 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWildQA: In-the-Wild Video Question Answering
Sep 14, 2022

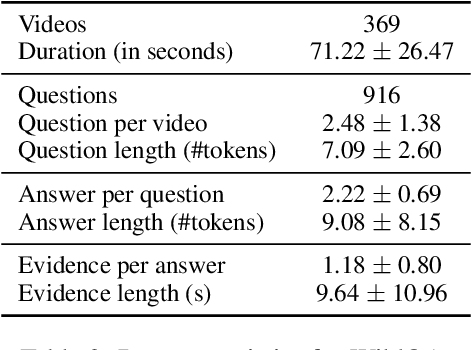
Existing video understanding datasets mostly focus on human interactions, with little attention being paid to the "in the wild" settings, where the videos are recorded outdoors. We propose WILDQA, a video understanding dataset of videos recorded in outside settings. In addition to video question answering (Video QA), we also introduce the new task of identifying visual support for a given question and answer (Video Evidence Selection). Through evaluations using a wide range of baseline models, we show that WILDQA poses new challenges to the vision and language research communities. The dataset is available at https://lit.eecs.umich.edu/wildqa/.
MUSER: MUltimodal Stress Detection using Emotion Recognition as an Auxiliary Task
May 17, 2021
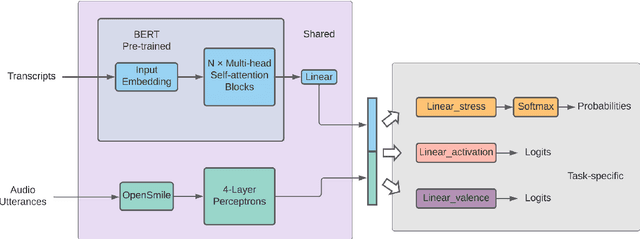
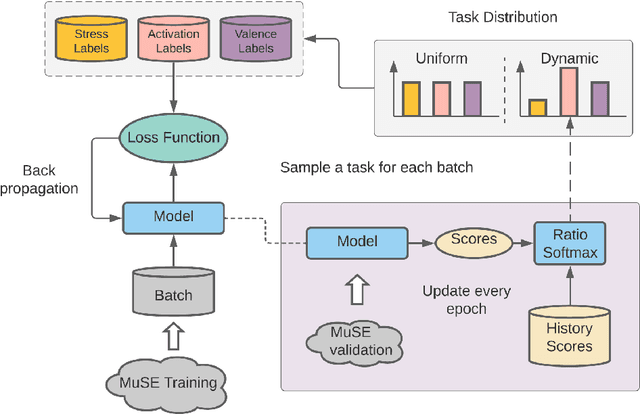
The capability to automatically detect human stress can benefit artificial intelligent agents involved in affective computing and human-computer interaction. Stress and emotion are both human affective states, and stress has proven to have important implications on the regulation and expression of emotion. Although a series of methods have been established for multimodal stress detection, limited steps have been taken to explore the underlying inter-dependence between stress and emotion. In this work, we investigate the value of emotion recognition as an auxiliary task to improve stress detection. We propose MUSER -- a transformer-based model architecture and a novel multi-task learning algorithm with speed-based dynamic sampling strategy. Evaluations on the Multimodal Stressed Emotion (MuSE) dataset show that our model is effective for stress detection with both internal and external auxiliary tasks, and achieves state-of-the-art results.
MuSE-ing on the Impact of Utterance Ordering On Crowdsourced Emotion Annotations
Mar 27, 2019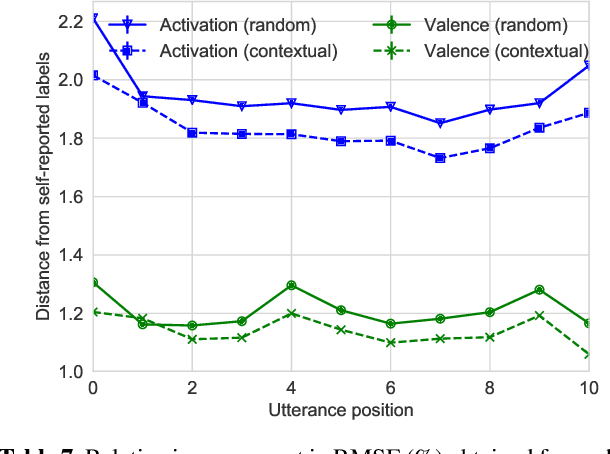
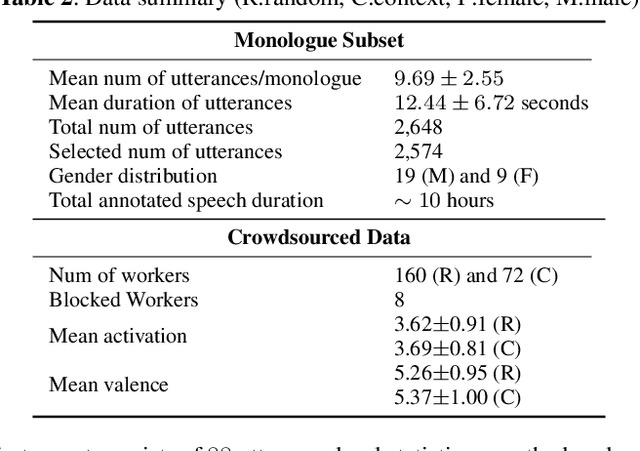

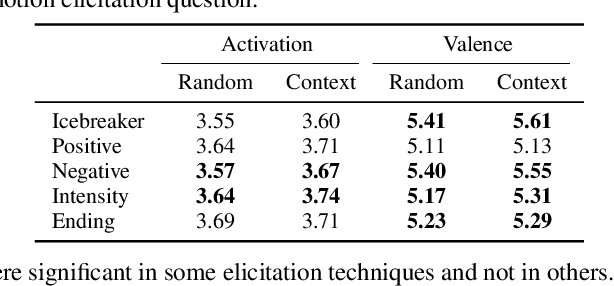
Emotion recognition algorithms rely on data annotated with high quality labels. However, emotion expression and perception are inherently subjective. There is generally not a single annotation that can be unambiguously declared "correct". As a result, annotations are colored by the manner in which they were collected. In this paper, we conduct crowdsourcing experiments to investigate this impact on both the annotations themselves and on the performance of these algorithms. We focus on one critical question: the effect of context. We present a new emotion dataset, Multimodal Stressed Emotion (MuSE), and annotate the dataset using two conditions: randomized, in which annotators are presented with clips in random order, and contextualized, in which annotators are presented with clips in order. We find that contextual labeling schemes result in annotations that are more similar to a speaker's own self-reported labels and that labels generated from randomized schemes are most easily predictable by automated systems.