 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHG-Bench: A Benchmark for Multi-Page Handwritten Answer-Region Grounding in Automated Homework Assessment
Jun 24, 2026Automated homework assessment depends not only on recognizing student answers, but also on accurately locating where each answer and each intermediate reasoning step appears in noisy, multi-page handwritten work. This paper addresses the missing evaluation setting of page-aware, two-level answer-region grounding: given a sequence of homework page images, a model must localize complete answer regions and their ordered step-level subregions. We introduce HG-Bench, a benchmark of 500 human-annotated K-12 homework samples curated from a 1,489,278-image source pool, with question-level and step-level boxes linked by a hierarchical containment constraint. HG-Bench is paired with a page-aware evaluation protocol that separately measures complete-answer localization (FA) and step-level decomposition (FSm), revealing whether models truly ground the spatial structure of student reasoning rather than merely parse visible text. Across frontier closed-source APIs and competitive open-weight VLMs, no zero-shot system exceeds 55.22% on FA or 48.22% on FSm, while a GLM-4.6V 9B reference model fine-tuned on ~10k in-domain examples reaches 74.97/72.26. These results identify step-level handwritten grounding as a concrete capability gap and provide a reproducible benchmark, evaluation protocol, and trained reference point for future work on automated homework assessment.
An LMM for Precisely Grounding Elements in Documents
Jun 23, 2026Visual grounding in documents is a crucial ability for Large Multimodal Models (LMMs) in areas such as document understanding, deep research and document error detection. However, existing approaches exhibit poor grounding precision in text-rich document images, often failing to accurately locate the critical document elements needed for reliable reasoning. To address this gap, we introduce PreciseDoc, an LMM specifically designed for precise element grounding and can be further optimized for Document VQA tasks. Specifically, to enhance the basic localization capability, we construct challenging training data by two pipelines capable of mass-producing high-quality documents with paired metadata of fine-grained coordinates, including synthetic hand-filled documents with camera effects. The model develops more real-world functions beyond straightforward localization of single text, such as locating personal information from CVs. Furthermore, we introduce a training paradigm for visual grounded reasoning where the grounding and reasoning are supervised jointly with reinforcement learning to improve the contribution of the grounded evidence. A comprehensive evaluation on various benchmarks demonstrates the advantage of the proposed data and methods in document spatial grounding and document understanding.
Attention-Spectrum Regularization for Replay-Free Continual Multimodal LLMs
Jun 22, 2026Multimodal large language models (MLLMs) are increasingly required to adapt to non-stationary streams of visual domains, question types, and user instructions, yet continual fine-tuning often causes severe forgetting of previously acquired multimodal skills. Existing continual vision-language methods mainly preserve outputs, replay data or pseudo-data, regularize embedding geometry, or allocate task-specific parameters, but they provide limited control over how internal cross-modal attention patterns supporting old skills drift during adaptation. We propose Attention-Spectrum Regularization (ASR), a replay-free continual learning framework that preserves skill-conditioned structures of cross-modal attention. ASR treats cross-attention maps as two-dimensional signals, summarizes their scale and directional properties into compact spectral statistics, and stores only skill-wise prototype distributions instead of replaying past image-question pairs, generated pseudo-examples, or old-stage teacher snapshots. In later stages, a phase-invariant spectral regularizer constrains harmful drift of these prototypes while allowing instance-level attention to adapt to new tasks. We provide theoretical analysis showing that skill-conditioned spectral drift controls forgetting under a spectral sufficiency assumption, and that Fourier power spectra are stable to spatial translations and bounded perturbations. Experiments on continual VQA and multimodal instruction-tuning benchmarks, including VQA v2, VQACL, CLT-VQA, CoIN, and UCIT, show that ASR consistently improves final performance and reduces forgetting over strong replay-, regularization-, and adapter-based baselines. Preserving skill-level attention structure is an effective and lightweight mechanism for continual MLLMs. Code is available at https://github.com/Creative-zcx/attention-spectrum-replay
ScDiVa: Masked Discrete Diffusion for Joint Modeling of Single-Cell Identity and Expression
Feb 03, 2026Single-cell RNA-seq profiles are high-dimensional, sparse, and unordered, causing autoregressive generation to impose an artificial ordering bias and suffer from error accumulation. To address this, we propose scDiVa, a masked discrete diffusion foundation model that aligns generation with the dropout-like corruption process by defining a continuous-time forward masking mechanism in token space. ScDiVa features a bidirectional denoiser that jointly models discrete gene identities and continuous values, utilizing entropy-normalized serialization and a latent anchor token to maximize information efficiency and preserve global cell identity. The model is trained via depth-invariant time sampling and a dual denoising objective to simulate varying sparsity levels while ensuring precise recovery of both identity and magnitude. Pre-trained on 59 million cells, scDiVa achieves strong transfer performance across major benchmarks, including batch integration, cell type annotation, and perturbation response prediction. These results suggest that masked discrete diffusion serves as a biologically coherent and effective alternative to autoregression.
$λ$-GRPO: Unifying the GRPO Frameworks with Learnable Token Preferences
Oct 08, 2025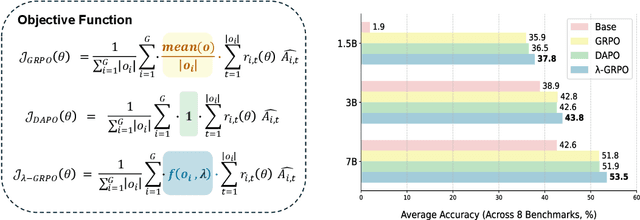
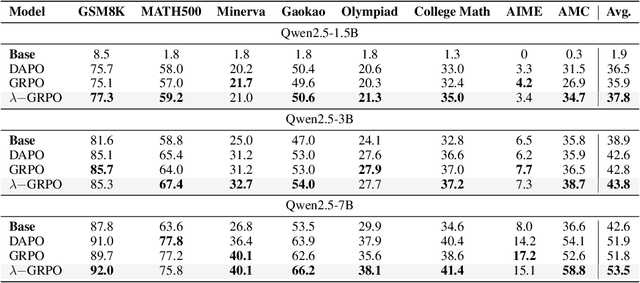
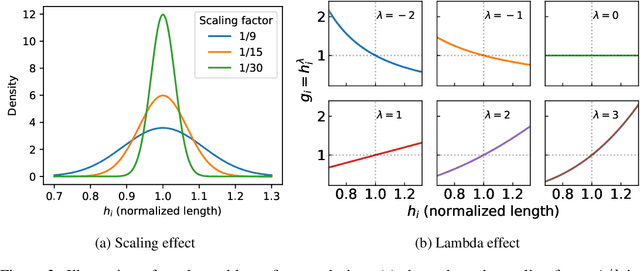

Reinforcement Learning with Human Feedback (RLHF) has been the dominant approach for improving the reasoning capabilities of Large Language Models (LLMs). Recently, Reinforcement Learning with Verifiable Rewards (RLVR) has simplified this paradigm by replacing the reward and value models with rule-based verifiers. A prominent example is Group Relative Policy Optimization (GRPO). However, GRPO inherently suffers from a length bias, since the same advantage is uniformly assigned to all tokens of a response. As a result, longer responses distribute the reward over more tokens and thus contribute disproportionately to gradient updates. Several variants, such as DAPO and Dr. GRPO, modify the token-level aggregation of the loss, yet these methods remain heuristic and offer limited interpretability regarding their implicit token preferences. In this work, we explore the possibility of allowing the model to learn its own token preference during optimization. We unify existing frameworks under a single formulation and introduce a learnable parameter $\lambda$ that adaptively controls token-level weighting. We use $\lambda$-GRPO to denote our method, and we find that $\lambda$-GRPO achieves consistent improvements over vanilla GRPO and DAPO on multiple mathematical reasoning benchmarks. On Qwen2.5 models with 1.5B, 3B, and 7B parameters, $\lambda$-GRPO improves average accuracy by $+1.9\%$, $+1.0\%$, and $+1.7\%$ compared to GRPO, respectively. Importantly, these gains come without any modifications to the training data or additional computational cost, highlighting the effectiveness and practicality of learning token preferences.