 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIf an LLM Were a Character, Would It Know Its Own Story? Evaluating Lifelong Learning in LLMs
Mar 30, 2025Large language models (LLMs) can carry out human-like dialogue, but unlike humans, they are stateless due to the superposition property. However, during multi-turn, multi-agent interactions, LLMs begin to exhibit consistent, character-like behaviors, hinting at a form of emergent lifelong learning. Despite this, existing benchmarks often fail to capture these dynamics, primarily focusing on static, open-ended evaluations. To address this gap, we introduce LIFESTATE-BENCH, a benchmark designed to assess lifelong learning in LLMs. It features two episodic datasets: Hamlet and a synthetic script collection, rich in narrative structure and character interactions. Our fact checking evaluation probes models' self-awareness, episodic memory retrieval, and relationship tracking, across both parametric and non-parametric approaches. Experiments on models like Llama3.1-8B, GPT-4-turbo, and DeepSeek R1, we demonstrate that nonparametric methods significantly outperform parametric ones in managing stateful learning. However, all models exhibit challenges with catastrophic forgetting as interactions extend, highlighting the need for further advancements in lifelong learning.
Sketch: A Toolkit for Streamlining LLM Operations
Sep 05, 2024



Large language models (LLMs) represented by GPT family have achieved remarkable success. The characteristics of LLMs lie in their ability to accommodate a wide range of tasks through a generative approach. However, the flexibility of their output format poses challenges in controlling and harnessing the model's outputs, thereby constraining the application of LLMs in various domains. In this work, we present Sketch, an innovative toolkit designed to streamline LLM operations across diverse fields. Sketch comprises the following components: (1) a suite of task description schemas and prompt templates encompassing various NLP tasks; (2) a user-friendly, interactive process for building structured output LLM services tailored to various NLP tasks; (3) an open-source dataset for output format control, along with tools for dataset construction; and (4) an open-source model based on LLaMA3-8B-Instruct that adeptly comprehends and adheres to output formatting instructions. We anticipate this initiative to bring considerable convenience to LLM users, achieving the goal of ''plug-and-play'' for various applications. The components of Sketch will be progressively open-sourced at https://github.com/cofe-ai/Sketch.
Open-domain Implicit Format Control for Large Language Model Generation
Aug 08, 2024



Controlling the format of outputs generated by large language models (LLMs) is a critical functionality in various applications. Current methods typically employ constrained decoding with rule-based automata or fine-tuning with manually crafted format instructions, both of which struggle with open-domain format requirements. To address this limitation, we introduce a novel framework for controlled generation in LLMs, leveraging user-provided, one-shot QA pairs. This study investigates LLMs' capabilities to follow open-domain, one-shot constraints and replicate the format of the example answers. We observe that this is a non-trivial problem for current LLMs. We also develop a dataset collection methodology for supervised fine-tuning that enhances the open-domain format control of LLMs without degrading output quality, as well as a benchmark on which we evaluate both the helpfulness and format correctness of LLM outputs. The resulting datasets, named OIFC-SFT, along with the related code, will be made publicly available at https://github.com/cofe-ai/OIFC.
52B to 1T: Lessons Learned via Tele-FLM Series
Jul 03, 2024



Large Language Models (LLMs) represent a significant stride toward Artificial General Intelligence. As scaling laws underscore the potential of increasing model sizes, the academic community has intensified its investigations into LLMs with capacities exceeding 50 billion parameters. This technical report builds on our prior work with Tele-FLM (also known as FLM-2), a publicly available 52-billion-parameter model. We delve into two primary areas: we first discuss our observation of Supervised Fine-tuning (SFT) on Tele-FLM-52B, which supports the "less is more" approach for SFT data construction; second, we demonstrate our experiments and analyses on the best practices for progressively growing a model from 52 billion to 102 billion, and subsequently to 1 trillion parameters. We will open-source a 1T model checkpoint, namely Tele-FLM-1T, to advance further training and research.
Tele-FLM Technical Report
Apr 25, 2024



Large language models (LLMs) have showcased profound capabilities in language understanding and generation, facilitating a wide array of applications. However, there is a notable paucity of detailed, open-sourced methodologies on efficiently scaling LLMs beyond 50 billion parameters with minimum trial-and-error cost and computational resources. In this report, we introduce Tele-FLM (aka FLM-2), a 52B open-sourced multilingual large language model that features a stable, efficient pre-training paradigm and enhanced factual judgment capabilities. Tele-FLM demonstrates superior multilingual language modeling abilities, measured by BPB on textual corpus. Besides, in both English and Chinese foundation model evaluation, it is comparable to strong open-sourced models that involve larger pre-training FLOPs, such as Llama2-70B and DeepSeek-67B. In addition to the model weights, we share the core designs, engineering practices, and training details, which we expect to benefit both the academic and industrial communities.
CatCode: A Comprehensive Evaluation Framework for LLMs On the Mixture of Code and Text
Mar 04, 2024Large language models (LLMs) such as ChatGPT are increasingly proficient in understanding and generating a mixture of code and text. Evaluation based on such $\textit{mixture}$ can lead to a more comprehensive understanding of the models' abilities in solving coding problems. However, in this context, current evaluation methods are either limited in task coverage or lack standardization. To address this issue, we propose using category theory as a framework for evaluation. Specifically, morphisms within a code category can represent code debugging and transformation, functors between two categories represent code translation, and functors between a code category and a natural language category represent code generation, explanation, and reproduction. We present an automatic evaluation framework called $\textbf{CatCode}$ ($\textbf{Cat}$egory $\textbf{Code}$) that can comprehensively assess the coding abilities of LLMs, including ChatGPT, Text-Davinci, and CodeGeeX.
FLM-101B: An Open LLM and How to Train It with $100K Budget
Sep 17, 2023Large language models (LLMs) have achieved remarkable success in NLP and multimodal tasks, among others. Despite these successes, two main challenges remain in developing LLMs: (i) high computational cost, and (ii) fair and objective evaluations. In this paper, we report a solution to significantly reduce LLM training cost through a growth strategy. We demonstrate that a 101B-parameter LLM with 0.31T tokens can be trained with a budget of 100K US dollars. Inspired by IQ tests, we also consolidate an additional range of evaluations on top of existing evaluations that focus on knowledge-oriented abilities. These IQ evaluations include symbolic mapping, rule understanding, pattern mining, and anti-interference. Such evaluations minimize the potential impact of memorization. Experimental results show that our model, named FLM-101B, trained with a budget of 100K US dollars, achieves performance comparable to powerful and well-known models, e.g., GPT-3 and GLM-130B, especially on the additional range of IQ evaluations. The checkpoint of FLM-101B is released at https://huggingface.co/CofeAI/FLM-101B.
2x Faster Language Model Pre-training via Masked Structural Growth
May 04, 2023Acceleration of large language model pre-training is a critical issue in present NLP research. In this paper, we focus on speeding up pre-training by progressively growing from a small Transformer structure to a large one. There are two main research problems related to progressive growth: growth schedule and growth operator. For growth schedule, existing work has explored multi-stage expansion of depth and feedforward layers. However, the impact of each dimension on the schedule's efficiency is still an open question. For growth operator, existing work relies on the initialization of new weights to inherit knowledge, and achieve only non-strict function preservation, limiting further optimization of training dynamics. To address these issues, we propose Masked Structural Growth (MSG), including growth schedules involving all possible dimensions and strictly function-preserving growth operators that is independent of the initialization of new weights. Experiments show that MSG is significantly faster than related work: we achieve a speed-up of 80% for Bert-base and 120% for Bert-large pre-training. Moreover, MSG is able to improve fine-tuning performances at the same time.
Research without Re-search: Maximal Update Parametrization Yields Accurate Loss Prediction across Scales
Apr 29, 2023



As language models scale up, it becomes increasingly expensive to verify research ideas because conclusions on small models do not trivially transfer to large ones. A possible solution is to establish a generic system that directly predicts some metrics for large models solely based on the results and hyperparameters from small models. Existing methods based on scaling laws require hyperparameter search on the largest models, which is impractical with limited resources. We address this issue by presenting our discoveries indicating that Maximal Update parametrization (muP) enables accurate fitting of scaling laws for hyperparameters close to common loss basins, without any search. Thus, different models can be directly compared on large scales with loss prediction even before the training starts. We propose a new paradigm as a first step towards reliable academic research for any model scale without heavy computation. Code will be publicly available shortly.
MUSER: MUltimodal Stress Detection using Emotion Recognition as an Auxiliary Task
May 17, 2021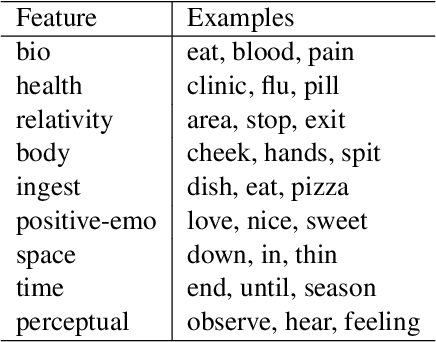
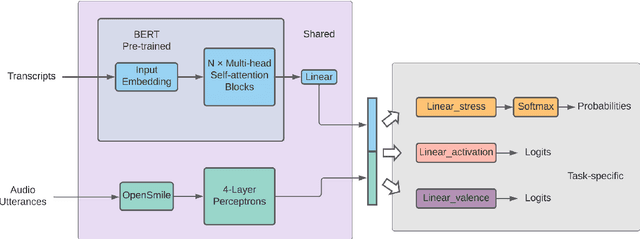
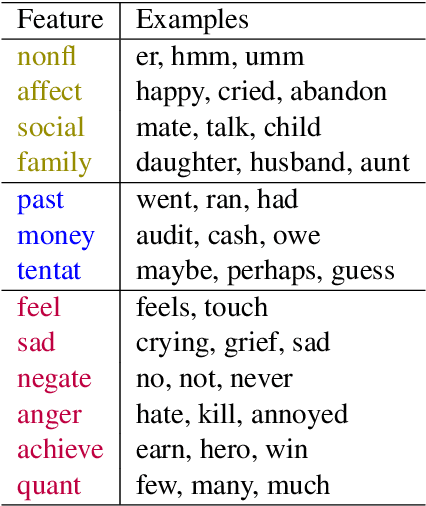
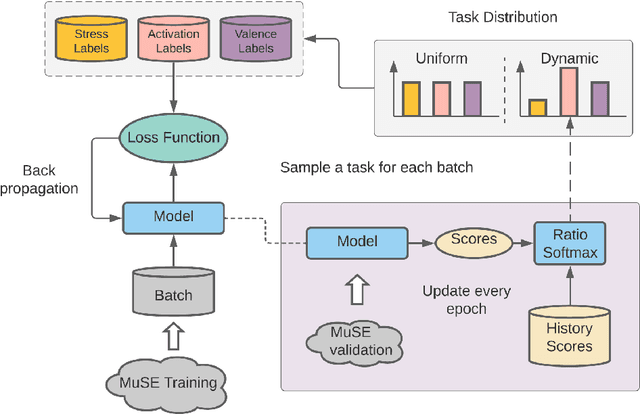
The capability to automatically detect human stress can benefit artificial intelligent agents involved in affective computing and human-computer interaction. Stress and emotion are both human affective states, and stress has proven to have important implications on the regulation and expression of emotion. Although a series of methods have been established for multimodal stress detection, limited steps have been taken to explore the underlying inter-dependence between stress and emotion. In this work, we investigate the value of emotion recognition as an auxiliary task to improve stress detection. We propose MUSER -- a transformer-based model architecture and a novel multi-task learning algorithm with speed-based dynamic sampling strategy. Evaluations on the Multimodal Stressed Emotion (MuSE) dataset show that our model is effective for stress detection with both internal and external auxiliary tasks, and achieves state-of-the-art results.