 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriply Robust Off-Policy Evaluation
Paper and Code
Nov 16, 2019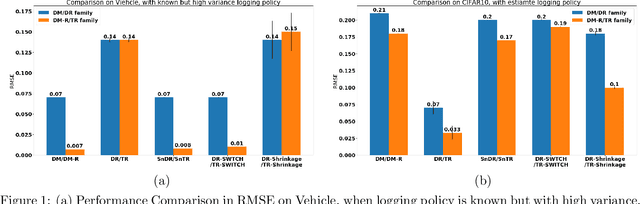
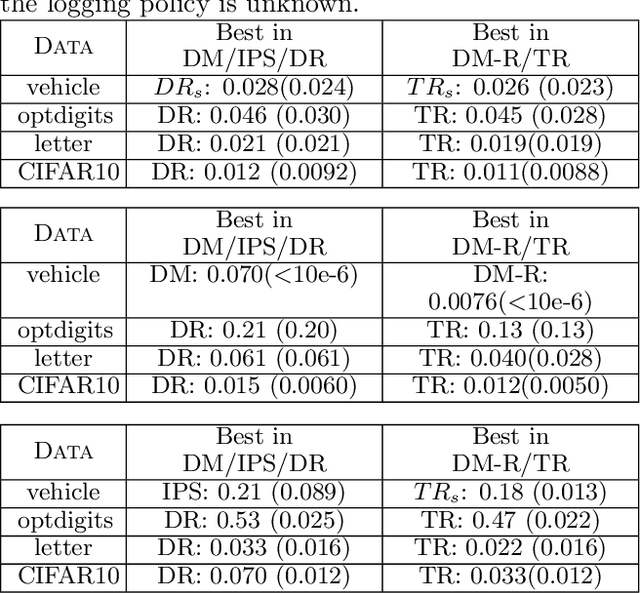
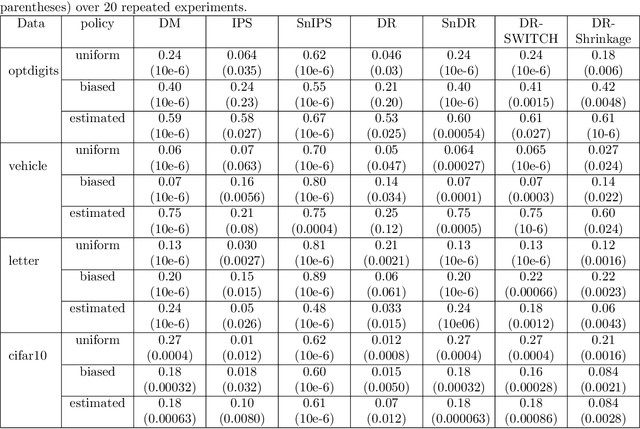
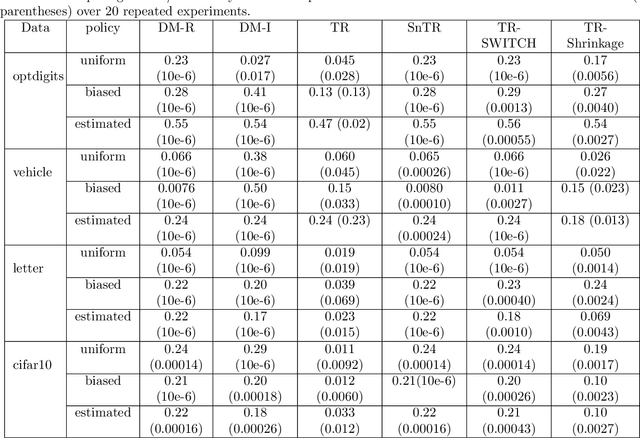
We propose a robust regression approach to off-policy evaluation (OPE) for contextual bandits. We frame OPE as a covariate-shift problem and leverage modern robust regression tools. Ours is a general approach that can be used to augment any existing OPE method that utilizes the direct method. When augmenting doubly robust methods, we call the resulting method Triply Robust. We prove upper bounds on the resulting bias and variance, as well as derive novel minimax bounds based on robust minimax analysis for covariate shift. Our robust regression method is compatible with deep learning, and is thus applicable to complex OPE settings that require powerful function approximators. Finally, we demonstrate superior empirical performance across the standard OPE benchmarks, especially in the case where the logging policy is unknown and must be estimated from data.