 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanning on a Budget: Safe Non-Conservative Planning in Probabilistic Dynamic Environments
Jun 16, 2021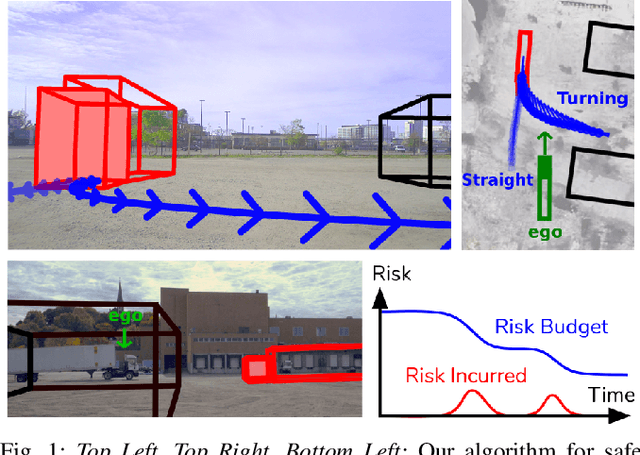
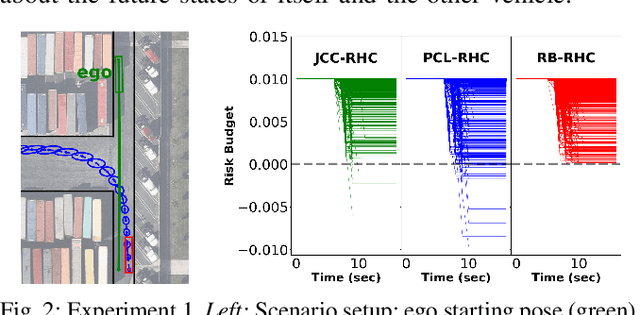
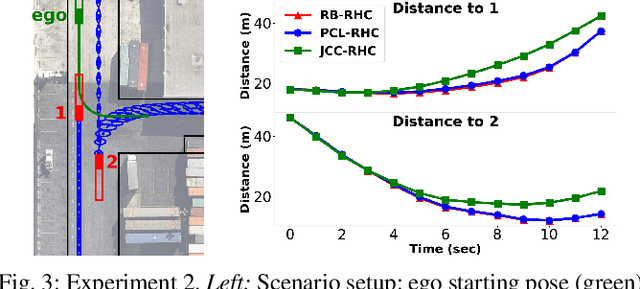
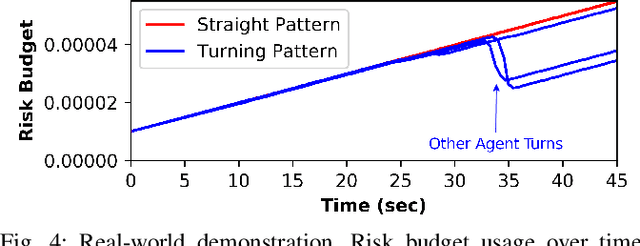
Planning in environments with other agents whose future actions are uncertain often requires compromise between safety and performance. Here our goal is to design efficient planning algorithms with guaranteed bounds on the probability of safety violation, which nonetheless achieve non-conservative performance. To quantify a system's risk, we define a natural criterion called interval risk bounds (IRBs), which provide a parametric upper bound on the probability of safety violation over a given time interval or task. We present a novel receding horizon algorithm, and prove that it can satisfy a desired IRB. Our algorithm maintains a dynamic risk budget which constrains the allowable risk at each iteration, and guarantees recursive feasibility by requiring a safe set to be reachable by a contingency plan within the budget. We empirically demonstrate that our algorithm is both safer and less conservative than strong baselines in two simulated autonomous driving experiments in scenarios involving collision avoidance with other vehicles, and additionally demonstrate our algorithm running on an autonomous class 8 truck.
SAS: Self-Augmented Strategy for Language Model Pre-training
Jun 14, 2021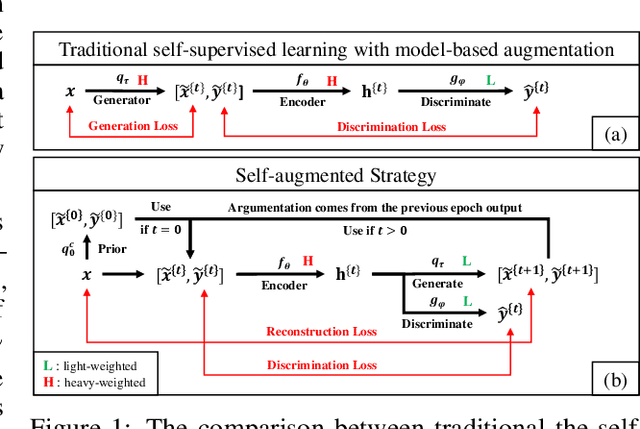
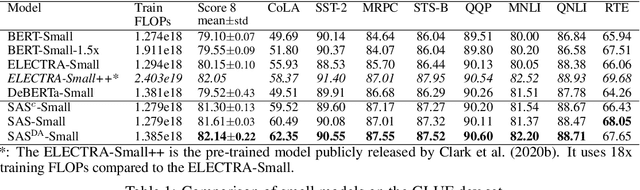
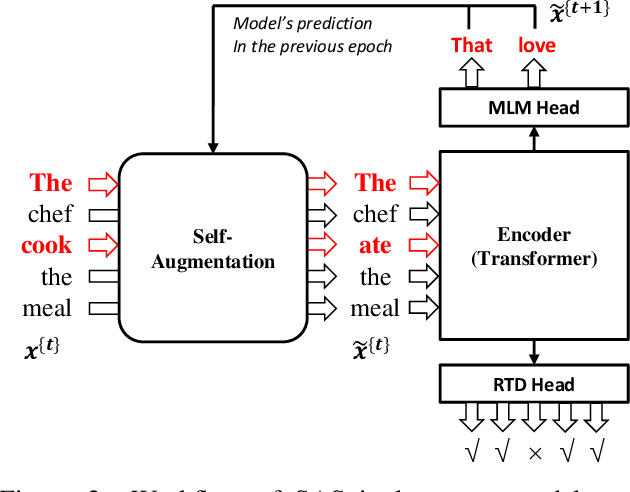

The core of a self-supervised learning method for pre-training language models includes the design of appropriate data augmentation and corresponding pre-training task(s). Most data augmentations in language model pre-training are context-independent. The seminal contextualized augmentation recently proposed by the ELECTRA requires a separate generator, which leads to extra computation cost as well as the challenge in adjusting the capability of its generator relative to that of the other model component(s). We propose a self-augmented strategy (SAS) that uses a single forward pass through the model to augment the input data for model training in the next epoch. Essentially our strategy eliminates a separate generator network and uses only one network to generate the data augmentation and undertake two pre-training tasks (the MLM task and the RTD task) jointly, which naturally avoids the challenge in adjusting the generator's capability as well as reduces the computation cost. Additionally, our SAS is a general strategy such that it can seamlessly incorporate many new techniques emerging recently or in the future, such as the disentangled attention mechanism recently proposed by the DeBERTa model. Our experiments show that our SAS is able to outperform the ELECTRA and other state-of-the-art models in the GLUE tasks with the same or less computation cost.
Generative Text Modeling through Short Run Inference
Jun 08, 2021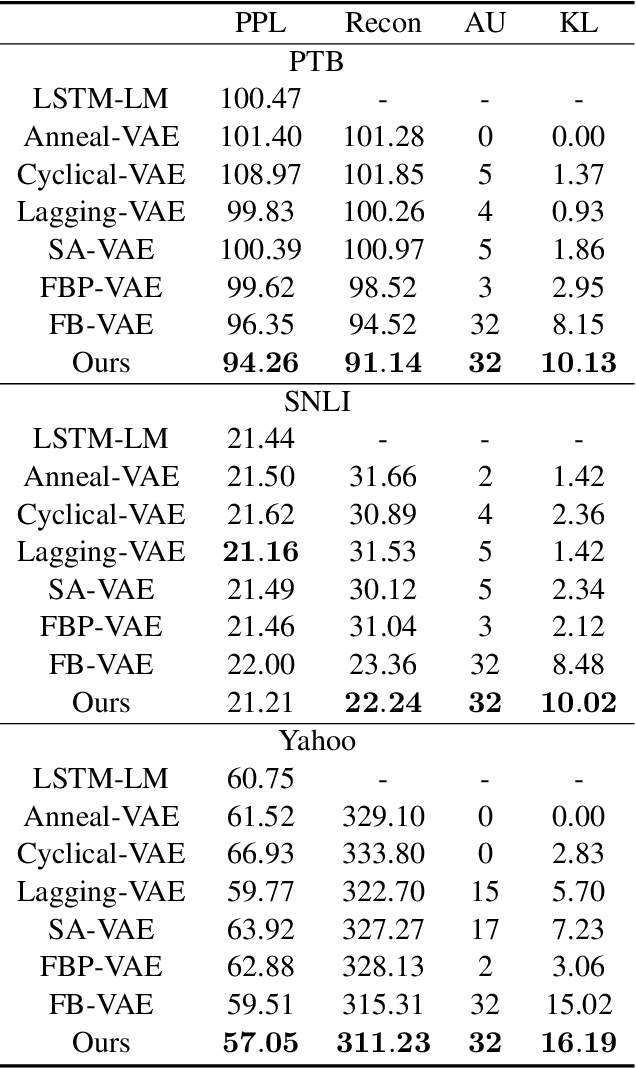
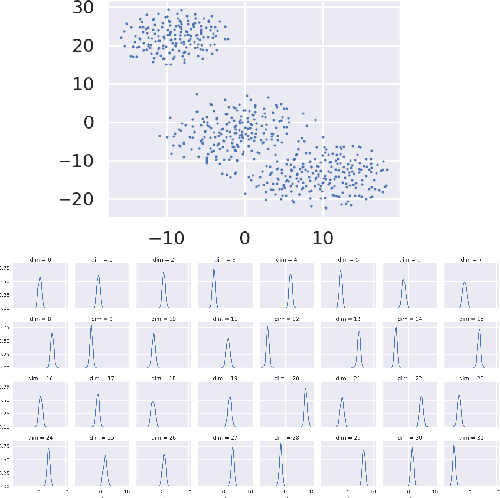


Latent variable models for text, when trained successfully, accurately model the data distribution and capture global semantic and syntactic features of sentences. The prominent approach to train such models is variational autoencoders (VAE). It is nevertheless challenging to train and often results in a trivial local optimum where the latent variable is ignored and its posterior collapses into the prior, an issue known as posterior collapse. Various techniques have been proposed to mitigate this issue. Most of them focus on improving the inference model to yield latent codes of higher quality. The present work proposes a short run dynamics for inference. It is initialized from the prior distribution of the latent variable and then runs a small number (e.g., 20) of Langevin dynamics steps guided by its posterior distribution. The major advantage of our method is that it does not require a separate inference model or assume simple geometry of the posterior distribution, thus rendering an automatic, natural and flexible inference engine. We show that the models trained with short run dynamics more accurately model the data, compared to strong language model and VAE baselines, and exhibit no sign of posterior collapse. Analyses of the latent space show that interpolation in the latent space is able to generate coherent sentences with smooth transition and demonstrate improved classification over strong baselines with latent features from unsupervised pretraining. These results together expose a well-structured latent space of our generative model.
Trajectory Prediction with Latent Belief Energy-Based Model
Apr 07, 2021
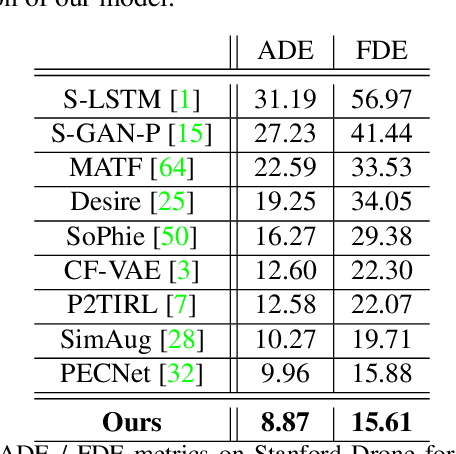

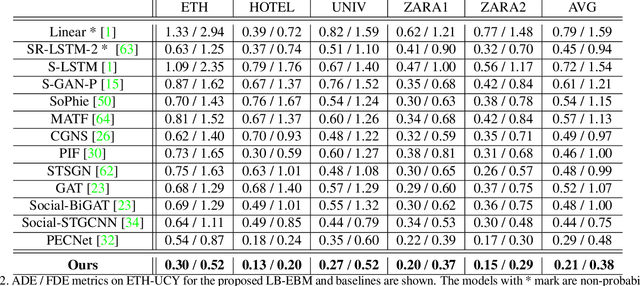
Human trajectory prediction is critical for autonomous platforms like self-driving cars or social robots. We present a latent belief energy-based model (LB-EBM) for diverse human trajectory forecast. LB-EBM is a probabilistic model with cost function defined in the latent space to account for the movement history and social context. The low-dimensionality of the latent space and the high expressivity of the EBM make it easy for the model to capture the multimodality of pedestrian trajectory distributions. LB-EBM is learned from expert demonstrations (i.e., human trajectories) projected into the latent space. Sampling from or optimizing the learned LB-EBM yields a belief vector which is used to make a path plan, which then in turn helps to predict a long-range trajectory. The effectiveness of LB-EBM and the two-step approach are supported by strong empirical results. Our model is able to make accurate, multi-modal, and social compliant trajectory predictions and improves over prior state-of-the-arts performance on the Stanford Drone trajectory prediction benchmark by 10.9% and on the ETH-UCY benchmark by 27.6%.
Congestion-aware Multi-agent Trajectory Prediction for Collision Avoidance
Mar 26, 2021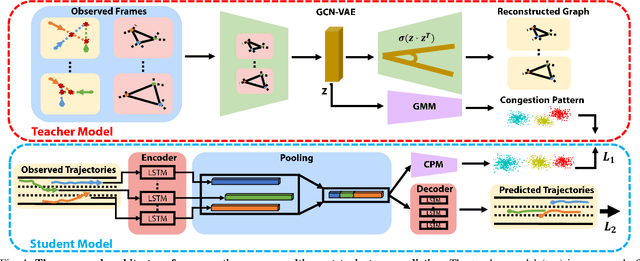
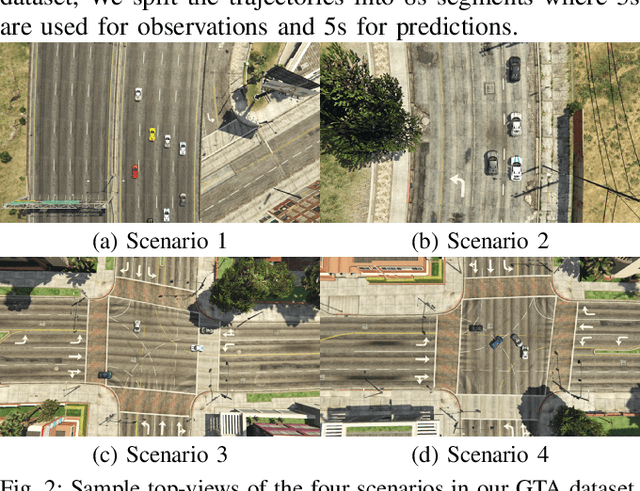
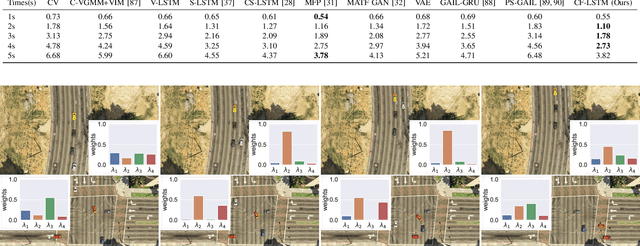
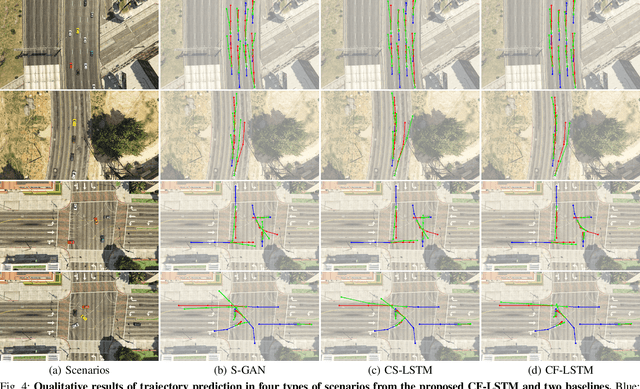
Predicting agents' future trajectories plays a crucial role in modern AI systems, yet it is challenging due to intricate interactions exhibited in multi-agent systems, especially when it comes to collision avoidance. To address this challenge, we propose to learn congestion patterns as contextual cues explicitly and devise a novel "Sense--Learn--Reason--Predict" framework by exploiting advantages of three different doctrines of thought, which yields the following desirable benefits: (i) Representing congestion as contextual cues via latent factors subsumes the concept of social force commonly used in physics-based approaches and implicitly encodes the distance as a cost, similar to the way a planning-based method models the environment. (ii) By decomposing the learning phases into two stages, a "student" can learn contextual cues from a "teacher" while generating collision-free trajectories. To make the framework computationally tractable, we formulate it as an optimization problem and derive an upper bound by leveraging the variational parametrization. In experiments, we demonstrate that the proposed model is able to generate collision-free trajectory predictions in a synthetic dataset designed for collision avoidance evaluation and remains competitive on the commonly used NGSIM US-101 highway dataset.
Learning Cycle-Consistent Cooperative Networks via Alternating MCMC Teaching for Unsupervised Cross-Domain Translation
Mar 07, 2021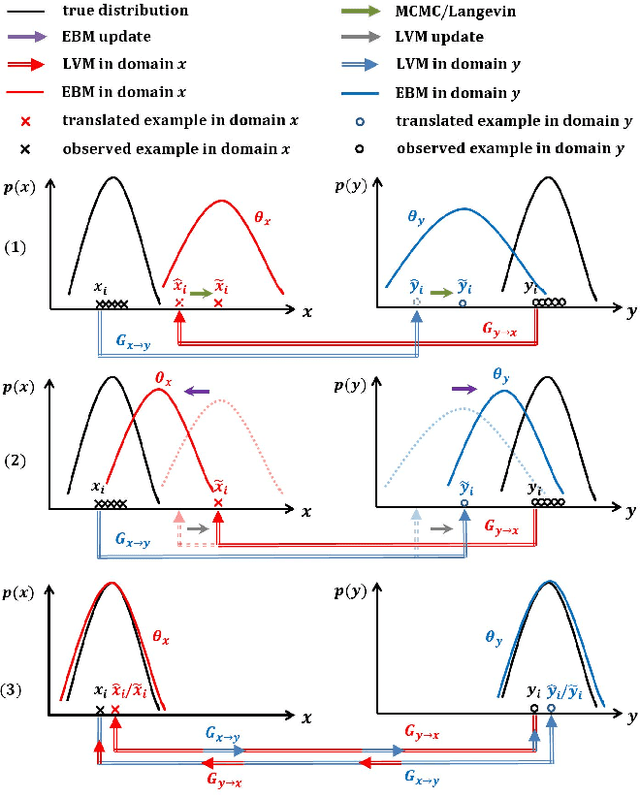
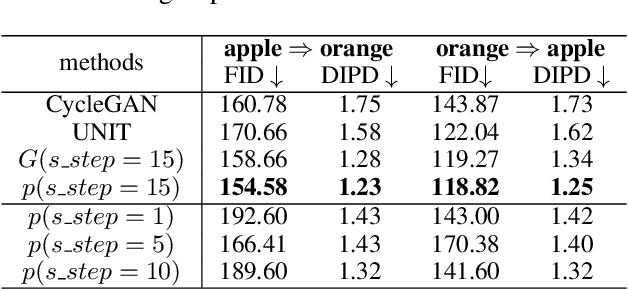

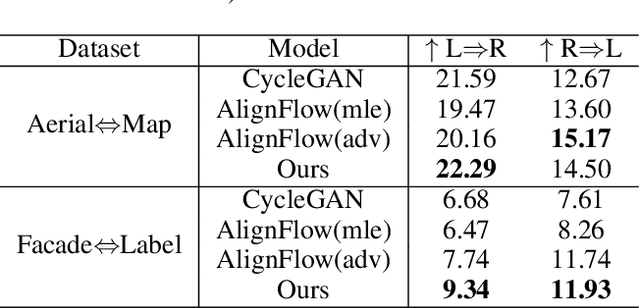
This paper studies the unsupervised cross-domain translation problem by proposing a generative framework, in which the probability distribution of each domain is represented by a generative cooperative network that consists of an energy-based model and a latent variable model. The use of generative cooperative network enables maximum likelihood learning of the domain model by MCMC teaching, where the energy-based model seeks to fit the data distribution of domain and distills its knowledge to the latent variable model via MCMC. Specifically, in the MCMC teaching process, the latent variable model parameterized by an encoder-decoder maps examples from the source domain to the target domain, while the energy-based model further refines the mapped results by Langevin revision such that the revised results match to the examples in the target domain in terms of the statistical properties, which are defined by the learned energy function. For the purpose of building up a correspondence between two unpaired domains, the proposed framework simultaneously learns a pair of cooperative networks with cycle consistency, accounting for a two-way translation between two domains, by alternating MCMC teaching. Experiments show that the proposed framework is useful for unsupervised image-to-image translation and unpaired image sequence translation.
A HINT from Arithmetic: On Systematic Generalization of Perception, Syntax, and Semantics
Mar 02, 2021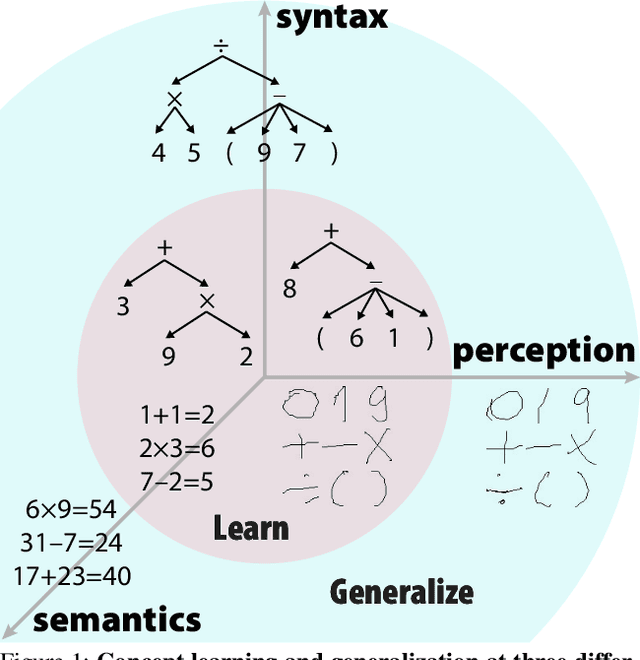
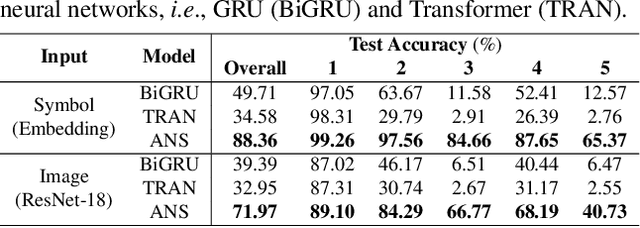
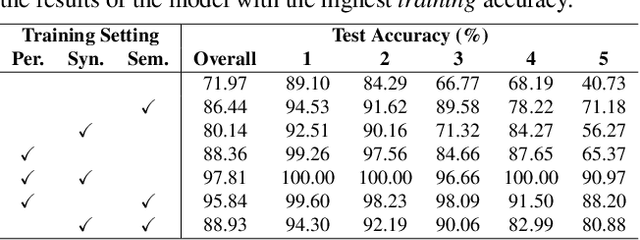
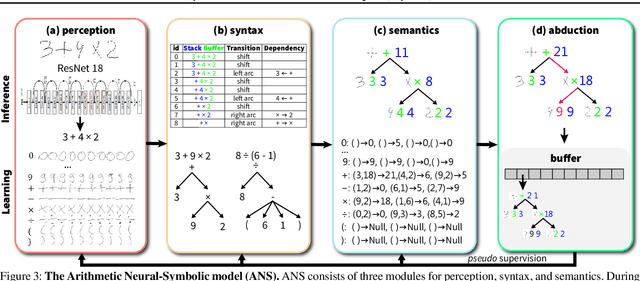
Inspired by humans' remarkable ability to master arithmetic and generalize to unseen problems, we present a new dataset, HINT, to study machines' capability of learning generalizable concepts at three different levels: perception, syntax, and semantics. In particular, concepts in HINT, including both digits and operators, are required to learn in a weakly-supervised fashion: Only the final results of handwriting expressions are provided as supervision. Learning agents need to reckon how concepts are perceived from raw signals such as images (i.e., perception), how multiple concepts are structurally combined to form a valid expression (i.e., syntax), and how concepts are realized to afford various reasoning tasks (i.e., semantics). With a focus on systematic generalization, we carefully design a five-fold test set to evaluate both the interpolation and the extrapolation of learned concepts. To tackle this challenging problem, we propose a neural-symbolic system by integrating neural networks with grammar parsing and program synthesis, learned by a novel deduction--abduction strategy. In experiments, the proposed neural-symbolic system demonstrates strong generalization capability and significantly outperforms end-to-end neural methods like RNN and Transformer. The results also indicate the significance of recursive priors for extrapolation on syntax and semantics.
HALMA: Humanlike Abstraction Learning Meets Affordance in Rapid Problem Solving
Feb 22, 2021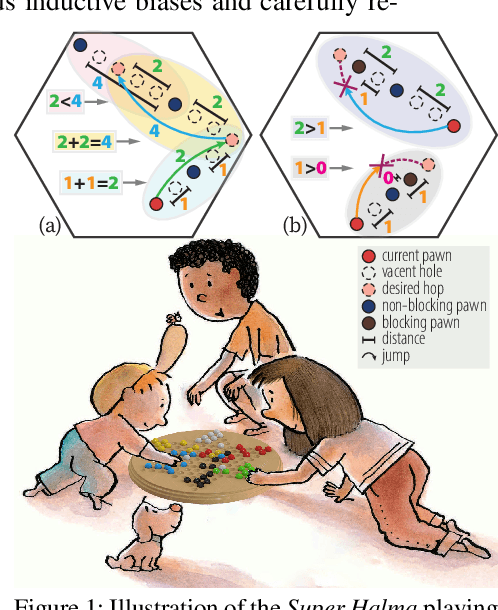
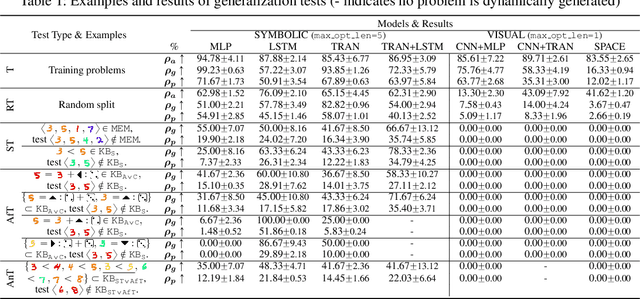
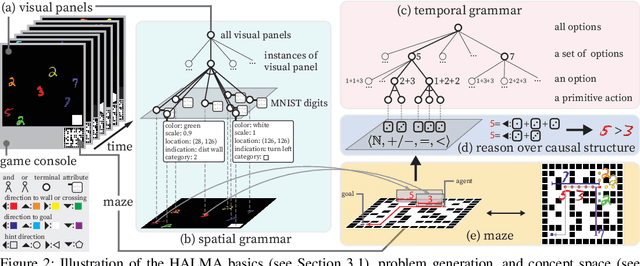
Humans learn compositional and causal abstraction, \ie, knowledge, in response to the structure of naturalistic tasks. When presented with a problem-solving task involving some objects, toddlers would first interact with these objects to reckon what they are and what can be done with them. Leveraging these concepts, they could understand the internal structure of this task, without seeing all of the problem instances. Remarkably, they further build cognitively executable strategies to \emph{rapidly} solve novel problems. To empower a learning agent with similar capability, we argue there shall be three levels of generalization in how an agent represents its knowledge: perceptual, conceptual, and algorithmic. In this paper, we devise the very first systematic benchmark that offers joint evaluation covering all three levels. This benchmark is centered around a novel task domain, HALMA, for visual concept development and rapid problem-solving. Uniquely, HALMA has a minimum yet complete concept space, upon which we introduce a novel paradigm to rigorously diagnose and dissect learning agents' capability in understanding and generalizing complex and structural concepts. We conduct extensive experiments on reinforcement learning agents with various inductive biases and carefully report their proficiency and weakness.
Generative VoxelNet: Learning Energy-Based Models for 3D Shape Synthesis and Analysis
Dec 25, 2020
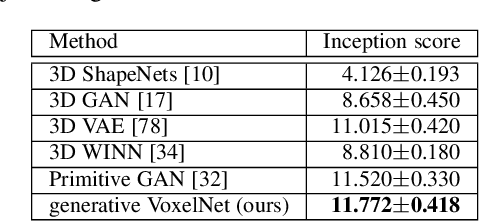

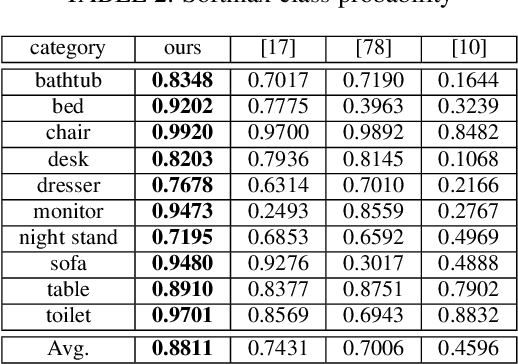
3D data that contains rich geometry information of objects and scenes is valuable for understanding 3D physical world. With the recent emergence of large-scale 3D datasets, it becomes increasingly crucial to have a powerful 3D generative model for 3D shape synthesis and analysis. This paper proposes a deep 3D energy-based model to represent volumetric shapes. The maximum likelihood training of the model follows an "analysis by synthesis" scheme. The benefits of the proposed model are six-fold: first, unlike GANs and VAEs, the model training does not rely on any auxiliary models; second, the model can synthesize realistic 3D shapes by Markov chain Monte Carlo (MCMC); third, the conditional model can be applied to 3D object recovery and super resolution; fourth, the model can serve as a building block in a multi-grid modeling and sampling framework for high resolution 3D shape synthesis; fifth, the model can be used to train a 3D generator via MCMC teaching; sixth, the unsupervisedly trained model provides a powerful feature extractor for 3D data, which is useful for 3D object classification. Experiments demonstrate that the proposed model can generate high-quality 3D shape patterns and can be useful for a wide variety of 3D shape analysis.
Learning Energy-Based Models by Diffusion Recovery Likelihood
Dec 15, 2020
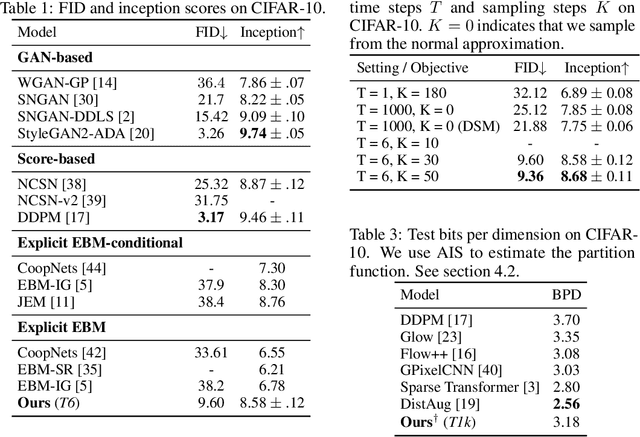
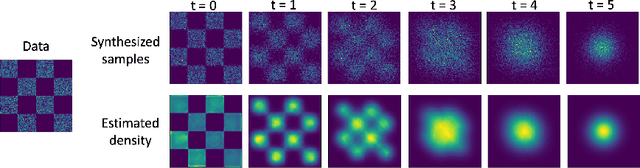

While energy-based models (EBMs) exhibit a number of desirable properties, training and sampling on high-dimensional datasets remains challenging. Inspired by recent progress on diffusion probabilistic models, we present a diffusion recovery likelihood method to tractably learn and sample from a sequence of EBMs trained on increasingly noisy versions of a dataset. Each EBM is trained by maximizing the recovery likelihood: the conditional probability of the data at a certain noise level given their noisy versions at a higher noise level. The recovery likelihood objective is more tractable than the marginal likelihood objective, since it only requires MCMC sampling from a relatively concentrated conditional distribution. Moreover, we show that this estimation method is theoretically consistent: it learns the correct conditional and marginal distributions at each noise level, given sufficient data. After training, synthesized images can be generated efficiently by a sampling process that initializes from a spherical Gaussian distribution and progressively samples the conditional distributions at decreasingly lower noise levels. Our method generates high fidelity samples on various image datasets. On unconditional CIFAR-10 our method achieves FID 9.60 and inception score 8.58, superior to the majority of GANs. Moreover, we demonstrate that unlike previous work on EBMs, our long-run MCMC samples from the conditional distributions do not diverge and still represent realistic images, allowing us to accurately estimate the normalized density of data even for high-dimensional datasets.