 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMINDGAMES: A Live Arena for Evaluating Social and Strategic Reasoning in Multi-Agent LLMs
May 28, 2026Large language models (LLMs) are increasingly deployed as interactive agents, yet their capacity for social and strategic reasoning over extended interaction remains poorly understood. Existing evaluations rely on static vignettes or single-game benchmarks that cannot capture the sustained, multi-faceted reasoning that real-world multi-agent settings demand. We introduce Mindgames, a multi-game arena and evaluation platform for LLM agents that operationalizes complementary reasoning demands relevant to ``theory of mind'': belief attribution under hidden information, opponent modeling through repeated strategic interaction, cooperative inference under knowledge asymmetries, and sustained deception in social deduction. Built on TextArena, Mindgames provides a unified interaction interface, TrueSkill-based rating, and full trajectory logging across four game environments. We instantiate Mindgames through a 2025 competition cycle hosted at a major AI conference, which assessed 944 submitted agents from 76 teams across four games: Colonel Blotto, Iterated Prisoner's Dilemma, Codenames, and Secret Mafia. Our analysis surfaces both agent-level and evaluation-level limitations: brittle rule adherence remains a major bottleneck, top-performing systems repeatedly rely on explicit structural scaffolding, and leaderboard validity differs sharply across environments. In particular, failure-heavy environments can reward robustness to opponent errors as much as strategic ability, with Secret Mafia exhibiting a pronounced error-survival confound in this cycle. We release a dataset of 29,571 multi-agent games with turn-level observations, actions, and rewards, together with MG-Ref, a deterministic offline tournament protocol that scores new agents against a frozen reference pool of top-ranked, low-error Stage~II submissions under the same error-attribution lens used in this analysis.
SAS: Simulated Attention Score
Jul 10, 2025The attention mechanism is a core component of the Transformer architecture. Various methods have been developed to compute attention scores, including multi-head attention (MHA), multi-query attention, group-query attention and so on. We further analyze the MHA and observe that its performance improves as the number of attention heads increases, provided the hidden size per head remains sufficiently large. Therefore, increasing both the head count and hidden size per head with minimal parameter overhead can lead to significant performance gains at a low cost. Motivated by this insight, we introduce Simulated Attention Score (SAS), which maintains a compact model size while simulating a larger number of attention heads and hidden feature dimension per head. This is achieved by projecting a low-dimensional head representation into a higher-dimensional space, effectively increasing attention capacity without increasing parameter count. Beyond the head representations, we further extend the simulation approach to feature dimension of the key and query embeddings, enhancing expressiveness by mimicking the behavior of a larger model while preserving the original model size. To control the parameter cost, we also propose Parameter-Efficient Attention Aggregation (PEAA). Comprehensive experiments on a variety of datasets and tasks demonstrate the effectiveness of the proposed SAS method, achieving significant improvements over different attention variants.
AdaDeep: A Usage-Driven, Automated Deep Model Compression Framework for Enabling Ubiquitous Intelligent Mobiles
Jun 08, 2020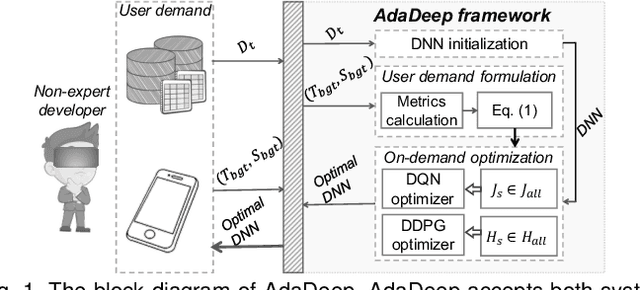
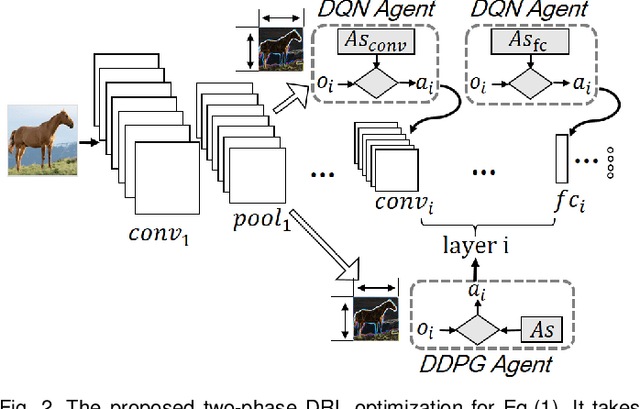

Recent breakthroughs in Deep Neural Networks (DNNs) have fueled a tremendously growing demand for bringing DNN-powered intelligence into mobile platforms. While the potential of deploying DNNs on resource-constrained platforms has been demonstrated by DNN compression techniques, the current practice suffers from two limitations: 1) merely stand-alone compression schemes are investigated even though each compression technique only suit for certain types of DNN layers; and 2) mostly compression techniques are optimized for DNNs' inference accuracy, without explicitly considering other application-driven system performance (e.g., latency and energy cost) and the varying resource availability across platforms (e.g., storage and processing capability). To this end, we propose AdaDeep, a usage-driven, automated DNN compression framework for systematically exploring the desired trade-off between performance and resource constraints, from a holistic system level. Specifically, in a layer-wise manner, AdaDeep automatically selects the most suitable combination of compression techniques and the corresponding compression hyperparameters for a given DNN. Thorough evaluations on six datasets and across twelve devices demonstrate that AdaDeep can achieve up to $18.6\times$ latency reduction, $9.8\times$ energy-efficiency improvement, and $37.3\times$ storage reduction in DNNs while incurring negligible accuracy loss. Furthermore, AdaDeep also uncovers multiple novel combinations of compression techniques.