 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Learning of Neurosymbolic Encoders
Jul 28, 2021

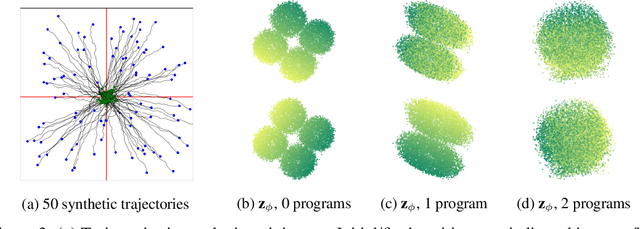
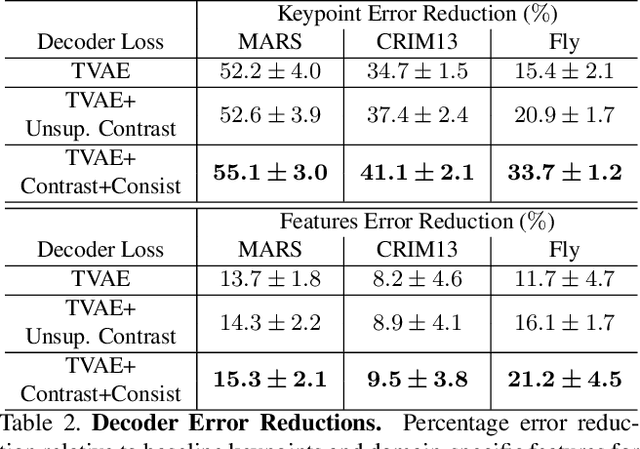
We present a framework for the unsupervised learning of neurosymbolic encoders, i.e., encoders obtained by composing neural networks with symbolic programs from a domain-specific language. Such a framework can naturally incorporate symbolic expert knowledge into the learning process and lead to more interpretable and factorized latent representations than fully neural encoders. Also, models learned this way can have downstream impact, as many analysis workflows can benefit from having clean programmatic descriptions. We ground our learning algorithm in the variational autoencoding (VAE) framework, where we aim to learn a neurosymbolic encoder in conjunction with a standard decoder. Our algorithm integrates standard VAE-style training with modern program synthesis techniques. We evaluate our method on learning latent representations for real-world trajectory data from animal biology and sports analytics. We show that our approach offers significantly better separation than standard VAEs and leads to practical gains on downstream tasks.
Deep Learning-based Damage Mapping with InSAR Coherence Time Series
May 24, 2021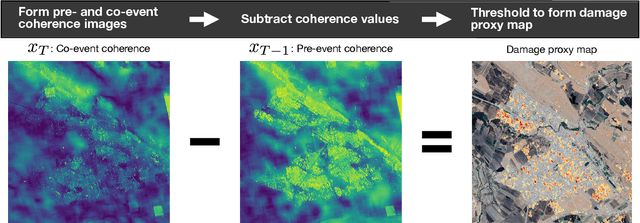
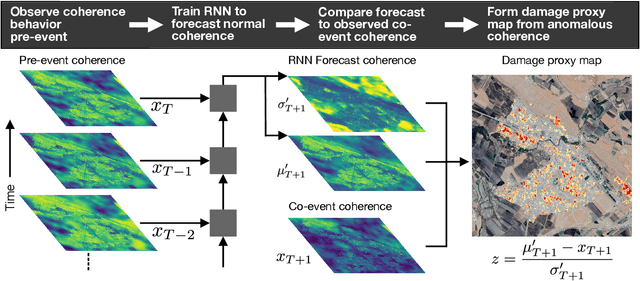
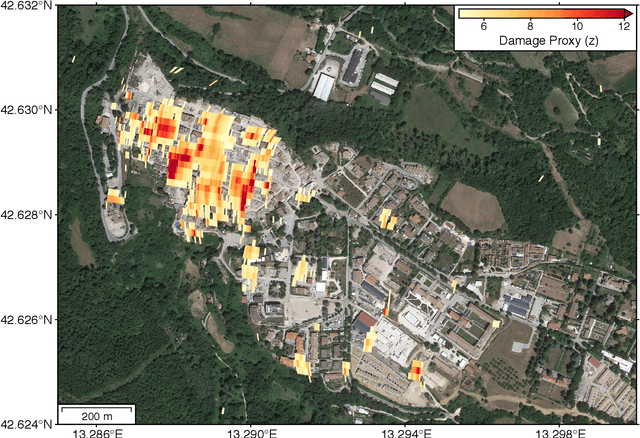
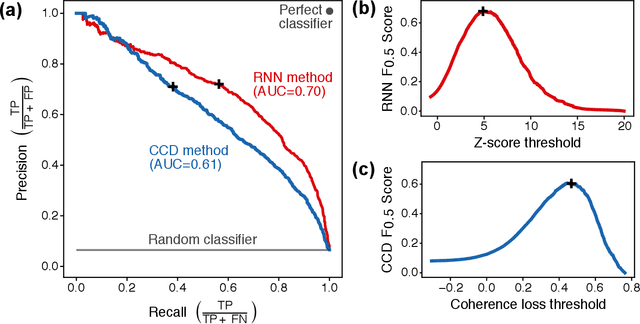
Satellite remote sensing is playing an increasing role in the rapid mapping of damage after natural disasters. In particular, synthetic aperture radar (SAR) can image the Earth's surface and map damage in all weather conditions, day and night. However, current SAR damage mapping methods struggle to separate damage from other changes in the Earth's surface. In this study, we propose a novel approach to damage mapping, combining deep learning with the full time history of SAR observations of an impacted region in order to detect anomalous variations in the Earth's surface properties due to a natural disaster. We quantify Earth surface change using time series of Interferometric SAR coherence, then use a recurrent neural network (RNN) as a probabilistic anomaly detector on these coherence time series. The RNN is first trained on pre-event coherence time series, and then forecasts a probability distribution of the coherence between pre- and post-event SAR images. The difference between the forecast and observed co-event coherence provides a measure of the confidence in the identification of damage. The method allows the user to choose a damage detection threshold that is customized for each location, based on the local behavior of coherence through time before the event. We apply this method to calculate estimates of damage for three earthquakes using multi-year time series of Sentinel-1 SAR acquisitions. Our approach shows good agreement with observed damage and quantitative improvement compared to using pre- to co-event coherence loss as a damage proxy.
Task Programming: Learning Data Efficient Behavior Representations
Nov 27, 2020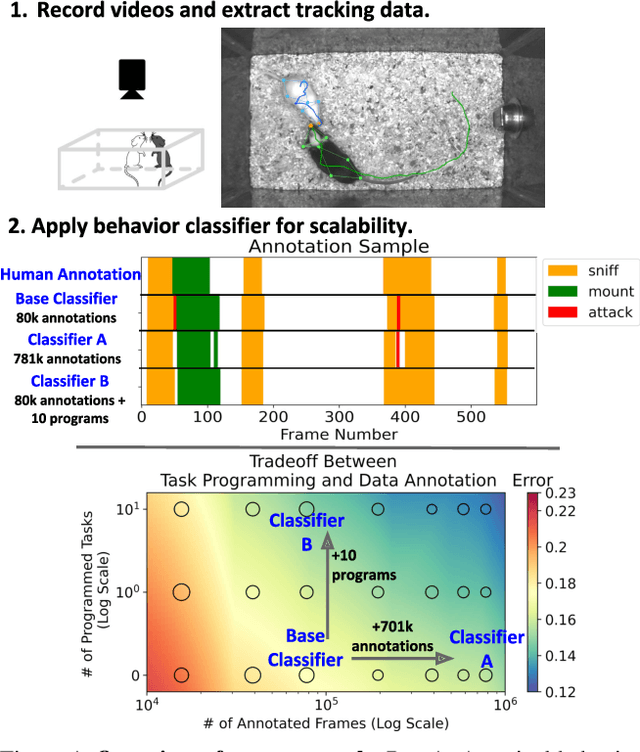
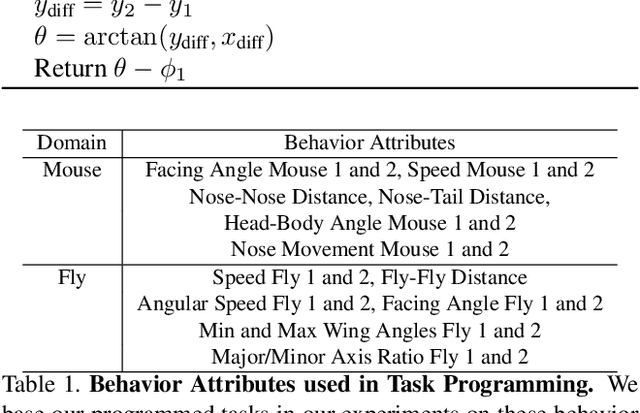
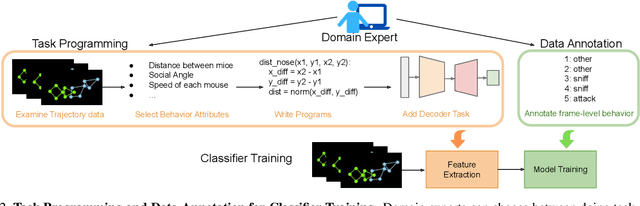
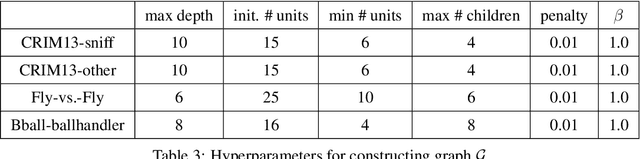
Specialized domain knowledge is often necessary to accurately annotate training sets for in-depth analysis, but can be burdensome and time-consuming to acquire from domain experts. This issue arises prominently in automated behavior analysis, in which agent movements or actions of interest are detected from video tracking data. To reduce annotation effort, we present TREBA: a method to learn annotation-sample efficient trajectory embedding for behavior analysis, based on multi-task self-supervised learning. The tasks in our method can be efficiently engineered by domain experts through a process we call "task programming", which uses programs to explicitly encode structured knowledge from domain experts. Total domain expert effort can be reduced by exchanging data annotation time for the construction of a small number of programmed tasks. We evaluate this trade-off using data from behavioral neuroscience, in which specialized domain knowledge is used to identify behaviors. We present experimental results in three datasets across two domains: mice and fruit flies. Using embeddings from TREBA, we reduce annotation burden by up to a factor of 10 without compromising accuracy compared to state-of-the-art features. Our results thus suggest that task programming can be an effective way to reduce annotation effort for domain experts.
Learning Differentiable Programs with Admissible Neural Heuristics
Jul 26, 2020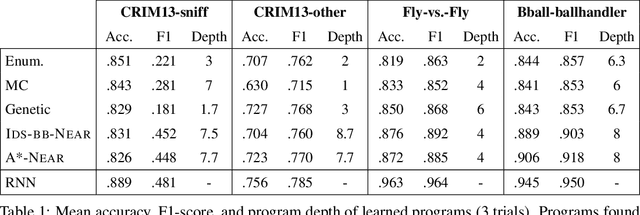
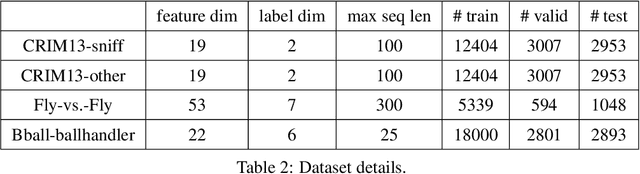
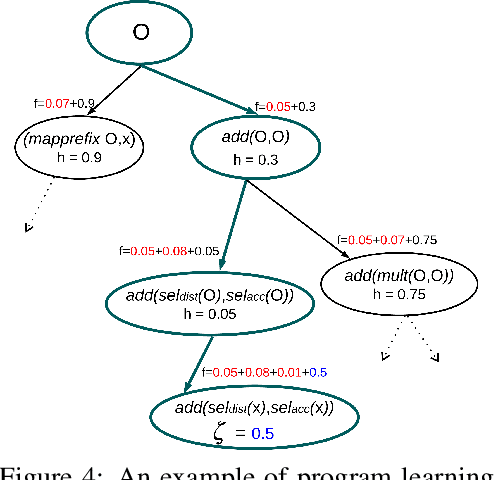
We study the problem of learning differentiable functions expressed as programs in a domain-specific language. Such programmatic models can offer benefits such as composability and interpretability; however, learning them requires optimizing over a combinatorial space of program "architectures". We frame this optimization problem as a search in a weighted graph whose paths encode top-down derivations of program syntax. Our key innovation is to view various classes of neural networks as continuous relaxations over the space of programs, which can then be used to complete any partial program. This relaxed program is differentiable and can be trained end-to-end, and the resulting training loss is an approximately admissible heuristic that can guide the combinatorial search. We instantiate our approach on top of the A-star algorithm and an iteratively deepened branch-and-bound search, and use these algorithms to learn programmatic classifiers in three sequence classification tasks. Our experiments show that the algorithms outperform state-of-the-art methods for program learning, and that they discover programmatic classifiers that yield natural interpretations and achieve competitive accuracy.
Learning Calibratable Policies using Programmatic Style-Consistency
Oct 02, 2019
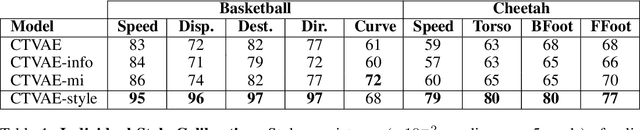
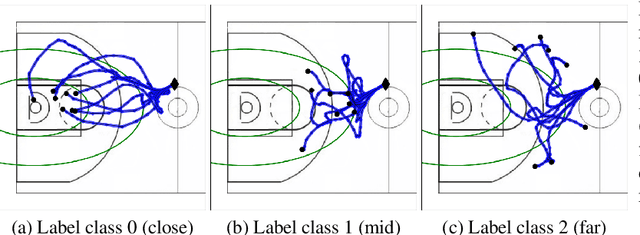
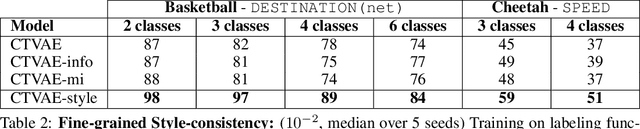
We study the important and challenging problem of controllable generation of long-term sequential behaviors. Solutions to this problem would impact many applications, such as calibrating behaviors of AI agents in games or predicting player trajectories in sports. In contrast to the well-studied areas of controllable generation of images, text, and speech, there are significant challenges that are unique to or exacerbated by generating long-term behaviors: how should we specify the factors of variation to control, and how can we ensure that the generated temporal behavior faithfully demonstrates diverse styles? In this paper, we leverage large amounts of raw behavioral data to learn policies that can be calibrated to generate a diverse range of behavior styles (e.g., aggressive versus passive play in sports). Inspired by recent work on leveraging programmatic labeling functions, we present a novel framework that combines imitation learning with data programming to learn style-calibratable policies. Our primary technical contribution is a formal notion of style-consistency as a learning objective, and its integration with conventional imitation learning approaches. We evaluate our framework using demonstrations from professional basketball players and agents in the MuJoCo physics environment, and show that our learned policies can be accurately calibrated to generate interesting behavior styles in both domains.
NAOMI: Non-Autoregressive Multiresolution Sequence Imputation
Jan 30, 2019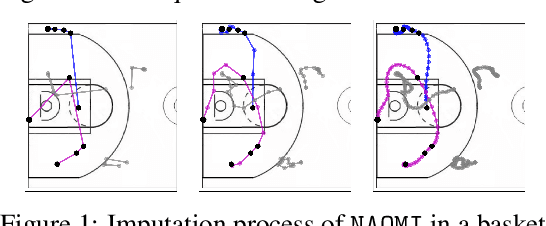

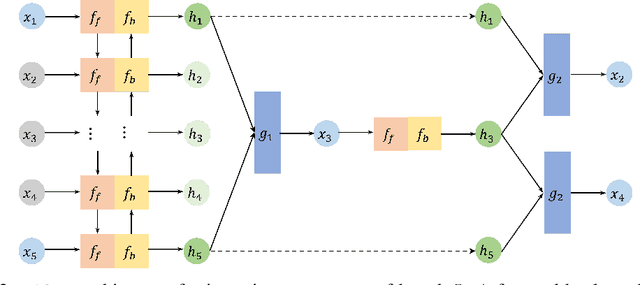

Missing value imputation is a fundamental problem in modeling spatiotemporal sequences, from motion tracking to the dynamics of physical systems. In this paper, we take a non-autoregressive approach and propose a novel deep generative model: Non-AutOregressive Multiresolution Imputation (NAOMI) for imputing long-range spatiotemporal sequences given arbitrary missing patterns. In particular, NAOMI exploits the multiresolution structure of spatiotemporal data to interpolate recursively from coarse to fine-grained resolutions. We further enhance our model with adversarial training using an imitation learning objective. When trained on billiards and basketball trajectories, NAOMI demonstrates significant improvement in imputation accuracy (reducing average prediction error by 60% compared to autoregressive counterparts) and generalization capability for long range trajectories in systems of both deterministic and stochastic dynamics.
Generative Multi-Agent Behavioral Cloning
May 20, 2018
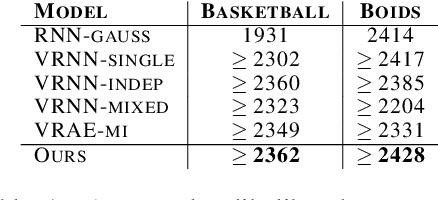
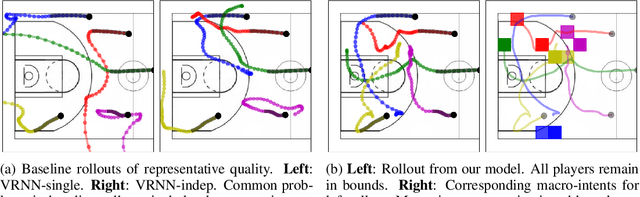
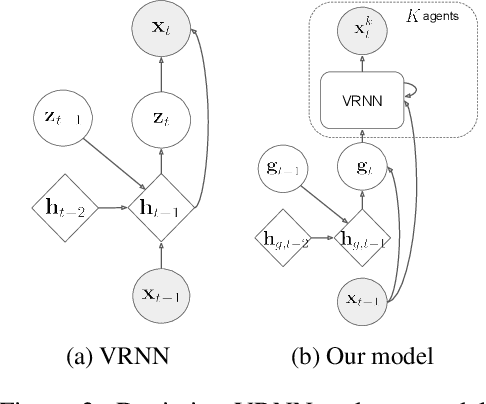
We propose and study the problem of generative multi-agent behavioral cloning, where the goal is to learn a generative, i.e., non-deterministic, multi-agent policy from pre-collected demonstration data. Building upon advances in deep generative models, we present a hierarchical policy framework that can tractably learn complex mappings from input states to distributions over multi-agent action spaces by introducing a hierarchy with macro-intent variables that encode long-term intent. In addition to synthetic settings, we show how to instantiate our framework to effectively model complex interactions between basketball players and generate realistic multi-agent trajectories of basketball gameplay over long time periods. We validate our approach using both quantitative and qualitative evaluations, including a user study comparison conducted with professional sports analysts.