 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreference Conditioned Multi-Objective Reinforcement Learning: Decomposed, Diversity-Driven Policy Optimization
Feb 08, 2026Multi-objective reinforcement learning (MORL) seeks to learn policies that balance multiple, often conflicting objectives. Although a single preference-conditioned policy is the most flexible and scalable solution, existing approaches remain brittle in practice, frequently failing to recover complete Pareto fronts. We show that this failure stems from two structural issues in current methods: destructive gradient interference caused by premature scalarization and representational collapse across the preference space. We introduce $D^3PO$, a PPO-based framework that reorganizes multi-objective policy optimization to address these issues directly. $D^3PO$ preserves per-objective learning signals through a decomposed optimization pipeline and integrates preferences only after stabilization, enabling reliable credit assignment. In addition, a scaled diversity regularizer enforces sensitivity of policy behavior to preference changes, preventing collapse. Across standard MORL benchmarks, including high-dimensional and many-objective control tasks, $D^3PO$ consistently discovers broader and higher-quality Pareto fronts than prior single- and multi-policy methods, matching or exceeding state-of-the-art hypervolume and expected utility while using a single deployable policy.
Joint Analysis of Optical and SAR Vegetation Indices for Vineyard Monitoring: Assessing Biomass Dynamics and Phenological Stages over Po Valley, Italy
Jun 16, 2025Multi-polarized Synthetic Aperture Radar (SAR) technology has gained increasing attention in agriculture, offering unique capabilities for monitoring vegetation dynamics thanks to its all-weather, day-and-night operation and high revisit frequency. This study presents, for the first time, a comprehensive analysis combining dual-polarimetric radar vegetation index (DpRVI) with optical indices to characterize vineyard crops. Vineyards exhibit distinct non-isotropic scattering behavior due to their pronounced row orientation, making them particularly challenging and interesting targets for remote sensing. The research further investigates the relationship between DpRVI and optical vegetation indices, demonstrating the complementary nature of their information. We demonstrate that DpRVI and optical indices provide complementary information, with low correlation suggesting that they capture distinct vineyard features. Key findings reveal a parabolic trend in DpRVI over the growing season, potentially linked to biomass dynamics estimated via the Winkler Index. Unlike optical indices reflecting vegetation greenness, DpRVI appears more directly related to biomass growth, aligning with specific phenological phases. Preliminary results also highlight the potential of DpRVI for distinguishing vineyards from other crops. This research aligns with the objectives of the PNRR-NODES project, which promotes nature-based solutions (NbS) for sustainable vineyard management. The application of DpRVI for monitoring vineyards is part of integrating remote sensing techniques into the broader field of strategies for climate-related change adaptation and risk reduction, emphasizing the role of innovative SAR-based monitoring in sustainable agriculture.
Deep Policy Optimization with Temporal Logic Constraints
Apr 17, 2024



Temporal logics, such as linear temporal logic (LTL), offer a precise means of specifying tasks for (deep) reinforcement learning (RL) agents. In our work, we consider the setting where the task is specified by an LTL objective and there is an additional scalar reward that we need to optimize. Previous works focus either on learning a LTL task-satisfying policy alone or are restricted to finite state spaces. We make two contributions: First, we introduce an RL-friendly approach to this setting by formulating this problem as a single optimization objective. Our formulation guarantees that an optimal policy will be reward-maximal from the set of policies that maximize the likelihood of satisfying the LTL specification. Second, we address a sparsity issue that often arises for LTL-guided Deep RL policies by introducing Cycle Experience Replay (CyclER), a technique that automatically guides RL agents towards the satisfaction of an LTL specification. Our experiments demonstrate the efficacy of CyclER in finding performant deep RL policies in both continuous and discrete experimental domains.
Compositional Policy Learning in Stochastic Control Systems with Formal Guarantees
Dec 03, 2023



Reinforcement learning has shown promising results in learning neural network policies for complicated control tasks. However, the lack of formal guarantees about the behavior of such policies remains an impediment to their deployment. We propose a novel method for learning a composition of neural network policies in stochastic environments, along with a formal certificate which guarantees that a specification over the policy's behavior is satisfied with the desired probability. Unlike prior work on verifiable RL, our approach leverages the compositional nature of logical specifications provided in SpectRL, to learn over graphs of probabilistic reach-avoid specifications. The formal guarantees are provided by learning neural network policies together with reach-avoid supermartingales (RASM) for the graph's sub-tasks and then composing them into a global policy. We also derive a tighter lower bound compared to previous work on the probability of reach-avoidance implied by a RASM, which is required to find a compositional policy with an acceptable probabilistic threshold for complex tasks with multiple edge policies. We implement a prototype of our approach and evaluate it on a Stochastic Nine Rooms environment.
Eventual Discounting Temporal Logic Counterfactual Experience Replay
Mar 03, 2023



Linear temporal logic (LTL) offers a simplified way of specifying tasks for policy optimization that may otherwise be difficult to describe with scalar reward functions. However, the standard RL framework can be too myopic to find maximally LTL satisfying policies. This paper makes two contributions. First, we develop a new value-function based proxy, using a technique we call eventual discounting, under which one can find policies that satisfy the LTL specification with highest achievable probability. Second, we develop a new experience replay method for generating off-policy data from on-policy rollouts via counterfactual reasoning on different ways of satisfying the LTL specification. Our experiments, conducted in both discrete and continuous state-action spaces, confirm the effectiveness of our counterfactual experience replay approach.
Neurosymbolic Reinforcement Learning with Formally Verified Exploration
Oct 26, 2020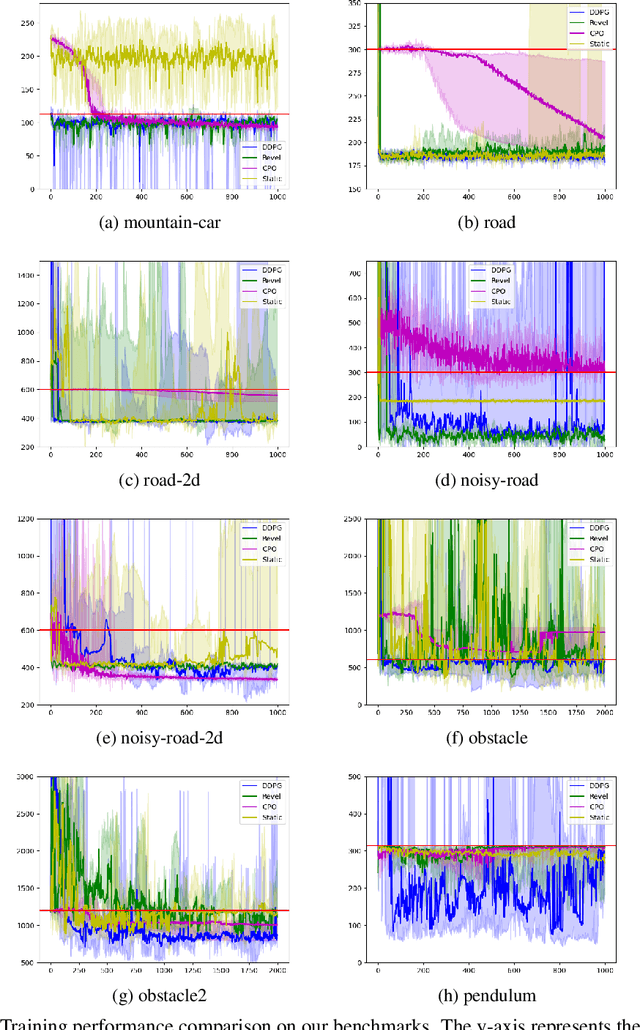
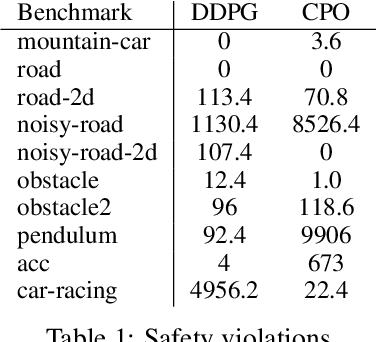
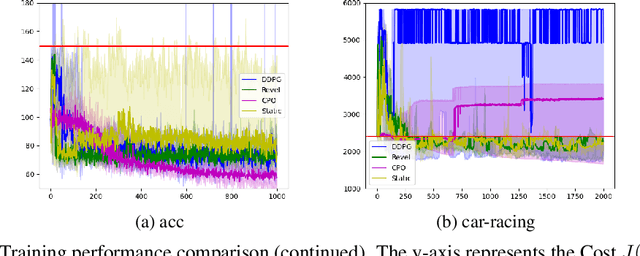
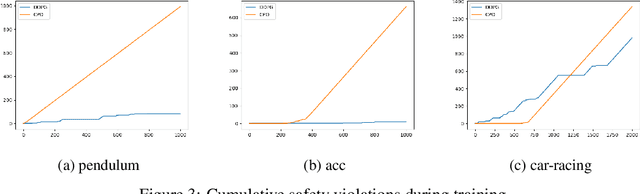
We present Revel, a partially neural reinforcement learning (RL) framework for provably safe exploration in continuous state and action spaces. A key challenge for provably safe deep RL is that repeatedly verifying neural networks within a learning loop is computationally infeasible. We address this challenge using two policy classes: a general, neurosymbolic class with approximate gradients and a more restricted class of symbolic policies that allows efficient verification. Our learning algorithm is a mirror descent over policies: in each iteration, it safely lifts a symbolic policy into the neurosymbolic space, performs safe gradient updates to the resulting policy, and projects the updated policy into the safe symbolic subset, all without requiring explicit verification of neural networks. Our empirical results show that Revel enforces safe exploration in many scenarios in which Constrained Policy Optimization does not, and that it can discover policies that outperform those learned through prior approaches to verified exploration.
Learning Differentiable Programs with Admissible Neural Heuristics
Jul 26, 2020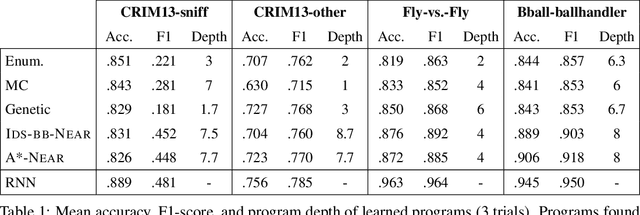
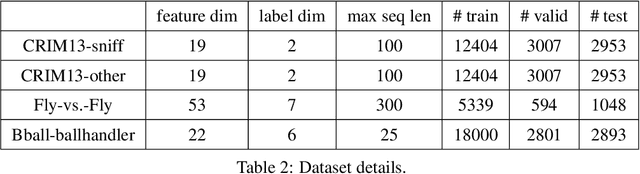
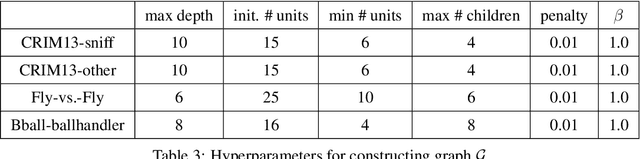
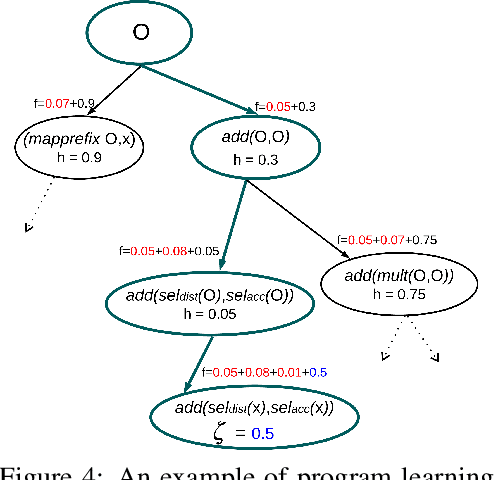
We study the problem of learning differentiable functions expressed as programs in a domain-specific language. Such programmatic models can offer benefits such as composability and interpretability; however, learning them requires optimizing over a combinatorial space of program "architectures". We frame this optimization problem as a search in a weighted graph whose paths encode top-down derivations of program syntax. Our key innovation is to view various classes of neural networks as continuous relaxations over the space of programs, which can then be used to complete any partial program. This relaxed program is differentiable and can be trained end-to-end, and the resulting training loss is an approximately admissible heuristic that can guide the combinatorial search. We instantiate our approach on top of the A-star algorithm and an iteratively deepened branch-and-bound search, and use these algorithms to learn programmatic classifiers in three sequence classification tasks. Our experiments show that the algorithms outperform state-of-the-art methods for program learning, and that they discover programmatic classifiers that yield natural interpretations and achieve competitive accuracy.
Imitation-Projected Policy Gradient for Programmatic Reinforcement Learning
Jul 11, 2019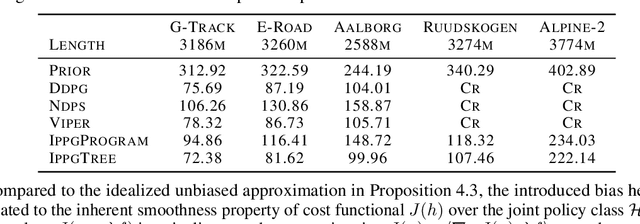

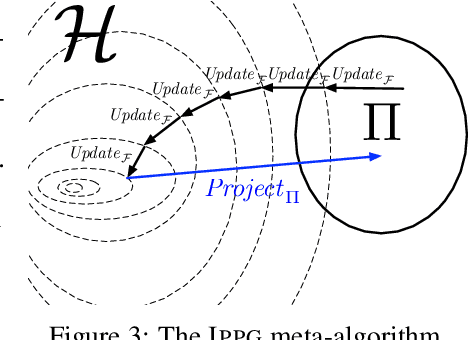
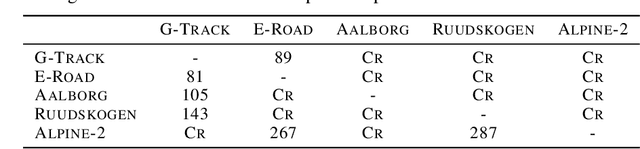
We present Imitation-Projected Policy Gradient (IPPG), an algorithmic framework for learning policies that are parsimoniously represented in a structured programming language. Such programmatic policies can be more interpretable, generalizable, and amenable to formal verification than neural policies; however, designing rigorous learning approaches for programmatic policies remains a challenge. IPPG, our response to this challenge, is based on three insights. First, we view our learning task as optimization in policy space, modulo the constraint that the desired policy has a programmatic representation, and solve this optimization problem using a "lift-and-project" perspective that takes a gradient step into the unconstrained policy space and then projects back onto the constrained space. Second, we view the unconstrained policy space as mixing neural and programmatic representations, which enables employing state-of-the-art deep policy gradient approaches. Third, we cast the projection step as program synthesis via imitation learning, and exploit contemporary combinatorial methods for this task. We present theoretical convergence results for IPPG, as well as an empirical evaluation in three continuous control domains. The experiments show that IPPG can significantly outperform state-of-the-art approaches for learning programmatic policies.
Control Regularization for Reduced Variance Reinforcement Learning
May 14, 2019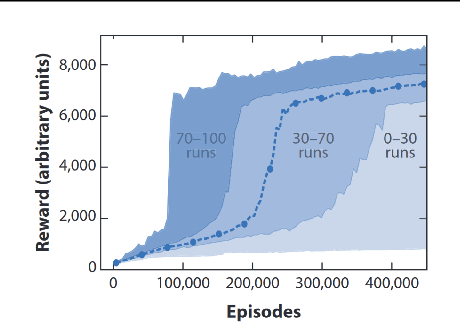
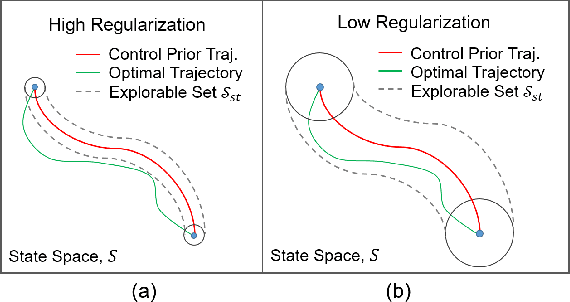
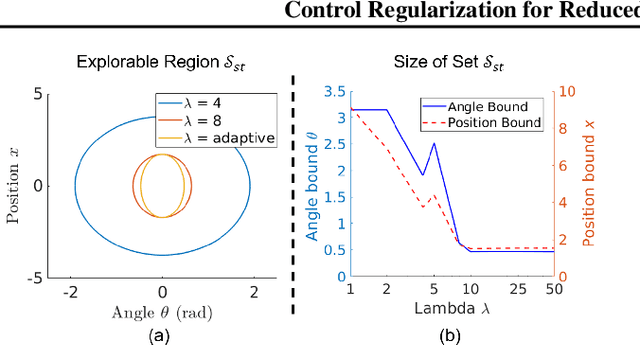
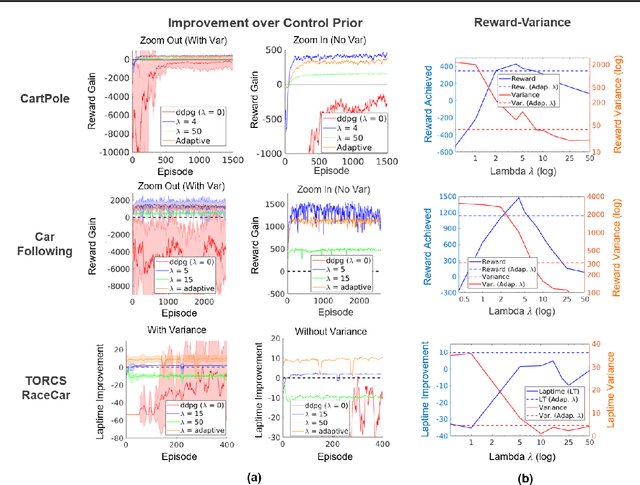
Dealing with high variance is a significant challenge in model-free reinforcement learning (RL). Existing methods are unreliable, exhibiting high variance in performance from run to run using different initializations/seeds. Focusing on problems arising in continuous control, we propose a functional regularization approach to augmenting model-free RL. In particular, we regularize the behavior of the deep policy to be similar to a policy prior, i.e., we regularize in function space. We show that functional regularization yields a bias-variance trade-off, and propose an adaptive tuning strategy to optimize this trade-off. When the policy prior has control-theoretic stability guarantees, we further show that this regularization approximately preserves those stability guarantees throughout learning. We validate our approach empirically on a range of settings, and demonstrate significantly reduced variance, guaranteed dynamic stability, and more efficient learning than deep RL alone.
Representing Formal Languages: A Comparison Between Finite Automata and Recurrent Neural Networks
Feb 27, 2019
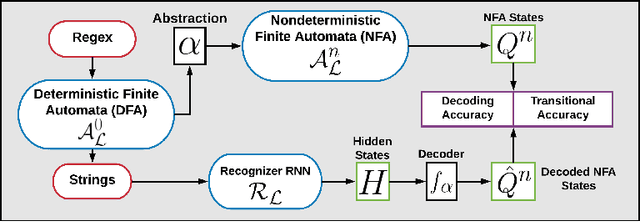

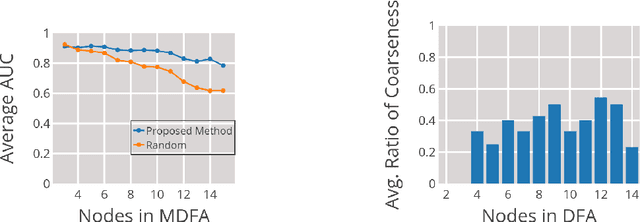
We investigate the internal representations that a recurrent neural network (RNN) uses while learning to recognize a regular formal language. Specifically, we train a RNN on positive and negative examples from a regular language, and ask if there is a simple decoding function that maps states of this RNN to states of the minimal deterministic finite automaton (MDFA) for the language. Our experiments show that such a decoding function indeed exists, and that it maps states of the RNN not to MDFA states, but to states of an {\em abstraction} obtained by clustering small sets of MDFA states into "superstates". A qualitative analysis reveals that the abstraction often has a simple interpretation. Overall, the results suggest a strong structural relationship between internal representations used by RNNs and finite automata, and explain the well-known ability of RNNs to recognize formal grammatical structure.