 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHW-NAS-Bench:Hardware-Aware Neural Architecture Search Benchmark
Mar 19, 2021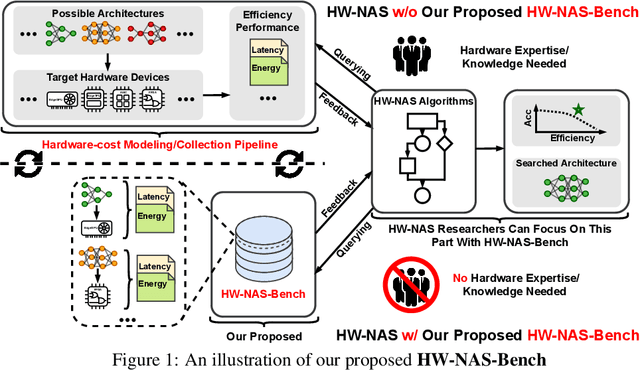
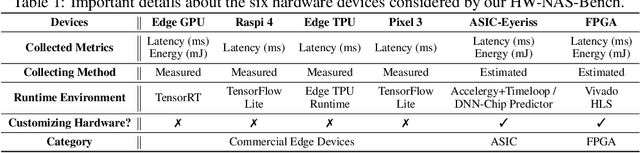
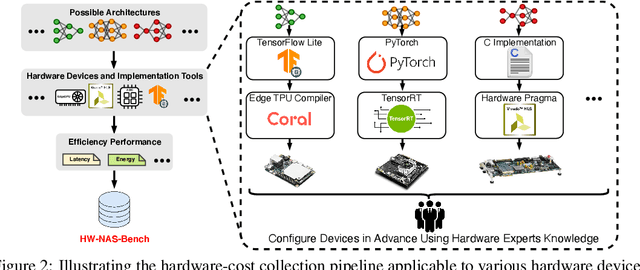

HardWare-aware Neural Architecture Search (HW-NAS) has recently gained tremendous attention by automating the design of DNNs deployed in more resource-constrained daily life devices. Despite its promising performance, developing optimal HW-NAS solutions can be prohibitively challenging as it requires cross-disciplinary knowledge in the algorithm, micro-architecture, and device-specific compilation. First, to determine the hardware-cost to be incorporated into the NAS process, existing works mostly adopt either pre-collected hardware-cost look-up tables or device-specific hardware-cost models. Both of them limit the development of HW-NAS innovations and impose a barrier-to-entry to non-hardware experts. Second, similar to generic NAS, it can be notoriously difficult to benchmark HW-NAS algorithms due to their significant required computational resources and the differences in adopted search spaces, hyperparameters, and hardware devices. To this end, we develop HW-NAS-Bench, the first public dataset for HW-NAS research which aims to democratize HW-NAS research to non-hardware experts and make HW-NAS research more reproducible and accessible. To design HW-NAS-Bench, we carefully collected the measured/estimated hardware performance of all the networks in the search spaces of both NAS-Bench-201 and FBNet, on six hardware devices that fall into three categories (i.e., commercial edge devices, FPGA, and ASIC). Furthermore, we provide a comprehensive analysis of the collected measurements in HW-NAS-Bench to provide insights for HW-NAS research. Finally, we demonstrate exemplary user cases to (1) show that HW-NAS-Bench allows non-hardware experts to perform HW-NAS by simply querying it and (2) verify that dedicated device-specific HW-NAS can indeed lead to optimal accuracy-cost trade-offs. The codes and all collected data are available at https://github.com/RICE-EIC/HW-NAS-Bench.
GEBT: Drawing Early-Bird Tickets in Graph Convolutional Network Training
Mar 01, 2021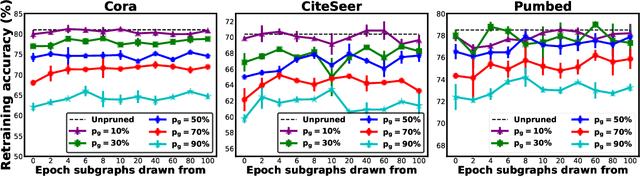
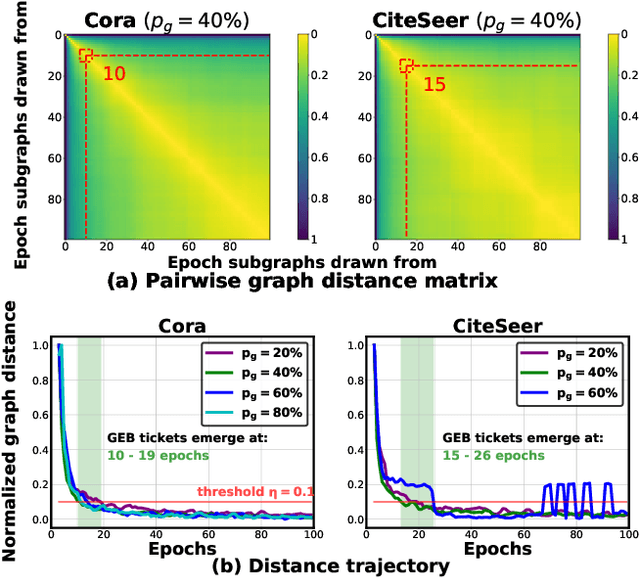
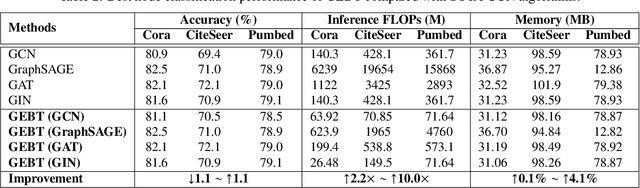
Graph Convolutional Networks (GCNs) have emerged as the state-of-the-art deep learning model for representation learning on graphs. However, it remains notoriously challenging to train and inference GCNs over large graph datasets, limiting their application to large real-world graphs and hindering the exploration of deeper and more sophisticated GCN graphs. This is because as the graph size grows, the sheer number of node features and the large adjacency matrix can easily explode the required memory and data movements. To tackle the aforementioned challenge, we explore the possibility of drawing lottery tickets when sparsifying GCN graphs, i.e., subgraphs that largely shrink the adjacency matrix yet are capable of achieving accuracy comparable to or even better than their corresponding full graphs. Specifically, we for the first time discover the existence of graph early-bird (GEB) tickets that emerge at the very early stage when sparsifying GCN graphs, and propose a simple yet effective detector to automatically identify the emergence of such GEB tickets. Furthermore, we develop a generic efficient GCN training framework dubbed GEBT that can significantly boost the efficiency of GCN training by (1) drawing joint early-bird tickets between the GCN graphs and models and (2) enabling simultaneously sparsifying both GCN graphs and models, paving the way for training and inferencing large GCN graphs to handle real-world graph datasets. Experiments on various GCN models and datasets consistently validate our GEB finding and the effectiveness of our GEBT, e.g., our GEBT achieves up to 80.2% ~ 85.6% and 84.6% ~ 87.5% savings of GCN training and inference costs while leading to a comparable or even better accuracy as compared to state-of-the-art methods. Code available at https://github.com/RICE-EIC/GEBT
CPT: Efficient Deep Neural Network Training via Cyclic Precision
Jan 25, 2021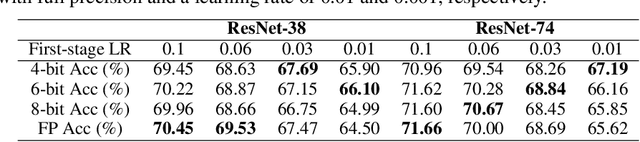
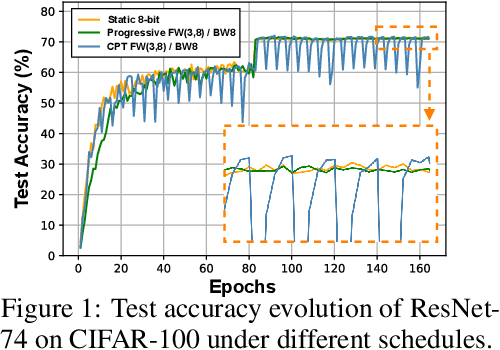
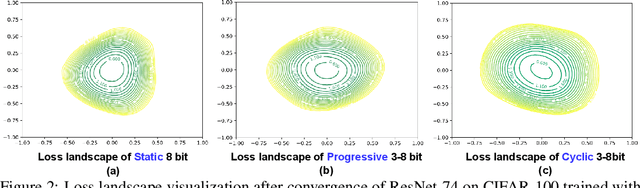
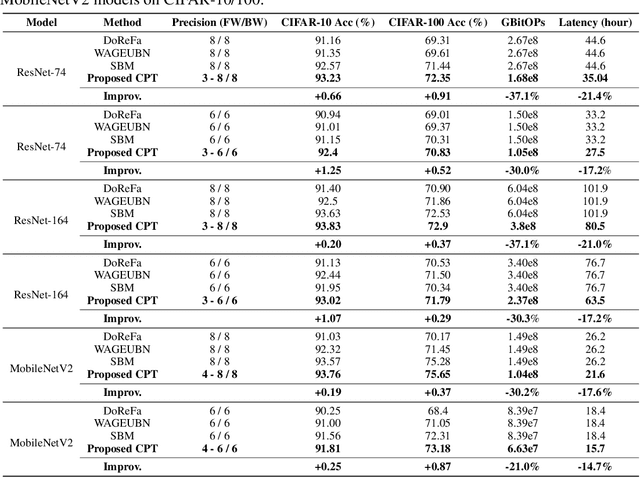
Low-precision deep neural network (DNN) training has gained tremendous attention as reducing precision is one of the most effective knobs for boosting DNNs' training time/energy efficiency. In this paper, we attempt to explore low-precision training from a new perspective as inspired by recent findings in understanding DNN training: we conjecture that DNNs' precision might have a similar effect as the learning rate during DNN training, and advocate dynamic precision along the training trajectory for further boosting the time/energy efficiency of DNN training. Specifically, we propose Cyclic Precision Training (CPT) to cyclically vary the precision between two boundary values which can be identified using a simple precision range test within the first few training epochs. Extensive simulations and ablation studies on five datasets and ten models demonstrate that CPT's effectiveness is consistent across various models/tasks (including classification and language modeling). Furthermore, through experiments and visualization we show that CPT helps to (1) converge to a wider minima with a lower generalization error and (2) reduce training variance which we believe opens up a new design knob for simultaneously improving the optimization and efficiency of DNN training. Our codes are available at: https://github.com/RICE-EIC/CPT.
Max-Affine Spline Insights Into Deep Network Pruning
Jan 07, 2021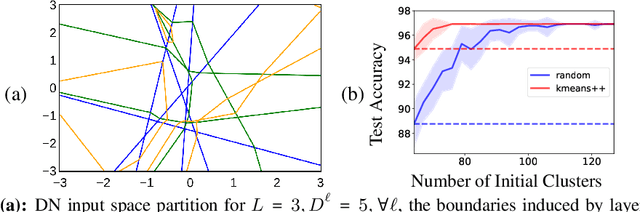
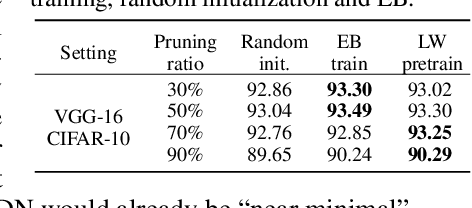
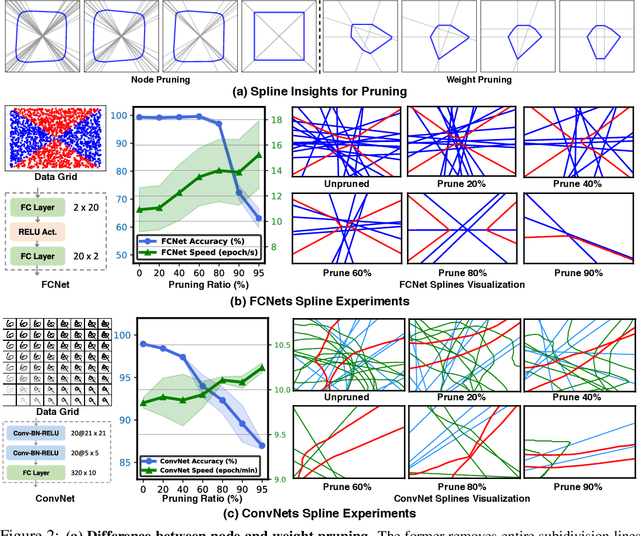
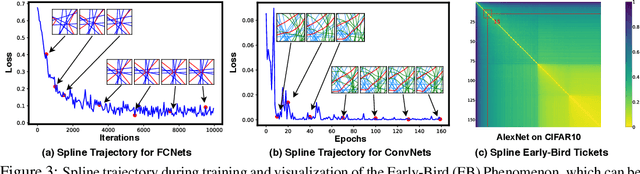
In this paper, we study the importance of pruning in Deep Networks (DNs) and motivate it based on the current absence of data aware weight initialization. Current DN initializations, focusing primarily at maintaining first order statistics of the feature maps through depth, force practitioners to overparametrize a model in order to reach high performances. This overparametrization can then be pruned a posteriori, leading to a phenomenon known as "winning tickets". However, the pruning literature still relies on empirical investigations, lacking a theoretical understanding of (1) how pruning affects the decision boundary, (2) how to interpret pruning, (3) how to design principled pruning techniques, and (4) how to theoretically study pruning. To tackle those questions, we propose to employ recent advances in the theoretical analysis of Continuous Piecewise Affine (CPA) DNs. From this viewpoint, we can study the DNs' input space partitioning and detect the early-bird (EB) phenomenon, guide practitioners by identifying when to stop the first training step, provide interpretability into current pruning techniques, and develop a principled pruning criteria towards efficient DN training. Finally, we conduct extensive experiments to show the effectiveness of the proposed spline pruning criteria in terms of both layerwise and global pruning over state-of-the-art pruning methods.
SmartDeal: Re-Modeling Deep Network Weights for Efficient Inference and Training
Jan 04, 2021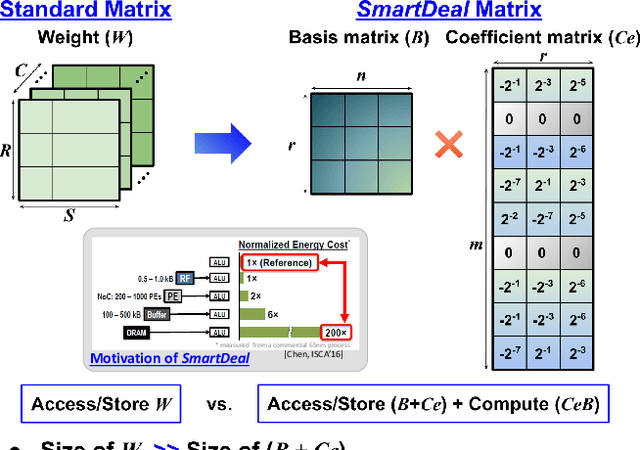

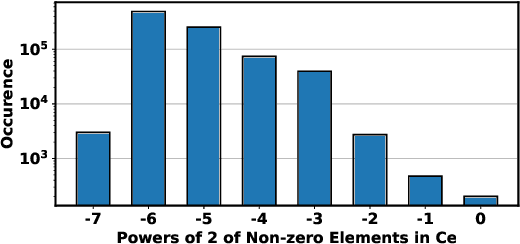
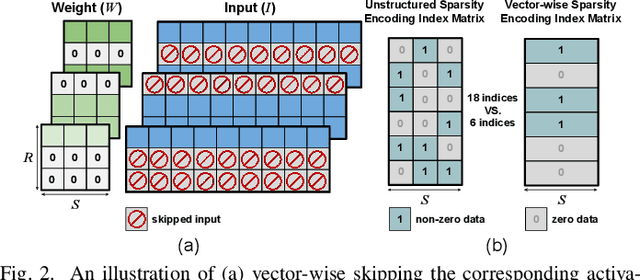
The record-breaking performance of deep neural networks (DNNs) comes with heavy parameterization, leading to external dynamic random-access memory (DRAM) for storage. The prohibitive energy of DRAM accesses makes it non-trivial to deploy DNN on resource-constrained devices, calling for minimizing the weight and data movements to improve the energy efficiency. We present SmartDeal (SD), an algorithm framework to trade higher-cost memory storage/access for lower-cost computation, in order to aggressively boost the storage and energy efficiency, for both inference and training. The core of SD is a novel weight decomposition with structural constraints, carefully crafted to unleash the hardware efficiency potential. Specifically, we decompose each weight tensor as the product of a small basis matrix and a large structurally sparse coefficient matrix whose non-zeros are quantized to power-of-2. The resulting sparse and quantized DNNs enjoy greatly reduced energy for data movement and weight storage, incurring minimal overhead to recover the original weights thanks to the sparse bit-operations and cost-favorable computations. Beyond inference, we take another leap to embrace energy-efficient training, introducing innovative techniques to address the unique roadblocks arising in training while preserving the SD structures. We also design a dedicated hardware accelerator to fully utilize the SD structure to improve the real energy efficiency and latency. We conduct experiments on both multiple tasks, models and datasets in different settings. Results show that: 1) applied to inference, SD achieves up to 2.44x energy efficiency as evaluated via real hardware implementations; 2) applied to training, SD leads to 10.56x and 4.48x reduction in the storage and training energy, with negligible accuracy loss compared to state-of-the-art training baselines. Our source codes are available online.
Auto-Agent-Distiller: Towards Efficient Deep Reinforcement Learning Agents via Neural Architecture Search
Dec 25, 2020
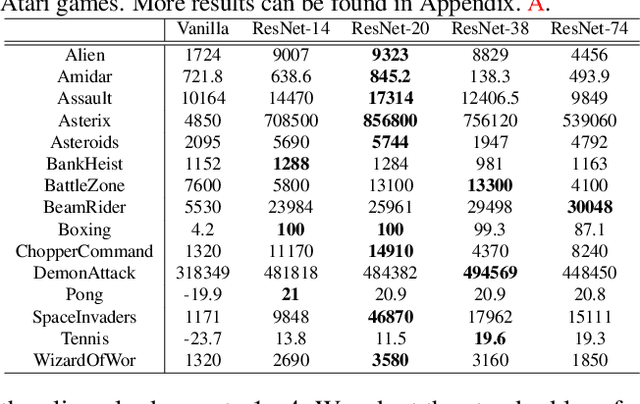
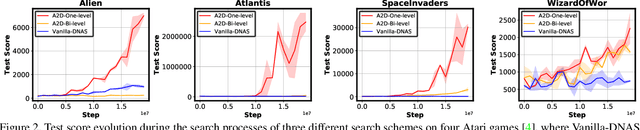
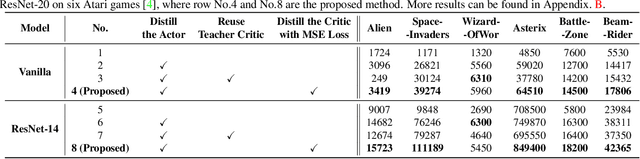
AlphaGo's astonishing performance has ignited an explosive interest in developing deep reinforcement learning (DRL) for numerous real-world applications, such as intelligent robotics. However, the often prohibitive complexity of DRL stands at the odds with the required real-time control and constrained resources in many DRL applications, limiting the great potential of DRL powered intelligent devices. While substantial efforts have been devoted to compressing other deep learning models, existing works barely touch the surface of compressing DRL. In this work, we first identify that there exists an optimal model size of DRL that can maximize both the test scores and efficiency, motivating the need for task-specific DRL agents. We therefore propose an Auto-Agent-Distiller (A2D) framework, which to our best knowledge is the first neural architecture search (NAS) applied to DRL to automatically search for the optimal DRL agents for various tasks that optimize both the test scores and efficiency. Specifically, we demonstrate that vanilla NAS can easily fail in searching for the optimal agents, due to its resulting high variance in DRL training stability, and then develop a novel distillation mechanism to distill the knowledge from both the teacher agent's actor and critic to stabilize the searching process and improve the searched agents' optimality. Extensive experiments and ablation studies consistently validate our findings and the advantages and general applicability of our A2D, outperforming manually designed DRL in both the test scores and efficiency. All the codes will be released upon acceptance.
FracTrain: Fractionally Squeezing Bit Savings Both Temporally and Spatially for Efficient DNN Training
Dec 24, 2020
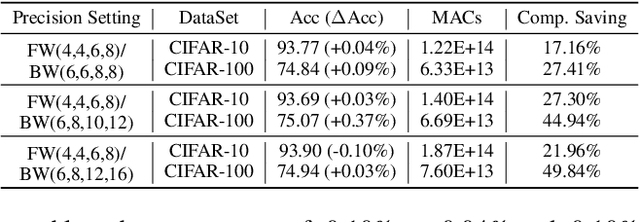
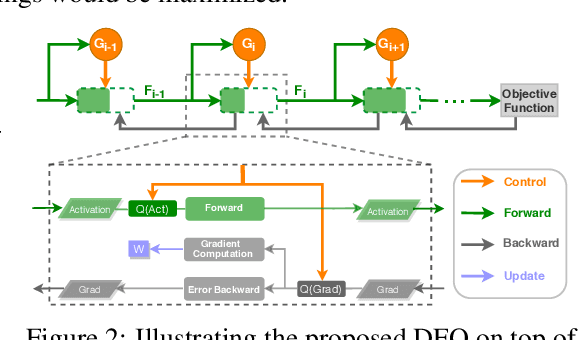

Recent breakthroughs in deep neural networks (DNNs) have fueled a tremendous demand for intelligent edge devices featuring on-site learning, while the practical realization of such systems remains a challenge due to the limited resources available at the edge and the required massive training costs for state-of-the-art (SOTA) DNNs. As reducing precision is one of the most effective knobs for boosting training time/energy efficiency, there has been a growing interest in low-precision DNN training. In this paper, we explore from an orthogonal direction: how to fractionally squeeze out more training cost savings from the most redundant bit level, progressively along the training trajectory and dynamically per input. Specifically, we propose FracTrain that integrates (i) progressive fractional quantization which gradually increases the precision of activations, weights, and gradients that will not reach the precision of SOTA static quantized DNN training until the final training stage, and (ii) dynamic fractional quantization which assigns precisions to both the activations and gradients of each layer in an input-adaptive manner, for only "fractionally" updating layer parameters. Extensive simulations and ablation studies (six models, four datasets, and three training settings including standard, adaptation, and fine-tuning) validate the effectiveness of FracTrain in reducing computational cost and hardware-quantified energy/latency of DNN training while achieving a comparable or better (-0.12%~+1.87%) accuracy. For example, when training ResNet-74 on CIFAR-10, FracTrain achieves 77.6% and 53.5% computational cost and training latency savings, respectively, compared with the best SOTA baseline, while achieving a comparable (-0.07%) accuracy. Our codes are available at: https://github.com/RICE-EIC/FracTrain.
DNA: Differentiable Network-Accelerator Co-Search
Oct 28, 2020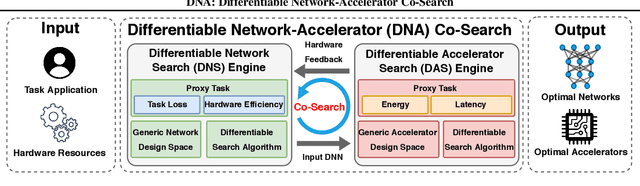

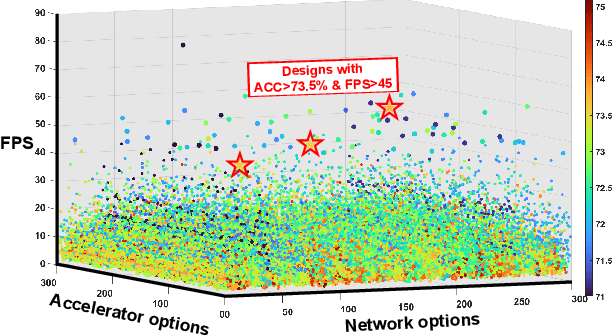
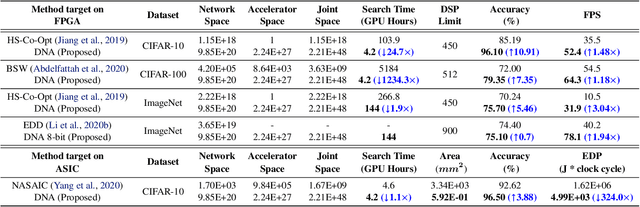
Powerful yet complex deep neural networks (DNNs) have fueled a booming demand for efficient DNN solutions to bring DNN-powered intelligence into numerous applications. Jointly optimizing the networks and their accelerators are promising in providing optimal performance. However, the great potential of such solutions have yet to be unleashed due to the challenge of simultaneously exploring the vast and entangled, yet different design spaces of the networks and their accelerators. To this end, we propose DNA, a Differentiable Network-Accelerator co-search framework for automatically searching for matched networks and accelerators to maximize both the task accuracy and acceleration efficiency. Specifically, DNA integrates two enablers: (1) a generic design space for DNN accelerators that is applicable to both FPGA- and ASIC-based DNN accelerators and compatible with DNN frameworks such as PyTorch to enable algorithmic exploration for more efficient DNNs and their accelerators; and (2) a joint DNN network and accelerator co-search algorithm that enables simultaneously searching for optimal DNN structures and their accelerators' micro-architectures and mapping methods to maximize both the task accuracy and acceleration efficiency. Experiments and ablation studies based on FPGA measurements and ASIC synthesis show that the matched networks and accelerators generated by DNA consistently outperform state-of-the-art (SOTA) DNNs and DNN accelerators (e.g., 3.04x better FPS with a 5.46% higher accuracy on ImageNet), while requiring notably reduced search time (up to 1234.3x) over SOTA co-exploration methods, when evaluated over ten SOTA baselines on three datasets. All codes will be released upon acceptance.
ShiftAddNet: A Hardware-Inspired Deep Network
Oct 24, 2020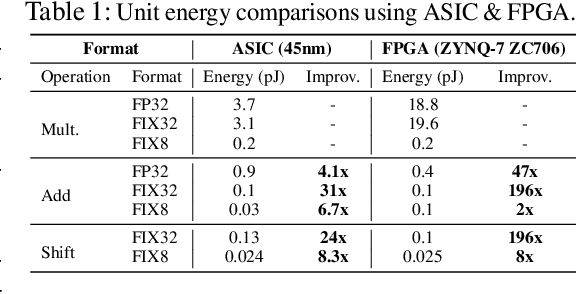
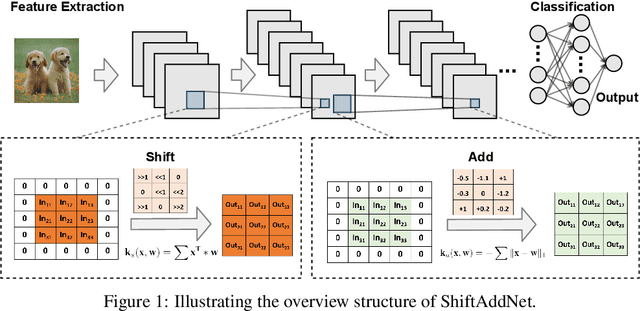
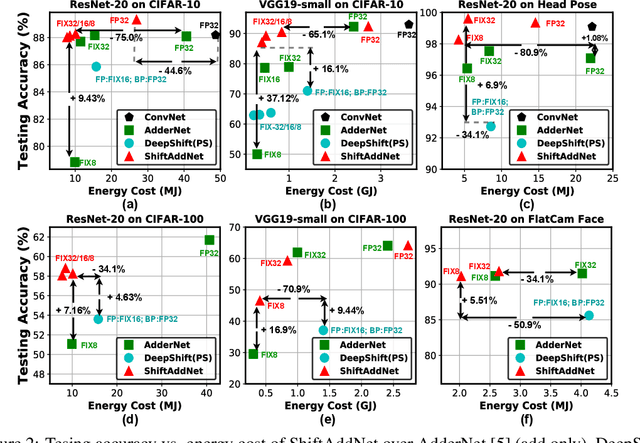

Multiplication (e.g., convolution) is arguably a cornerstone of modern deep neural networks (DNNs). However, intensive multiplications cause expensive resource costs that challenge DNNs' deployment on resource-constrained edge devices, driving several attempts for multiplication-less deep networks. This paper presented ShiftAddNet, whose main inspiration is drawn from a common practice in energy-efficient hardware implementation, that is, multiplication can be instead performed with additions and logical bit-shifts. We leverage this idea to explicitly parameterize deep networks in this way, yielding a new type of deep network that involves only bit-shift and additive weight layers. This hardware-inspired ShiftAddNet immediately leads to both energy-efficient inference and training, without compromising the expressive capacity compared to standard DNNs. The two complementary operation types (bit-shift and add) additionally enable finer-grained control of the model's learning capacity, leading to more flexible trade-off between accuracy and (training) efficiency, as well as improved robustness to quantization and pruning. We conduct extensive experiments and ablation studies, all backed up by our FPGA-based ShiftAddNet implementation and energy measurements. Compared to existing DNNs or other multiplication-less models, ShiftAddNet aggressively reduces over 80% hardware-quantified energy cost of DNNs training and inference, while offering comparable or better accuracies. Codes and pre-trained models are available at https://github.com/RICE-EIC/ShiftAddNet.
AutoGAN-Distiller: Searching to Compress Generative Adversarial Networks
Jul 06, 2020
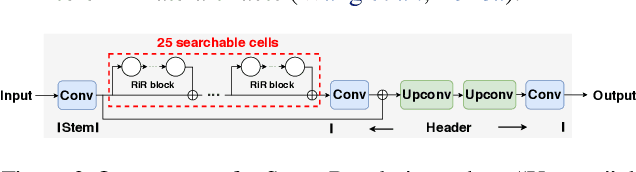
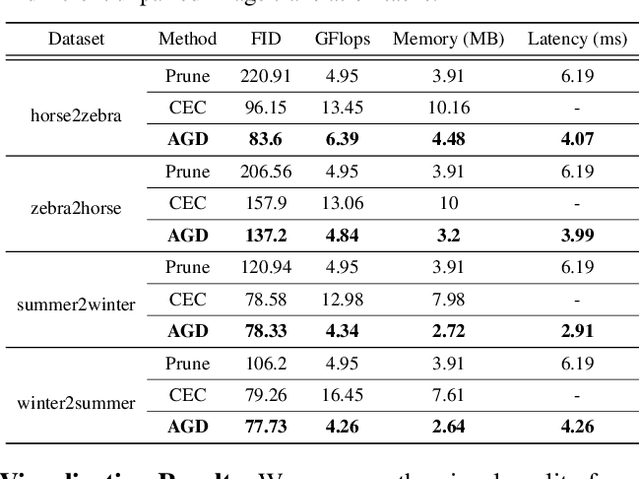

The compression of Generative Adversarial Networks (GANs) has lately drawn attention, due to the increasing demand for deploying GANs into mobile devices for numerous applications such as image translation, enhancement and editing. However, compared to the substantial efforts to compressing other deep models, the research on compressing GANs (usually the generators) remains at its infancy stage. Existing GAN compression algorithms are limited to handling specific GAN architectures and losses. Inspired by the recent success of AutoML in deep compression, we introduce AutoML to GAN compression and develop an AutoGAN-Distiller (AGD) framework. Starting with a specifically designed efficient search space, AGD performs an end-to-end discovery for new efficient generators, given the target computational resource constraints. The search is guided by the original GAN model via knowledge distillation, therefore fulfilling the compression. AGD is fully automatic, standalone (i.e., needing no trained discriminators), and generically applicable to various GAN models. We evaluate AGD in two representative GAN tasks: image translation and super resolution. Without bells and whistles, AGD yields remarkably lightweight yet more competitive compressed models, that largely outperform existing alternatives. Our codes and pretrained models are available at https://github.com/TAMU-VITA/AGD.