 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Adaptive Nonlinear Control: Theory and Algorithms
Jun 16, 2021


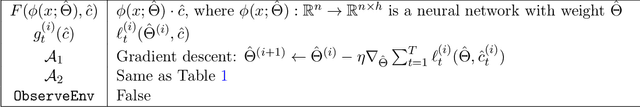
We present an online multi-task learning approach for adaptive nonlinear control, which we call Online Meta-Adaptive Control (OMAC). The goal is to control a nonlinear system subject to adversarial disturbance and unknown $\textit{environment-dependent}$ nonlinear dynamics, under the assumption that the environment-dependent dynamics can be well captured with some shared representation. Our approach is motivated by robot control, where a robotic system encounters a sequence of new environmental conditions that it must quickly adapt to. A key emphasis is to integrate online representation learning with established methods from control theory, in order to arrive at a unified framework that yields both control-theoretic and learning-theoretic guarantees. We provide instantiations of our approach under varying conditions, leading to the first non-asymptotic end-to-end convergence guarantee for multi-task adaptive nonlinear control. OMAC can also be integrated with deep representation learning. Experiments show that OMAC significantly outperforms conventional adaptive control approaches which do not learn the shared representation.
Interpreting Expert Annotation Differences in Animal Behavior
Jun 11, 2021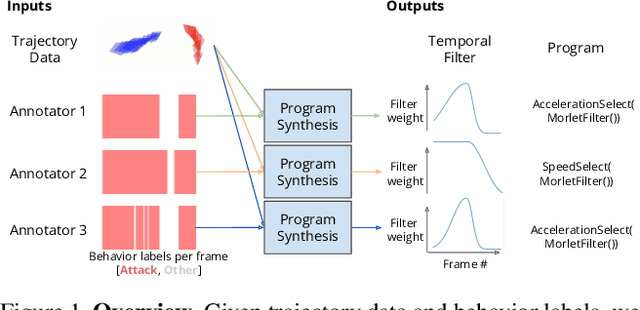
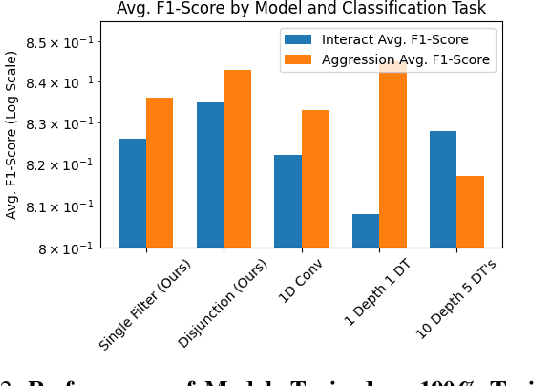
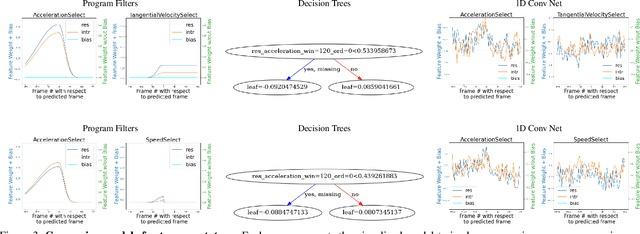
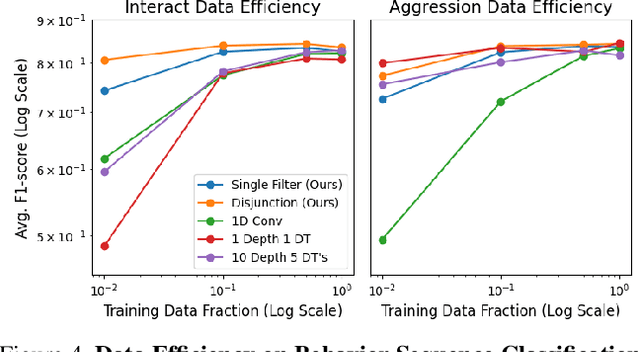
Hand-annotated data can vary due to factors such as subjective differences, intra-rater variability, and differing annotator expertise. We study annotations from different experts who labelled the same behavior classes on a set of animal behavior videos, and observe a variation in annotation styles. We propose a new method using program synthesis to help interpret annotation differences for behavior analysis. Our model selects relevant trajectory features and learns a temporal filter as part of a program, which corresponds to estimated importance an annotator places on that feature at each timestamp. Our experiments on a dataset from behavioral neuroscience demonstrate that compared to baseline approaches, our method is more accurate at capturing annotator labels and learns interpretable temporal filters. We believe that our method can lead to greater reproducibility of behavior annotations used in scientific studies. We plan to release our code.
Fine-Grained System Identification of Nonlinear Neural Circuits
Jun 09, 2021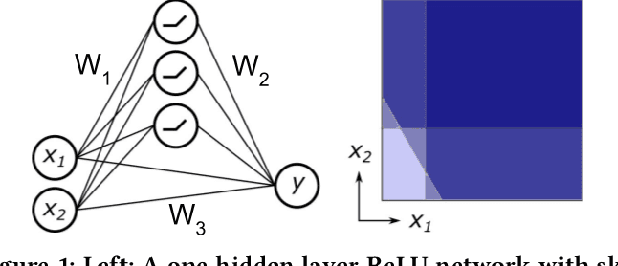
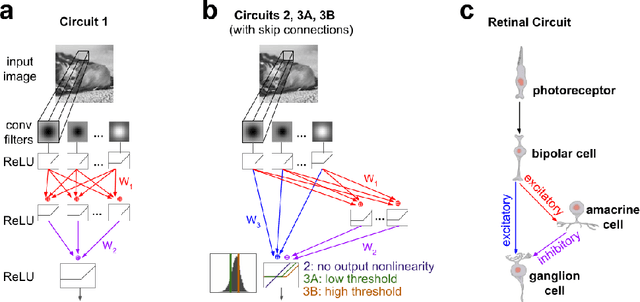
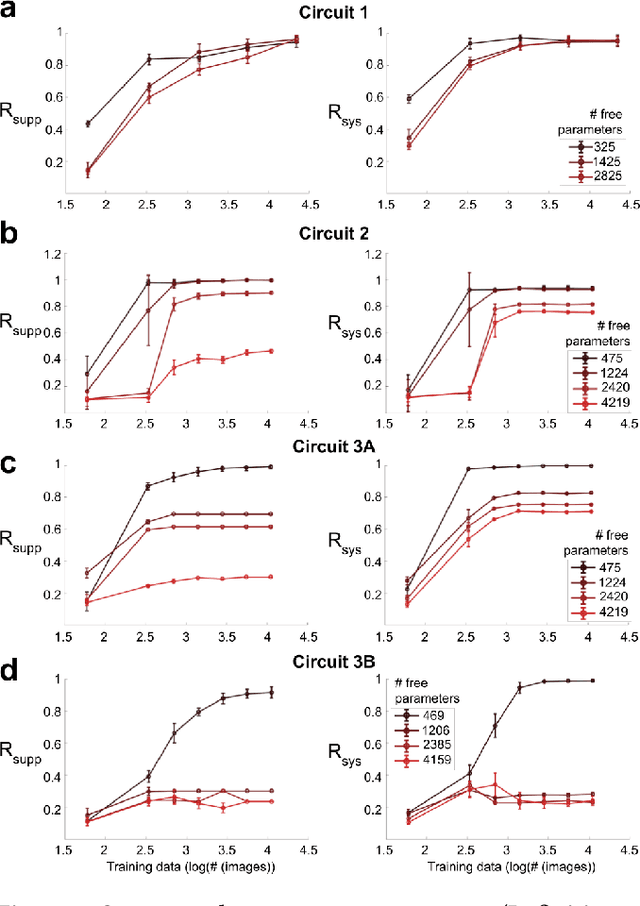
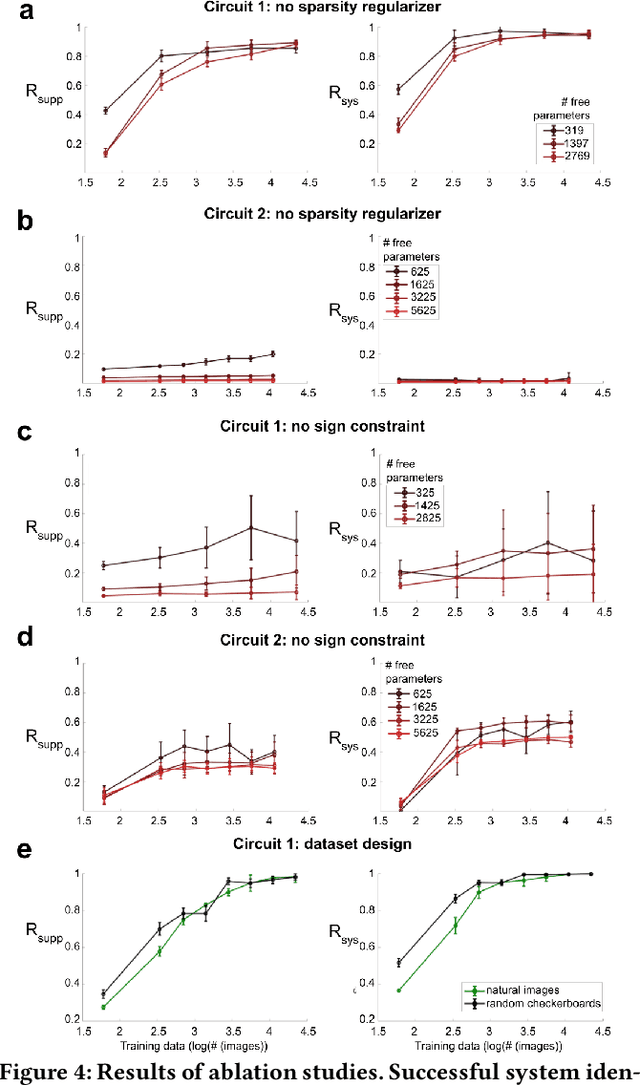
We study the problem of sparse nonlinear model recovery of high dimensional compositional functions. Our study is motivated by emerging opportunities in neuroscience to recover fine-grained models of biological neural circuits using collected measurement data. Guided by available domain knowledge in neuroscience, we explore conditions under which one can recover the underlying biological circuit that generated the training data. Our results suggest insights of both theoretical and practical interests. Most notably, we find that a sign constraint on the weights is a necessary condition for system recovery, which we establish both theoretically with an identifiability guarantee and empirically on simulated biological circuits. We conclude with a case study on retinal ganglion cell circuits using data collected from mouse retina, showcasing the practical potential of this approach.
Learning Pseudo-Backdoors for Mixed Integer Programs
Jun 09, 2021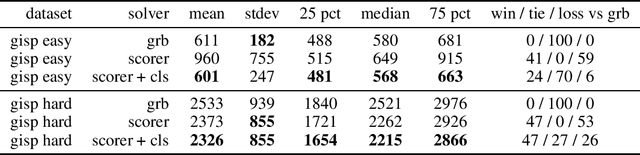
We propose a machine learning approach for quickly solving Mixed Integer Programs (MIP) by learning to prioritize a set of decision variables, which we call pseudo-backdoors, for branching that results in faster solution times. Learning-based approaches have seen success in the area of solving combinatorial optimization problems by being able to flexibly leverage common structures in a given distribution of problems. Our approach takes inspiration from the concept of strong backdoors, which corresponds to a small set of variables such that only branching on these variables yields an optimal integral solution and a proof of optimality. Our notion of pseudo-backdoors corresponds to a small set of variables such that only branching on them leads to faster solve time (which can be solver dependent). A key advantage of pseudo-backdoors over strong backdoors is that they are much amenable to data-driven identification or prediction. Our proposed method learns to estimate the solver performance of a proposed pseudo-backdoor, using a labeled dataset collected on a set of training MIP instances. This model can then be used to identify high-quality pseudo-backdoors on new MIP instances from the same distribution. We evaluate our method on the generalized independent set problems and find that our approach can efficiently identify high-quality pseudo-backdoors. In addition, we compare our learned approach against Gurobi, a state-of-the-art MIP solver, demonstrating that our method can be used to improve solver performance.
End-to-End Sequential Sampling and Reconstruction for MR Imaging
May 13, 2021
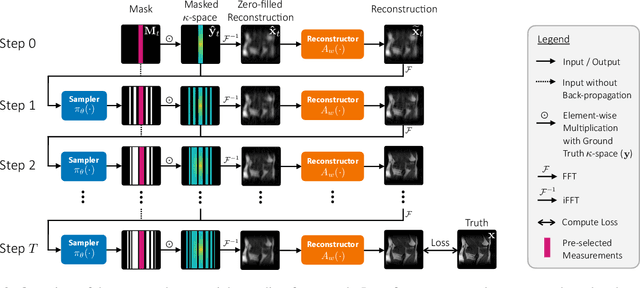


Accelerated MRI shortens acquisition time by subsampling in the measurement k-space. Recovering a high-fidelity anatomical image from subsampled measurements requires close cooperation between two components: (1) a sampler that chooses the subsampling pattern and (2) a reconstructor that recovers images from incomplete measurements. In this paper, we leverage the sequential nature of MRI measurements, and propose a fully differentiable framework that jointly learns a sequential sampling policy simultaneously with a reconstruction strategy. This co-designed framework is able to adapt during acquisition in order to capture the most informative measurements for a particular target (Figure 1). Experimental results on the fastMRI knee dataset demonstrate that the proposed approach successfully utilizes intermediate information during the sampling process to boost reconstruction performance. In particular, our proposed method outperforms the current state-of-the-art learned k-space sampling baseline on up to 96.96% of test samples. We also investigate the individual and collective benefits of the sequential sampling and co-design strategies. Code and more visualizations are available at http://imaging.cms.caltech.edu/seq-mri
The Multi-Agent Behavior Dataset: Mouse Dyadic Social Interactions
Apr 07, 2021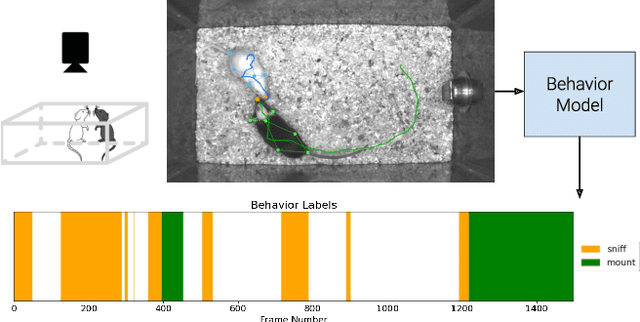
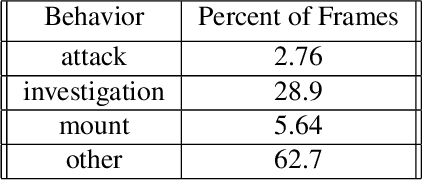
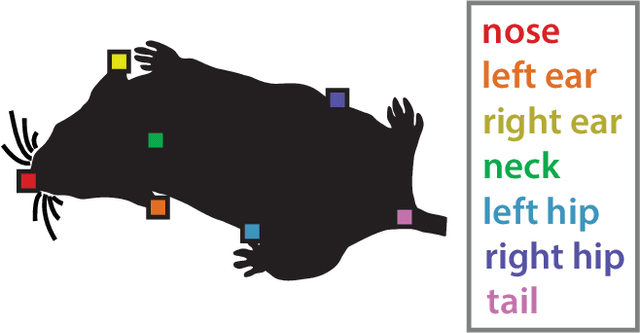
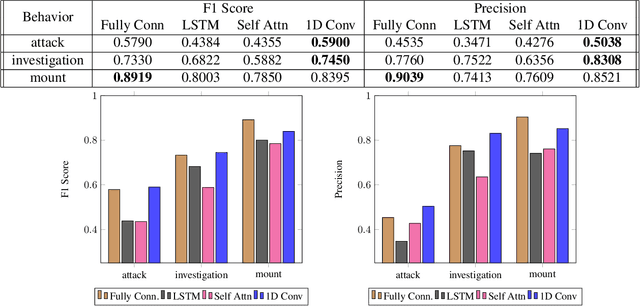
Multi-agent behavior modeling aims to understand the interactions that occur between agents. We present a multi-agent dataset from behavioral neuroscience, the Caltech Mouse Social Interactions (CalMS21) Dataset. Our dataset consists of trajectory data of social interactions, recorded from videos of freely behaving mice in a standard resident-intruder assay. The CalMS21 dataset is part of the Multi-Agent Behavior Challenge 2021 and for our next step, our goal is to incorporate datasets from other domains studying multi-agent behavior. To help accelerate behavioral studies, the CalMS21 dataset provides a benchmark to evaluate the performance of automated behavior classification methods in three settings: (1) for training on large behavioral datasets all annotated by a single annotator, (2) for style transfer to learn inter-annotator differences in behavior definitions, and (3) for learning of new behaviors of interest given limited training data. The dataset consists of 6 million frames of unlabelled tracked poses of interacting mice, as well as over 1 million frames with tracked poses and corresponding frame-level behavior annotations. The challenge of our dataset is to be able to classify behaviors accurately using both labelled and unlabelled tracking data, as well as being able to generalize to new annotators and behaviors.
Learning Unstable Dynamics with One Minute of Data: A Differentiation-based Gaussian Process Approach
Mar 08, 2021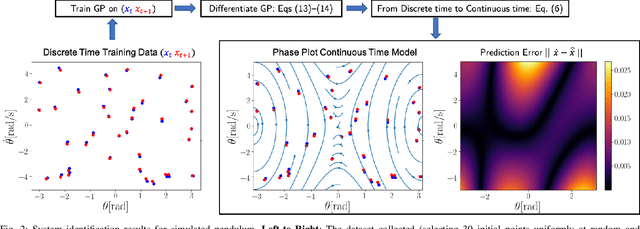
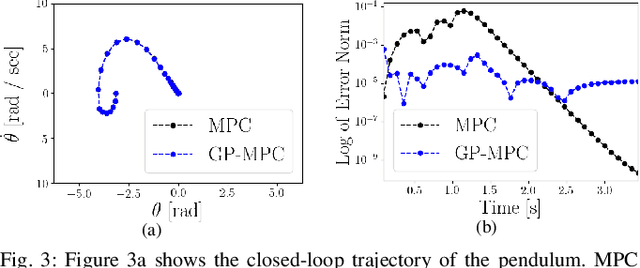
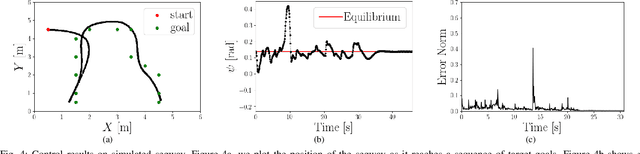
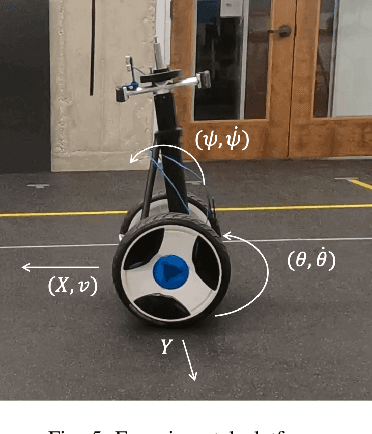
We present a straightforward and efficient way to estimate dynamics models for unstable robotic systems. Specifically, we show how to exploit the differentiability of Gaussian processes to create a state-dependent linearized approximation of the true continuous dynamics. Our approach is compatible with most Gaussian process approaches for system identification, and can learn an accurate model using modest amounts of training data. We validate our approach by iteratively learning the system dynamics of an unstable system such as a 9-D segway (using only one minute of data) and we show that the resulting controller is robust to unmodelled dynamics and disturbances, while state-of-the-art control methods based on nominal models can fail under small perturbations.
Minimax Model Learning
Mar 02, 2021

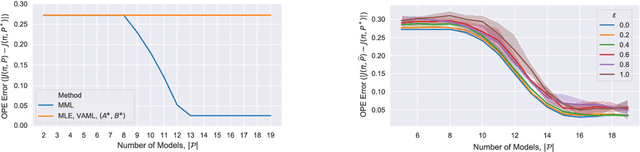
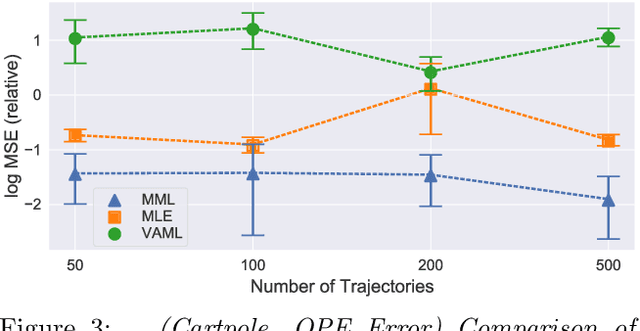
We present a novel off-policy loss function for learning a transition model in model-based reinforcement learning. Notably, our loss is derived from the off-policy policy evaluation objective with an emphasis on correcting distribution shift. Compared to previous model-based techniques, our approach allows for greater robustness under model misspecification or distribution shift induced by learning/evaluating policies that are distinct from the data-generating policy. We provide a theoretical analysis and show empirical improvements over existing model-based off-policy evaluation methods. We provide further analysis showing our loss can be used for off-policy optimization (OPO) and demonstrate its integration with more recent improvements in OPO.
Computing the Information Content of Trained Neural Networks
Mar 01, 2021
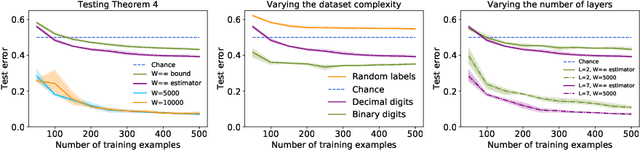
How much information does a learning algorithm extract from the training data and store in a neural network's weights? Too much, and the network would overfit to the training data. Too little, and the network would not fit to anything at all. Na\"ively, the amount of information the network stores should scale in proportion to the number of trainable weights. This raises the question: how can neural networks with vastly more weights than training data still generalise? A simple resolution to this conundrum is that the number of weights is usually a bad proxy for the actual amount of information stored. For instance, typical weight vectors may be highly compressible. Then another question occurs: is it possible to compute the actual amount of information stored? This paper derives both a consistent estimator and a closed-form upper bound on the information content of infinitely wide neural networks. The derivation is based on an identification between neural information content and the negative log probability of a Gaussian orthant. This identification yields bounds that analytically control the generalisation behaviour of the entire solution space of infinitely wide networks. The bounds have a simple dependence on both the network architecture and the training data. Corroborating the findings of Valle-P\'erez et al. (2019), who conducted a similar analysis using approximate Gaussian integration techniques, the bounds are found to be both non-vacuous and correlated with the empirical generalisation behaviour at finite width.
Learning Invariant Representation of Tasks for Robust Surgical State Estimation
Feb 18, 2021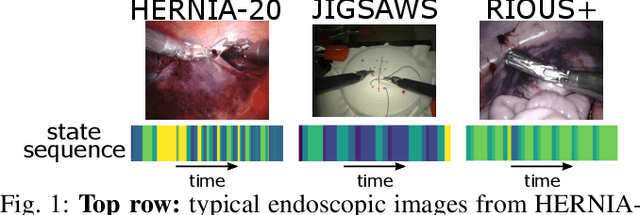
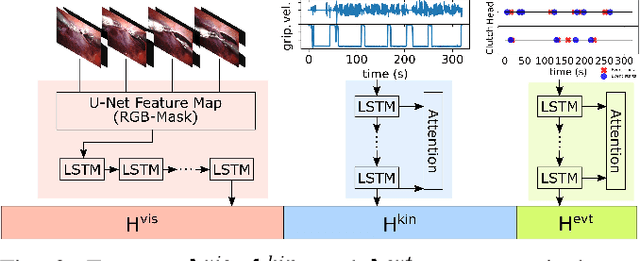
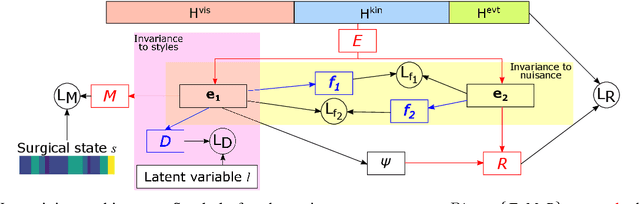
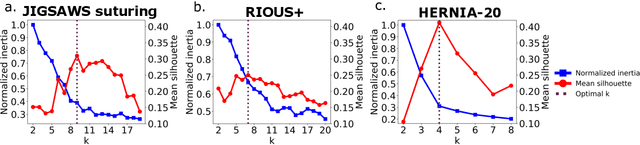
Surgical state estimators in robot-assisted surgery (RAS) - especially those trained via learning techniques - rely heavily on datasets that capture surgeon actions in laboratory or real-world surgical tasks. Real-world RAS datasets are costly to acquire, are obtained from multiple surgeons who may use different surgical strategies, and are recorded under uncontrolled conditions in highly complex environments. The combination of high diversity and limited data calls for new learning methods that are robust and invariant to operating conditions and surgical techniques. We propose StiseNet, a Surgical Task Invariance State Estimation Network with an invariance induction framework that minimizes the effects of variations in surgical technique and operating environments inherent to RAS datasets. StiseNet's adversarial architecture learns to separate nuisance factors from information needed for surgical state estimation. StiseNet is shown to outperform state-of-the-art state estimation methods on three datasets (including a new real-world RAS dataset: HERNIA-20).