 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgesyftr: Pareto-Optimal Generative AI
May 26, 2025Retrieval-Augmented Generation (RAG) pipelines are central to applying large language models (LLMs) to proprietary or dynamic data. However, building effective RAG flows is complex, requiring careful selection among vector databases, embedding models, text splitters, retrievers, and synthesizing LLMs. The challenge deepens with the rise of agentic paradigms. Modules like verifiers, rewriters, and rerankers-each with intricate hyperparameter dependencies have to be carefully tuned. Balancing tradeoffs between latency, accuracy, and cost becomes increasingly difficult in performance-sensitive applications. We introduce syftr, a framework that performs efficient multi-objective search over a broad space of agentic and non-agentic RAG configurations. Using Bayesian Optimization, syftr discovers Pareto-optimal flows that jointly optimize task accuracy and cost. A novel early-stopping mechanism further improves efficiency by pruning clearly suboptimal candidates. Across multiple RAG benchmarks, syftr finds flows which are on average approximately 9 times cheaper while preserving most of the accuracy of the most accurate flows on the Pareto-frontier. Furthermore, syftr's ability to design and optimize allows integrating new modules, making it even easier and faster to realize high-performing generative AI pipelines.
UniMASK: Unified Inference in Sequential Decision Problems
Nov 20, 2022



Randomly masking and predicting word tokens has been a successful approach in pre-training language models for a variety of downstream tasks. In this work, we observe that the same idea also applies naturally to sequential decision-making, where many well-studied tasks like behavior cloning, offline reinforcement learning, inverse dynamics, and waypoint conditioning correspond to different sequence maskings over a sequence of states, actions, and returns. We introduce the UniMASK framework, which provides a unified way to specify models which can be trained on many different sequential decision-making tasks. We show that a single UniMASK model is often capable of carrying out many tasks with performance similar to or better than single-task models. Additionally, after fine-tuning, our UniMASK models consistently outperform comparable single-task models. Our code is publicly available at https://github.com/micahcarroll/uniMASK.
MoCapAct: A Multi-Task Dataset for Simulated Humanoid Control
Aug 15, 2022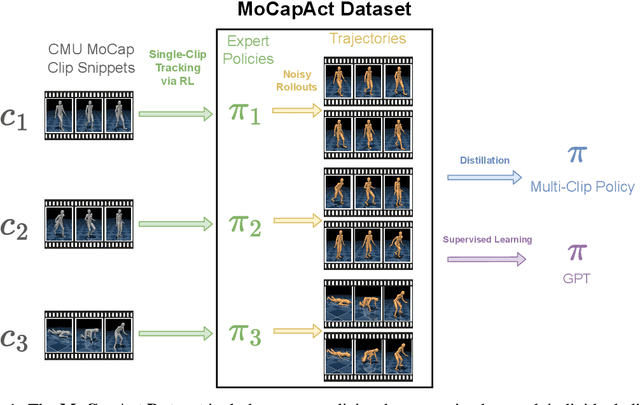
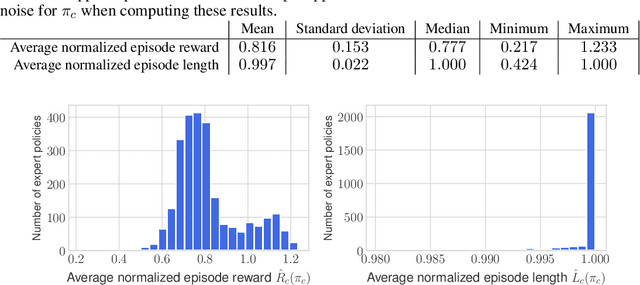

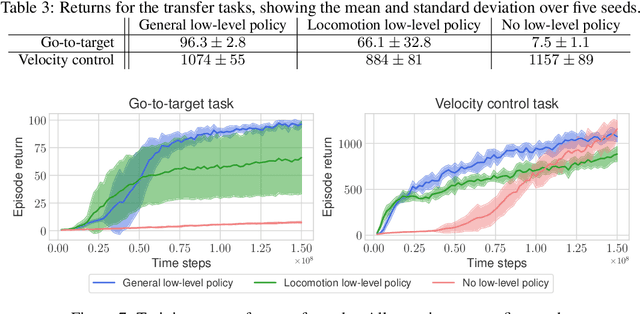
Simulated humanoids are an appealing research domain due to their physical capabilities. Nonetheless, they are also challenging to control, as a policy must drive an unstable, discontinuous, and high-dimensional physical system. One widely studied approach is to utilize motion capture (MoCap) data to teach the humanoid agent low-level skills (e.g., standing, walking, and running) that can then be re-used to synthesize high-level behaviors. However, even with MoCap data, controlling simulated humanoids remains very hard, as MoCap data offers only kinematic information. Finding physical control inputs to realize the demonstrated motions requires computationally intensive methods like reinforcement learning. Thus, despite the publicly available MoCap data, its utility has been limited to institutions with large-scale compute. In this work, we dramatically lower the barrier for productive research on this topic by training and releasing high-quality agents that can track over three hours of MoCap data for a simulated humanoid in the dm_control physics-based environment. We release MoCapAct (Motion Capture with Actions), a dataset of these expert agents and their rollouts, which contain proprioceptive observations and actions. We demonstrate the utility of MoCapAct by using it to train a single hierarchical policy capable of tracking the entire MoCap dataset within dm_control and show the learned low-level component can be re-used to efficiently learn downstream high-level tasks. Finally, we use MoCapAct to train an autoregressive GPT model and show that it can control a simulated humanoid to perform natural motion completion given a motion prompt. Videos of the results and links to the code and dataset are available at https://microsoft.github.io/MoCapAct.
Towards Flexible Inference in Sequential Decision Problems via Bidirectional Transformers
Apr 28, 2022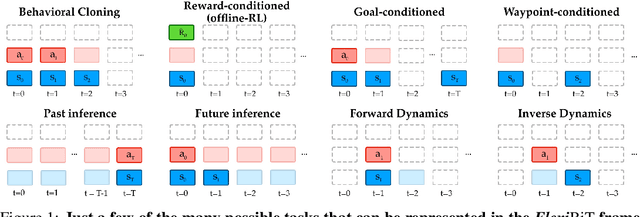
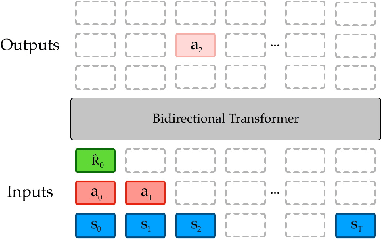
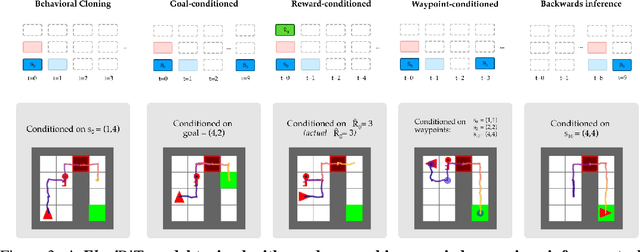
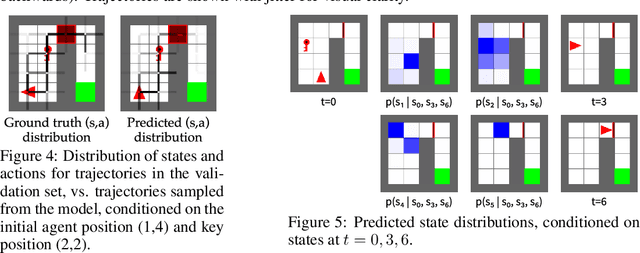
Randomly masking and predicting word tokens has been a successful approach in pre-training language models for a variety of downstream tasks. In this work, we observe that the same idea also applies naturally to sequential decision making, where many well-studied tasks like behavior cloning, offline RL, inverse dynamics, and waypoint conditioning correspond to different sequence maskings over a sequence of states, actions, and returns. We introduce the FlexiBiT framework, which provides a unified way to specify models which can be trained on many different sequential decision making tasks. We show that a single FlexiBiT model is simultaneously capable of carrying out many tasks with performance similar to or better than specialized models. Additionally, we show that performance can be further improved by fine-tuning our general model on specific tasks of interest.
One-Shot Learning from a Demonstration with Hierarchical Latent Language
Mar 09, 2022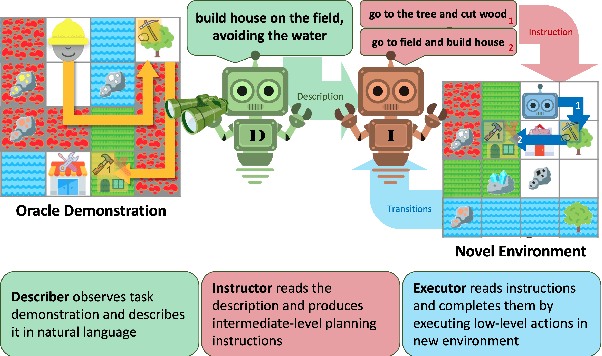
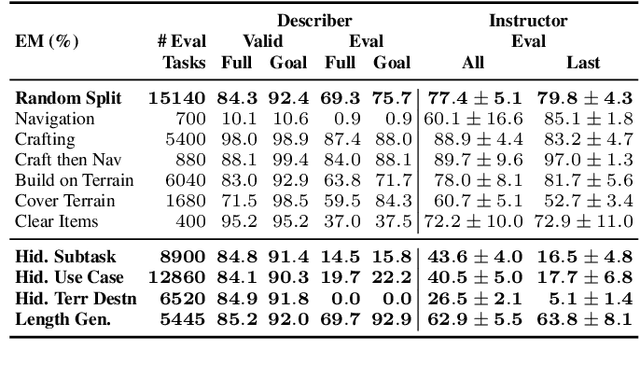
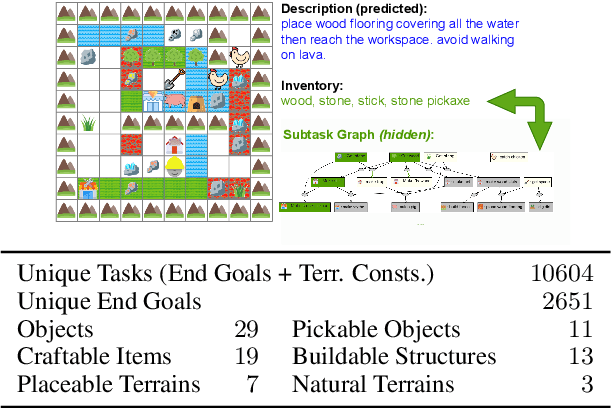
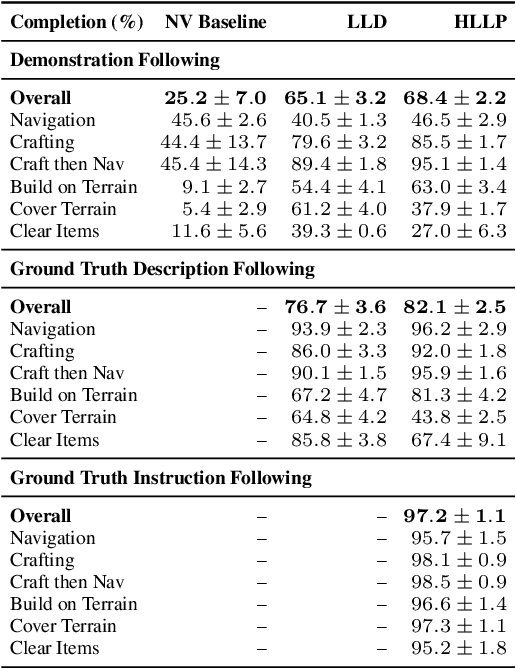
Humans have the capability, aided by the expressive compositionality of their language, to learn quickly by demonstration. They are able to describe unseen task-performing procedures and generalize their execution to other contexts. In this work, we introduce DescribeWorld, an environment designed to test this sort of generalization skill in grounded agents, where tasks are linguistically and procedurally composed of elementary concepts. The agent observes a single task demonstration in a Minecraft-like grid world, and is then asked to carry out the same task in a new map. To enable such a level of generalization, we propose a neural agent infused with hierarchical latent language--both at the level of task inference and subtask planning. Our agent first generates a textual description of the demonstrated unseen task, then leverages this description to replicate it. Through multiple evaluation scenarios and a suite of generalization tests, we find that agents that perform text-based inference are better equipped for the challenge under a random split of tasks.
Consistent Dropout for Policy Gradient Reinforcement Learning
Feb 23, 2022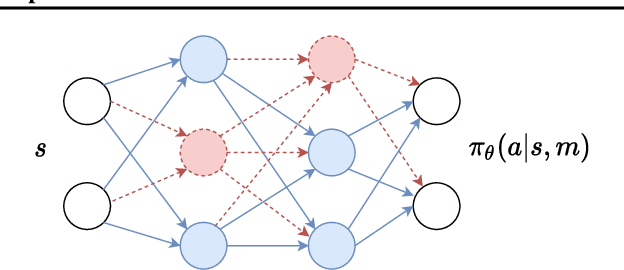
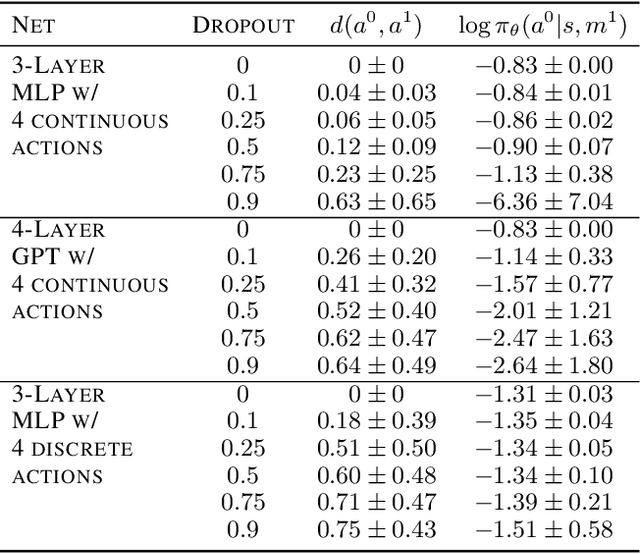
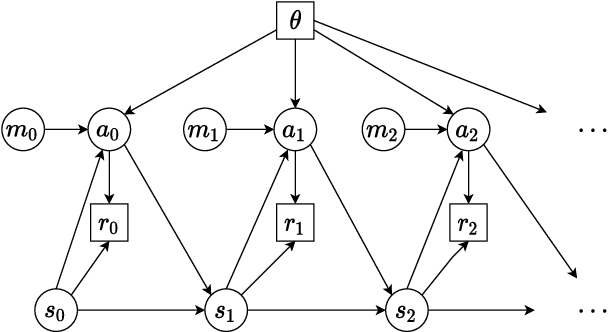

Dropout has long been a staple of supervised learning, but is rarely used in reinforcement learning. We analyze why naive application of dropout is problematic for policy-gradient learning algorithms and introduce consistent dropout, a simple technique to address this instability. We demonstrate consistent dropout enables stable training with A2C and PPO in both continuous and discrete action environments across a wide range of dropout probabilities. Finally, we show that consistent dropout enables the online training of complex architectures such as GPT without needing to disable the model's native dropout.
Measuring Sample Efficiency and Generalization in Reinforcement Learning Benchmarks: NeurIPS 2020 Procgen Benchmark
Mar 29, 2021
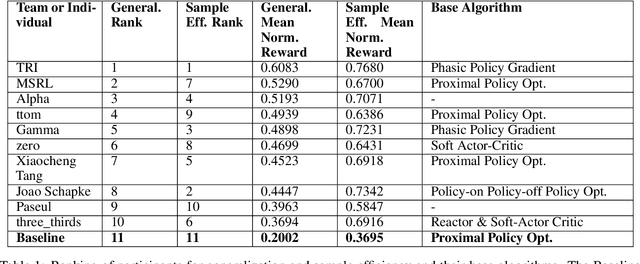
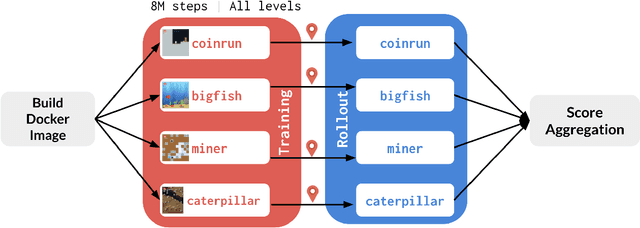
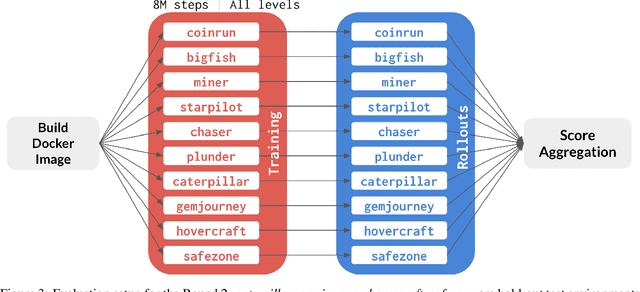
The NeurIPS 2020 Procgen Competition was designed as a centralized benchmark with clearly defined tasks for measuring Sample Efficiency and Generalization in Reinforcement Learning. Generalization remains one of the most fundamental challenges in deep reinforcement learning, and yet we do not have enough benchmarks to measure the progress of the community on Generalization in Reinforcement Learning. We present the design of a centralized benchmark for Reinforcement Learning which can help measure Sample Efficiency and Generalization in Reinforcement Learning by doing end to end evaluation of the training and rollout phases of thousands of user submitted code bases in a scalable way. We designed the benchmark on top of the already existing Procgen Benchmark by defining clear tasks and standardizing the end to end evaluation setups. The design aims to maximize the flexibility available for researchers who wish to design future iterations of such benchmarks, and yet imposes necessary practical constraints to allow for a system like this to scale. This paper presents the competition setup and the details and analysis of the top solutions identified through this setup in context of 2020 iteration of the competition at NeurIPS.
Reading and Acting while Blindfolded: The Need for Semantics in Text Game Agents
Mar 25, 2021
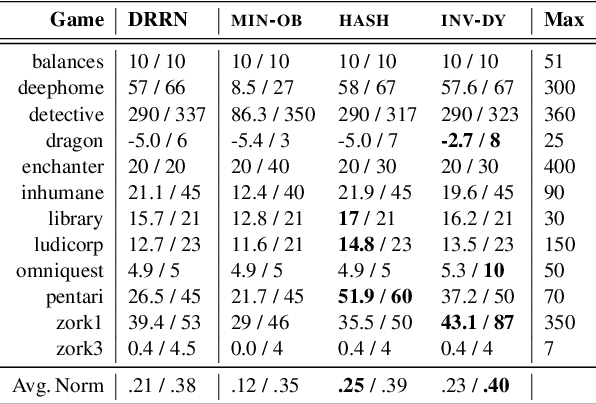
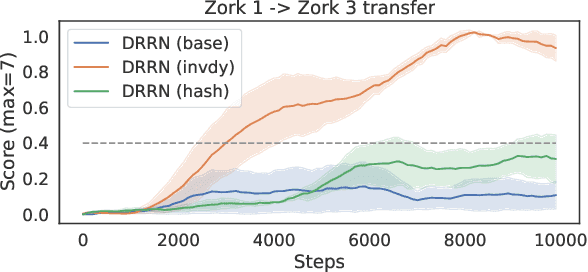
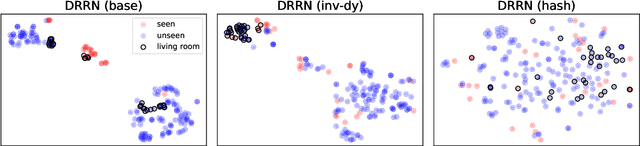
Text-based games simulate worlds and interact with players using natural language. Recent work has used them as a testbed for autonomous language-understanding agents, with the motivation being that understanding the meanings of words or semantics is a key component of how humans understand, reason, and act in these worlds. However, it remains unclear to what extent artificial agents utilize semantic understanding of the text. To this end, we perform experiments to systematically reduce the amount of semantic information available to a learning agent. Surprisingly, we find that an agent is capable of achieving high scores even in the complete absence of language semantics, indicating that the currently popular experimental setup and models may be poorly designed to understand and leverage game texts. To remedy this deficiency, we propose an inverse dynamics decoder to regularize the representation space and encourage exploration, which shows improved performance on several games including Zork I. We discuss the implications of our findings for designing future agents with stronger semantic understanding.
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning
Oct 08, 2020
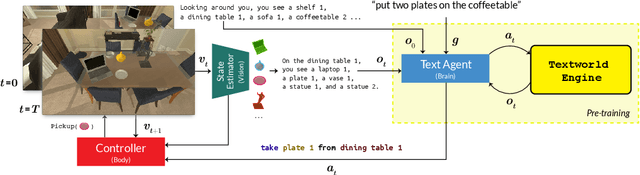

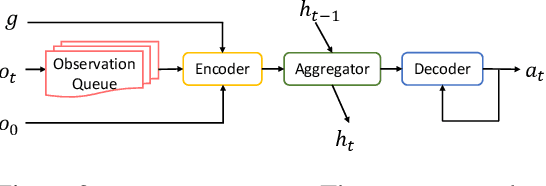
Given a simple request (e.g., Put a washed apple in the kitchen fridge), humans can reason in purely abstract terms by imagining action sequences and scoring their likelihood of success, prototypicality, and efficiency, all without moving a muscle. Once we see the kitchen in question, we can update our abstract plans to fit the scene. Embodied agents require the same abilities, but existing work does not yet provide the infrastructure necessary for both reasoning abstractly and executing concretely. We address this limitation by introducing ALFWorld, a simulator that enables agents to learn abstract, text-based policies in TextWorld (C\^ot\'e et al., 2018) and then execute goals from the ALFRED benchmark (Shridhar et al., 2020) in a rich visual environment. ALFWorld enables the creation of a new BUTLER agent whose abstract knowledge, learned in TextWorld, corresponds directly to concrete, visually grounded actions. In turn, as we demonstrate empirically, this fosters better agent generalization than training only in the visually grounded environment. BUTLER's simple, modular design factors the problem to allow researchers to focus on models for improving every piece of the pipeline (language understanding, planning, navigation, visual scene understanding, and so forth).
Keep CALM and Explore: Language Models for Action Generation in Text-based Games
Oct 06, 2020
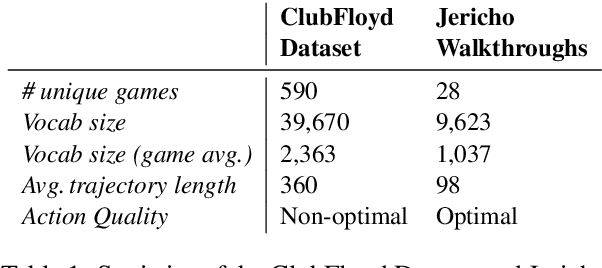
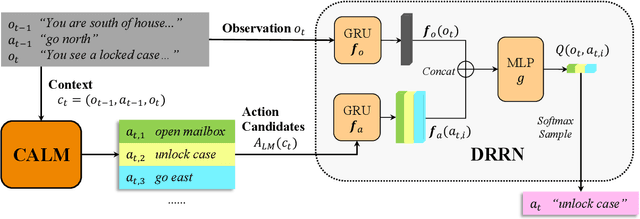
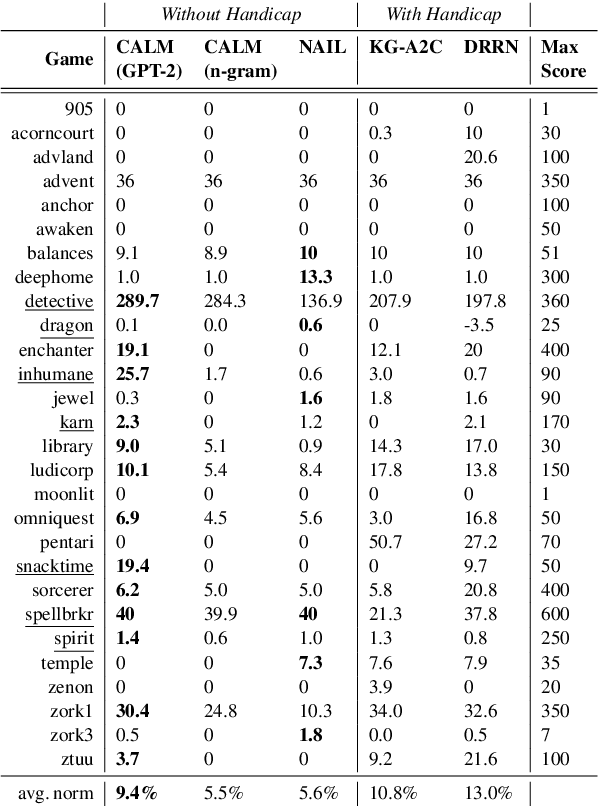
Text-based games present a unique challenge for autonomous agents to operate in natural language and handle enormous action spaces. In this paper, we propose the Contextual Action Language Model (CALM) to generate a compact set of action candidates at each game state. Our key insight is to train language models on human gameplay, where people demonstrate linguistic priors and a general game sense for promising actions conditioned on game history. We combine CALM with a reinforcement learning agent which re-ranks the generated action candidates to maximize in-game rewards. We evaluate our approach using the Jericho benchmark, on games unseen by CALM during training. Our method obtains a 69% relative improvement in average game score over the previous state-of-the-art model. Surprisingly, on half of these games, CALM is competitive with or better than other models that have access to ground truth admissible actions. Code and data are available at https://github.com/princeton-nlp/calm-textgame.