 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Contrastive Learning of Sentence Embeddings with Case-Augmented Positives and Retrieved Negatives
Jun 06, 2022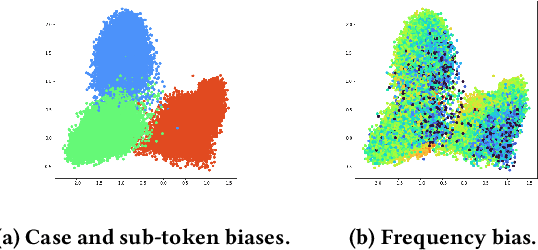

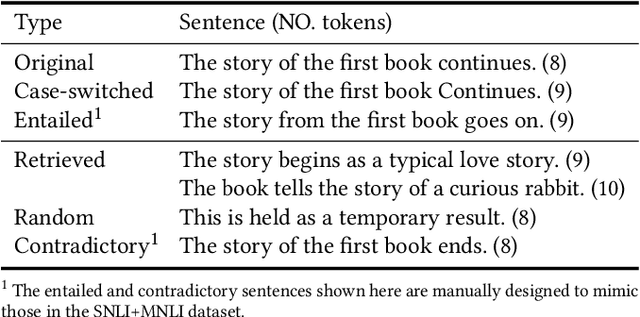
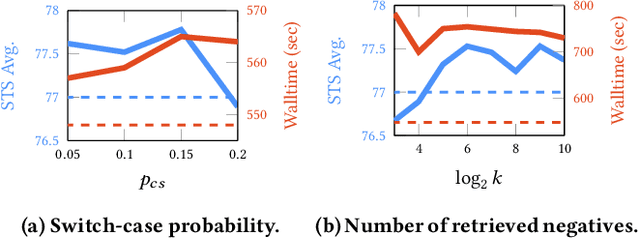
Following SimCSE, contrastive learning based methods have achieved the state-of-the-art (SOTA) performance in learning sentence embeddings. However, the unsupervised contrastive learning methods still lag far behind the supervised counterparts. We attribute this to the quality of positive and negative samples, and aim to improve both. Specifically, for positive samples, we propose switch-case augmentation to flip the case of the first letter of randomly selected words in a sentence. This is to counteract the intrinsic bias of pre-trained token embeddings to frequency, word cases and subwords. For negative samples, we sample hard negatives from the whole dataset based on a pre-trained language model. Combining the above two methods with SimCSE, our proposed Contrastive learning with Augmented and Retrieved Data for Sentence embedding (CARDS) method significantly surpasses the current SOTA on STS benchmarks in the unsupervised setting.
SAS: Self-Augmented Strategy for Language Model Pre-training
Jun 14, 2021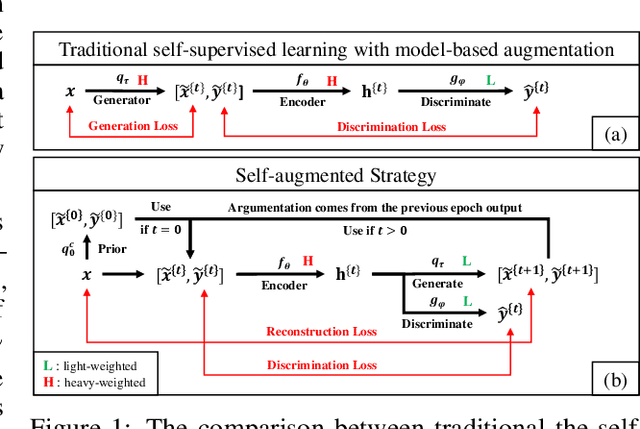
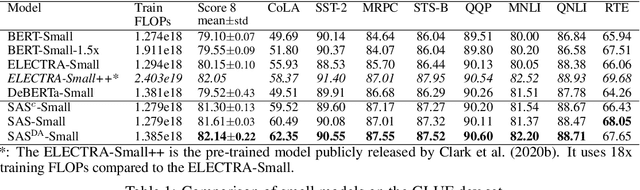
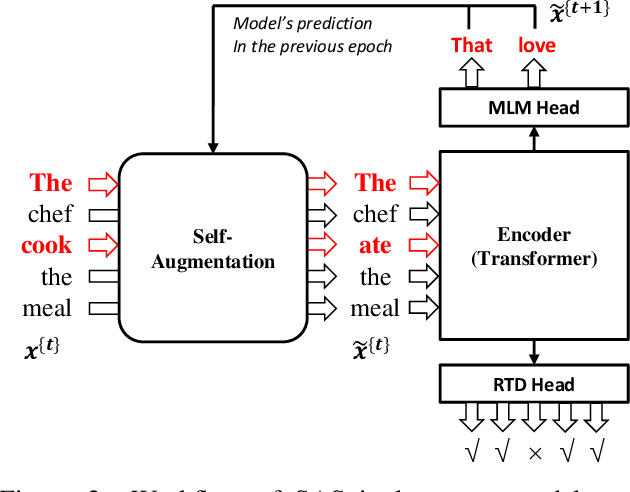

The core of a self-supervised learning method for pre-training language models includes the design of appropriate data augmentation and corresponding pre-training task(s). Most data augmentations in language model pre-training are context-independent. The seminal contextualized augmentation recently proposed by the ELECTRA requires a separate generator, which leads to extra computation cost as well as the challenge in adjusting the capability of its generator relative to that of the other model component(s). We propose a self-augmented strategy (SAS) that uses a single forward pass through the model to augment the input data for model training in the next epoch. Essentially our strategy eliminates a separate generator network and uses only one network to generate the data augmentation and undertake two pre-training tasks (the MLM task and the RTD task) jointly, which naturally avoids the challenge in adjusting the generator's capability as well as reduces the computation cost. Additionally, our SAS is a general strategy such that it can seamlessly incorporate many new techniques emerging recently or in the future, such as the disentangled attention mechanism recently proposed by the DeBERTa model. Our experiments show that our SAS is able to outperform the ELECTRA and other state-of-the-art models in the GLUE tasks with the same or less computation cost.
Redundancy of Hidden Layers in Deep Learning: An Information Perspective
Sep 19, 2020
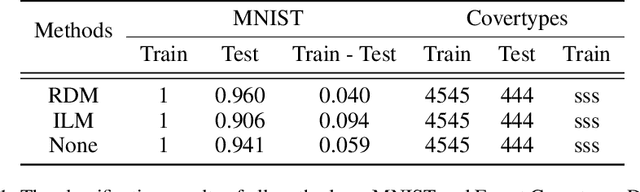
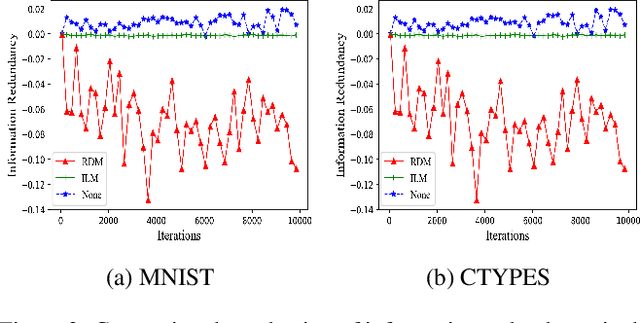
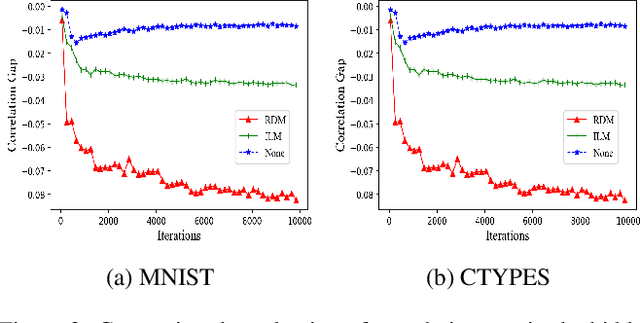
Although the deep structure guarantees the powerful expressivity of deep networks (DNNs), it also triggers serious overfitting problem. To improve the generalization capacity of DNNs, many strategies were developed to improve the diversity among hidden units. However, most of these strategies are empirical and heuristic in absence of either a theoretical derivation of the diversity measure or a clear connection from the diversity to the generalization capacity. In this paper, from an information theoretic perspective, we introduce a new definition of redundancy to describe the diversity of hidden units under supervised learning settings by formalizing the effect of hidden layers on the generalization capacity as the mutual information. We prove an opposite relationship existing between the defined redundancy and the generalization capacity, i.e., the decrease of redundancy generally improving the generalization capacity. The experiments show that the DNNs using the redundancy as the regularizer can effectively reduce the overfitting and decrease the generalization error, which well supports above points.