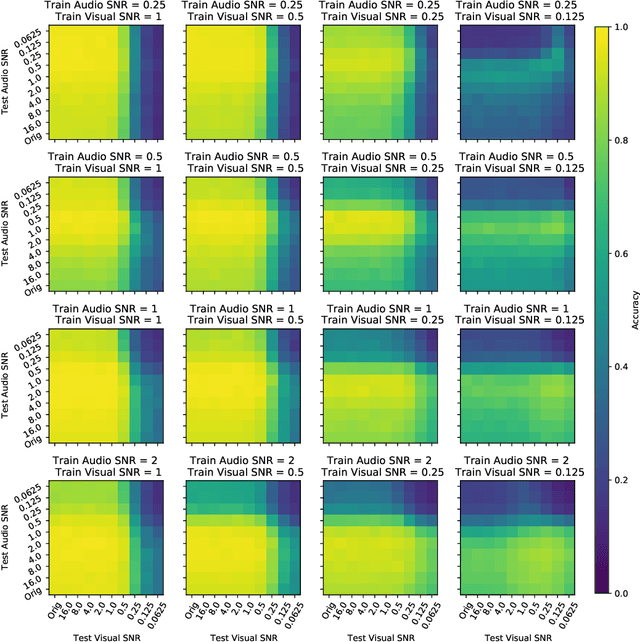
Intelligently reasoning about the world often requires integrating data from multiple modalities, as any individual modality may contain unreliable or incomplete information. Prior work in multimodal learning fuses input modalities only after significant independent processing. On the other hand, the brain performs multimodal processing almost immediately. This divide between conventional multimodal learning and neuroscience suggests that a detailed study of early multimodal fusion could improve artificial multimodal representations. To facilitate the study of early multimodal fusion, we create a convolutional LSTM network architecture that simultaneously processes both audio and visual inputs, and allows us to select the layer at which audio and visual information combines. Our results demonstrate that immediate fusion of audio and visual inputs in the initial C-LSTM layer results in higher performing networks that are more robust to the addition of white noise in both audio and visual inputs.
Machine Learning Based Path Planning for Improved Rover Navigation (Pre-Print Version)
Nov 11, 2020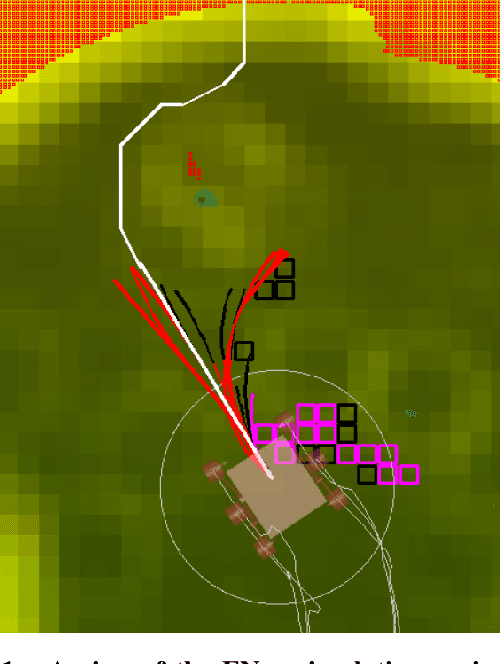
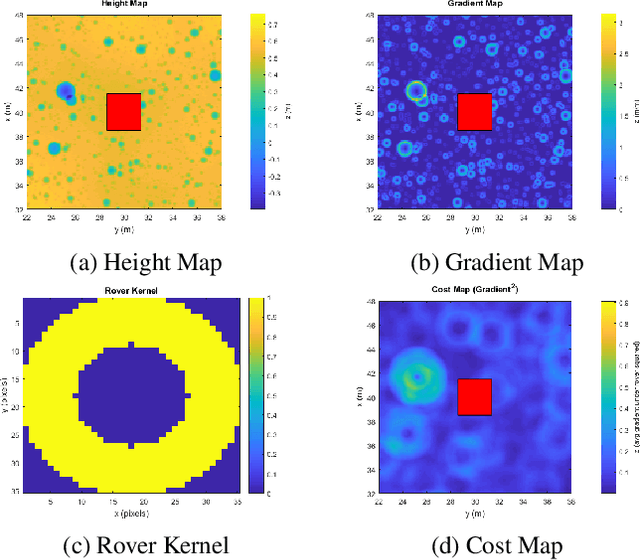

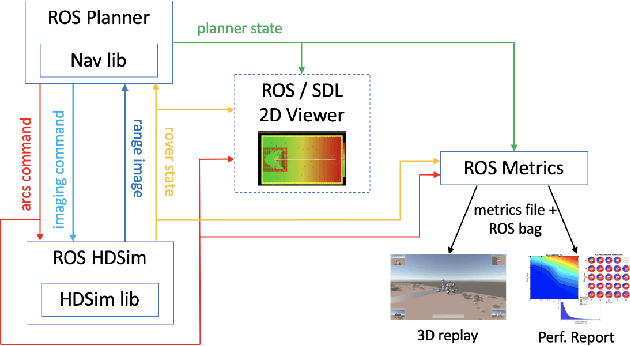
Enhanced AutoNav (ENav), the baseline surface navigation software for NASA's Perseverance rover, sorts a list of candidate paths for the rover to traverse, then uses the Approximate Clearance Evaluation (ACE) algorithm to evaluate whether the most highly ranked paths are safe. ACE is crucial for maintaining the safety of the rover, but is computationally expensive. If the most promising candidates in the list of paths are all found to be infeasible, ENav must continue to search the list and run time-consuming ACE evaluations until a feasible path is found. In this paper, we present two heuristics that, given a terrain heightmap around the rover, produce cost estimates that more effectively rank the candidate paths before ACE evaluation. The first heuristic uses Sobel operators and convolution to incorporate the cost of traversing high-gradient terrain. The second heuristic uses a machine learning (ML) model to predict areas that will be deemed untraversable by ACE. We used physics simulations to collect training data for the ML model and to run Monte Carlo trials to quantify navigation performance across a variety of terrains with various slopes and rock distributions. Compared to ENav's baseline performance, integrating the heuristics can lead to a significant reduction in ACE evaluations and average computation time per planning cycle, increase path efficiency, and maintain or improve the rate of successful traverses. This strategy of targeting specific bottlenecks with ML while maintaining the original ACE safety checks provides an example of how ML can be infused into planetary science missions and other safety-critical software.
ROIAL: Region of Interest Active Learning for Characterizing Exoskeleton Gait Preference Landscapes
Nov 09, 2020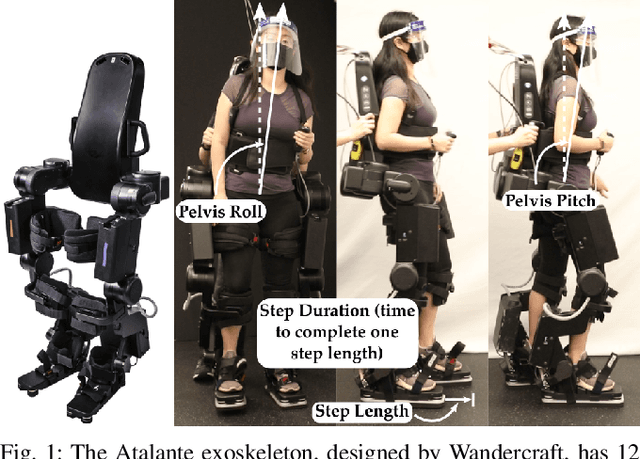

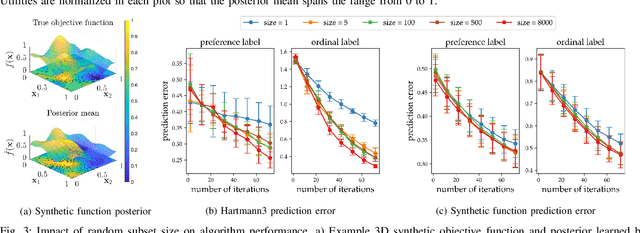
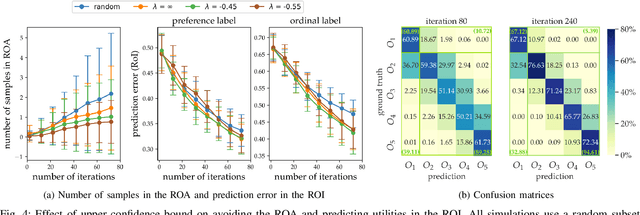
Characterizing what types of exoskeleton gaits are comfortable for users, and understanding the science of walking more generally, require recovering a user's utility landscape. Learning these landscapes is challenging, as walking trajectories are defined by numerous gait parameters, data collection from human trials is expensive, and user safety and comfort must be ensured. This work proposes the Region of Interest Active Learning (ROIAL) framework, which actively learns each user's underlying utility function over a region of interest that ensures safety and comfort. ROIAL learns from ordinal and preference feedback, which are more reliable feedback mechanisms than absolute numerical scores. The algorithm's performance is evaluated both in simulation and experimentally for three able-bodied subjects walking inside of a lower-body exoskeleton. ROIAL learns Bayesian posteriors that predict each exoskeleton user's utility landscape across four exoskeleton gait parameters. The algorithm discovers both commonalities and discrepancies across users' gait preferences and identifies the gait parameters that most influenced user feedback. These results demonstrate the feasibility of recovering gait utility landscapes from limited human trials.
Architecture Agnostic Neural Networks
Nov 05, 2020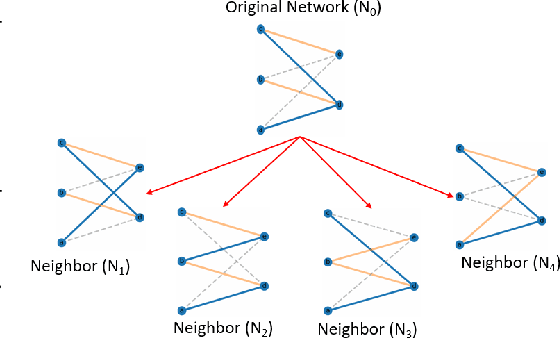
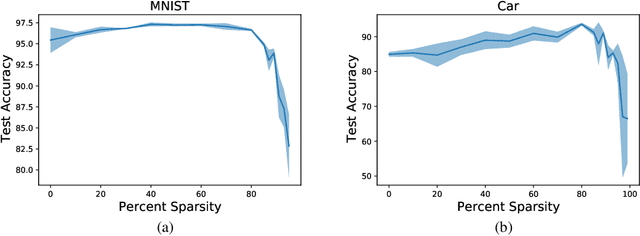
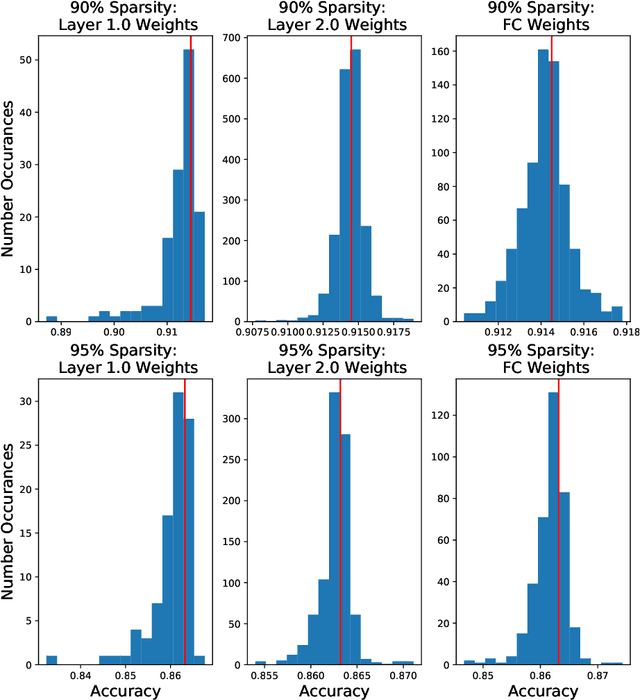

In this paper, we explore an alternate method for synthesizing neural network architectures, inspired by the brain's stochastic synaptic pruning. During a person's lifetime, numerous distinct neuronal architectures are responsible for performing the same tasks. This indicates that biological neural networks are, to some degree, architecture agnostic. However, artificial networks rely on their fine-tuned weights and hand-crafted architectures for their remarkable performance. This contrast begs the question: Can we build artificial architecture agnostic neural networks? To ground this study we utilize sparse, binary neural networks that parallel the brain's circuits. Within this sparse, binary paradigm we sample many binary architectures to create families of architecture agnostic neural networks not trained via backpropagation. These high-performing network families share the same sparsity, distribution of binary weights, and succeed in both static and dynamic tasks. In summation, we create an architecture manifold search procedure to discover families or architecture agnostic neural networks.
Iterative Amortized Policy Optimization
Oct 20, 2020


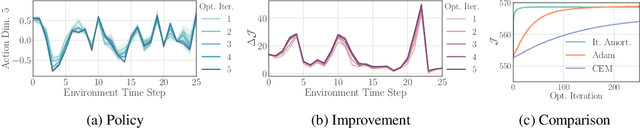
Policy networks are a central feature of deep reinforcement learning (RL) algorithms for continuous control, enabling the estimation and sampling of high-value actions. From the variational inference perspective on RL, policy networks, when employed with entropy or KL regularization, are a form of amortized optimization, optimizing network parameters rather than the policy distributions directly. However, this direct amortized mapping can empirically yield suboptimal policy estimates. Given this perspective, we consider the more flexible class of iterative amortized optimizers. We demonstrate that the resulting technique, iterative amortized policy optimization, yields performance improvements over conventional direct amortization methods on benchmark continuous control tasks.