 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Benefits of Early Fusion in Multimodal Representation Learning
Nov 14, 2020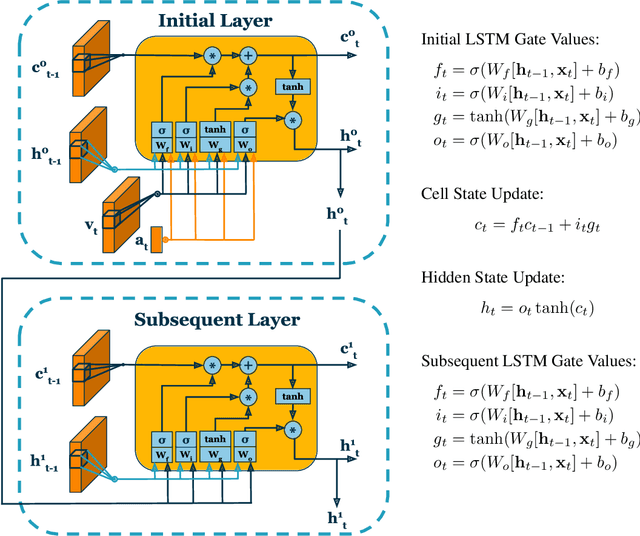
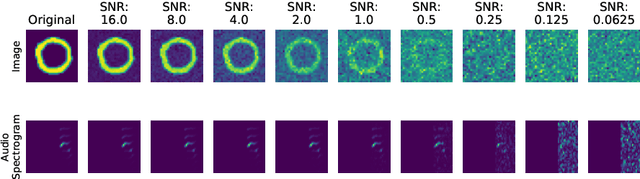
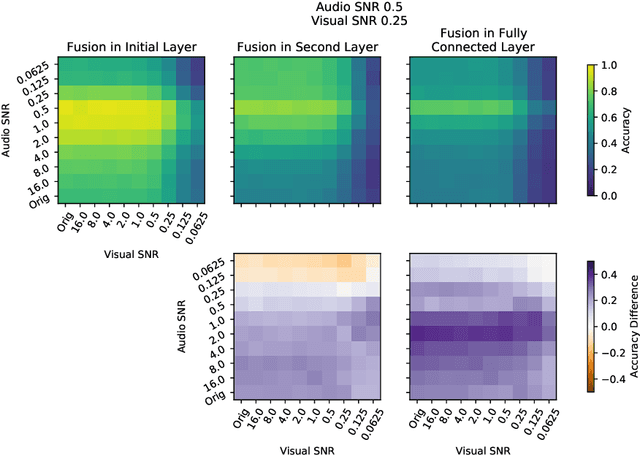
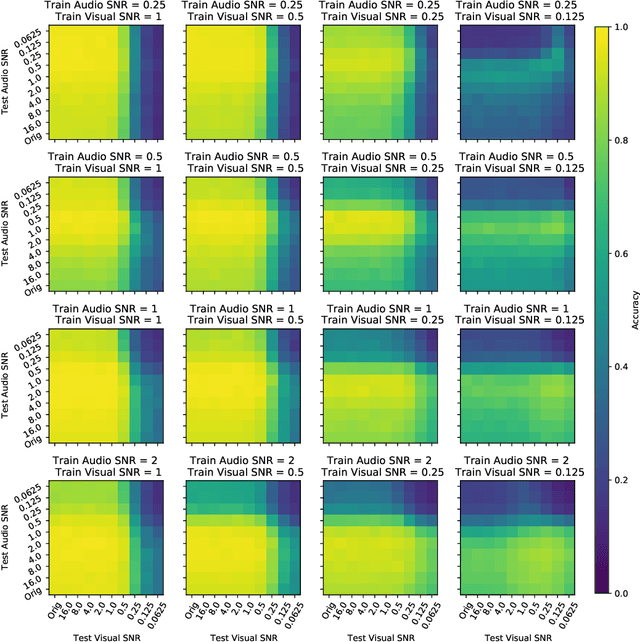
Intelligently reasoning about the world often requires integrating data from multiple modalities, as any individual modality may contain unreliable or incomplete information. Prior work in multimodal learning fuses input modalities only after significant independent processing. On the other hand, the brain performs multimodal processing almost immediately. This divide between conventional multimodal learning and neuroscience suggests that a detailed study of early multimodal fusion could improve artificial multimodal representations. To facilitate the study of early multimodal fusion, we create a convolutional LSTM network architecture that simultaneously processes both audio and visual inputs, and allows us to select the layer at which audio and visual information combines. Our results demonstrate that immediate fusion of audio and visual inputs in the initial C-LSTM layer results in higher performing networks that are more robust to the addition of white noise in both audio and visual inputs.