 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Glottis Detection Framework via Spatial-decoupled Feature Learning for Nasal Transnasal Intubation
Mar 08, 2026Nasotracheal intubation (NTI) is a vital procedure in emergency airway management, where rapid and accurate glottis detection is essential to ensure patient safety. However, existing machine assisted visual detection systems often rely on high performance computational resources and suffer from significant inference delays, which limits their applicability in time critical and resource constrained scenarios. To overcome these limitations, we propose Mobile GlottisNet, a lightweight and efficient glottis detection framework designed for real time inference on embedded and edge devices. The model incorporates structural awareness and spatial alignment mechanisms, enabling robust glottis localization under complex anatomical and visual conditions. We implement a hierarchical dynamic thresholding strategy to enhance sample assignment, and introduce an adaptive feature decoupling module based on deformable convolution to support dynamic spatial reconstruction. A cross layer dynamic weighting scheme further facilitates the fusion of semantic and detail features across multiple scales. Experimental results demonstrate that the model, with a size of only 5MB on both our PID dataset and Clinical datasets, achieves inference speeds of over 62 FPS on devices and 33 FPS on edge platforms, showing great potential in the application of emergency NTI.
Temporal Data and Short-Time Averages Improve Multiphase Mass Flow Metering
Jan 18, 2026Reliable flow measurements are essential in many industries, but current instruments often fail to accurately estimate multiphase flows, which are frequently encountered in real-world operations. Combining machine learning (ML) algorithms with accurate single-phase flowmeters has therefore received extensive research attention in recent years. The Coriolis mass flowmeter is a widely used single-phase meter that provides direct mass flow measurements, which ML models can be trained to correct, thereby reducing measurement errors in multiphase conditions. This paper demonstrates that preserving temporal information significantly improves model performance in such scenarios. We compare a multilayer perceptron, a windowed multilayer perceptron, and a convolutional neural network (CNN) on three-phase air-water-oil flow data from 342 experiments. Whereas prior work typically compresses each experiment into a single averaged sample, we instead compute short-time averages from within each experiment and train models that preserve temporal information at several downsampling intervals. The CNN performed best at 0.25 Hz with approximately 95 % of relative errors below 13 %, a normalized root mean squared error of 0.03, and a mean absolute percentage error of approximately 4.3 %, clearly outperforming the best single-averaged model and demonstrating that short-time averaging within individual experiments is preferable. Results are consistent across multiple data splits and random seeds, demonstrating robustness.
Reinforcement Learning Based Bidding Framework with High-dimensional Bids in Power Markets
Oct 15, 2024



Over the past decade, bidding in power markets has attracted widespread attention. Reinforcement Learning (RL) has been widely used for power market bidding as a powerful AI tool to make decisions under real-world uncertainties. However, current RL methods mostly employ low dimensional bids, which significantly diverge from the N price-power pairs commonly used in the current power markets. The N-pair bidding format is denoted as High Dimensional Bids (HDBs), which has not been fully integrated into the existing RL-based bidding methods. The loss of flexibility in current RL bidding methods could greatly limit the bidding profits and make it difficult to tackle the rising uncertainties brought by renewable energy generations. In this paper, we intend to propose a framework to fully utilize HDBs for RL-based bidding methods. First, we employ a special type of neural network called Neural Network Supply Functions (NNSFs) to generate HDBs in the form of N price-power pairs. Second, we embed the NNSF into a Markov Decision Process (MDP) to make it compatible with most existing RL methods. Finally, experiments on Energy Storage Systems (ESSs) in the PJM Real-Time (RT) power market show that the proposed bidding method with HDBs can significantly improve bidding flexibility, thereby improving the profit of the state-of-the-art RL bidding methods.
A Reproducibility Study on Quantifying Language Similarity: The Impact of Missing Values in the URIEL Knowledge Base
May 17, 2024



In the pursuit of supporting more languages around the world, tools that characterize properties of languages play a key role in expanding the existing multilingual NLP research. In this study, we focus on a widely used typological knowledge base, URIEL, which aggregates linguistic information into numeric vectors. Specifically, we delve into the soundness and reproducibility of the approach taken by URIEL in quantifying language similarity. Our analysis reveals URIEL's ambiguity in calculating language distances and in handling missing values. Moreover, we find that URIEL does not provide any information about typological features for 31\% of the languages it represents, undermining the reliabilility of the database, particularly on low-resource languages. Our literature review suggests URIEL and lang2vec are used in papers on diverse NLP tasks, which motivates us to rigorously verify the database as the effectiveness of these works depends on the reliability of the information the tool provides.
Predicting Machine Translation Performance on Low-Resource Languages: The Role of Domain Similarity
Feb 04, 2024Fine-tuning and testing a multilingual large language model is expensive and challenging for low-resource languages (LRLs). While previous studies have predicted the performance of natural language processing (NLP) tasks using machine learning methods, they primarily focus on high-resource languages, overlooking LRLs and shifts across domains. Focusing on LRLs, we investigate three factors: the size of the fine-tuning corpus, the domain similarity between fine-tuning and testing corpora, and the language similarity between source and target languages. We employ classical regression models to assess how these factors impact the model's performance. Our results indicate that domain similarity has the most critical impact on predicting the performance of Machine Translation models.
High-dimensional Bid Learning for Energy Storage Bidding in Energy Markets
Nov 05, 2023


With the growing penetration of renewable energy resource, electricity market prices have exhibited greater volatility. Therefore, it is important for Energy Storage Systems(ESSs) to leverage the multidimensional nature of energy market bids to maximize profitability. However, current learning methods cannot fully utilize the high-dimensional price-quantity bids in the energy markets. To address this challenge, we modify the common reinforcement learning(RL) process by proposing a new bid representation method called Neural Network Embedded Bids (NNEBs). NNEBs refer to market bids that are represented by monotonic neural networks with discrete outputs. To achieve effective learning of NNEBs, we first learn a neural network as a strategic mapping from the market price to ESS power output with RL. Then, we re-train the network with two training modifications to make the network output monotonic and discrete. Finally, the neural network is equivalently converted into a high-dimensional bid for bidding. We conducted experiments over real-world market datasets. Our studies show that the proposed method achieves 18% higher profit than the baseline and up to 78% profit of the optimal market bidder.
Two-Stream Joint-Training for Speaker Independent Acoustic-to-Articulatory Inversion
Feb 26, 2023Acoustic-to-articulatory inversion (AAI) aims to estimate the parameters of articulators from speech audio. There are two common challenges in AAI, which are the limited data and the unsatisfactory performance in speaker independent scenario. Most current works focus on extracting features directly from speech and ignoring the importance of phoneme information which may limit the performance of AAI. To this end, we propose a novel network called SPN that uses two different streams to carry out the AAI task. Firstly, to improve the performance of speaker-independent experiment, we propose a new phoneme stream network to estimate the articulatory parameters as the phoneme features. To the best of our knowledge, this is the first work that extracts the speaker-independent features from phonemes to improve the performance of AAI. Secondly, in order to better represent the speech information, we train a speech stream network to combine the local features and the global features. Compared with state-of-the-art (SOTA), the proposed method reduces 0.18mm on RMSE and increases 6.0% on Pearson correlation coefficient in the speaker-independent experiment. The code has been released at https://github.com/liujinyu123/AAINetwork-SPN.
Modality-Aware Contrastive Instance Learning with Self-Distillation for Weakly-Supervised Audio-Visual Violence Detection
Jul 12, 2022



Weakly-supervised audio-visual violence detection aims to distinguish snippets containing multimodal violence events with video-level labels. Many prior works perform audio-visual integration and interaction in an early or intermediate manner, yet overlooking the modality heterogeneousness over the weakly-supervised setting. In this paper, we analyze the modality asynchrony and undifferentiated instances phenomena of the multiple instance learning (MIL) procedure, and further investigate its negative impact on weakly-supervised audio-visual learning. To address these issues, we propose a modality-aware contrastive instance learning with self-distillation (MACIL-SD) strategy. Specifically, we leverage a lightweight two-stream network to generate audio and visual bags, in which unimodal background, violent, and normal instances are clustered into semi-bags in an unsupervised way. Then audio and visual violent semi-bag representations are assembled as positive pairs, and violent semi-bags are combined with background and normal instances in the opposite modality as contrastive negative pairs. Furthermore, a self-distillation module is applied to transfer unimodal visual knowledge to the audio-visual model, which alleviates noises and closes the semantic gap between unimodal and multimodal features. Experiments show that our framework outperforms previous methods with lower complexity on the large-scale XD-Violence dataset. Results also demonstrate that our proposed approach can be used as plug-in modules to enhance other networks. Codes are available at https://github.com/JustinYuu/MACIL_SD.
Self-Supervised Video Representation Learning with Motion-Contrastive Perception
Apr 10, 2022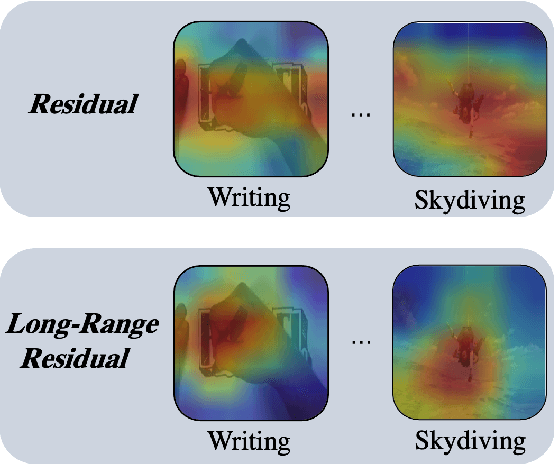
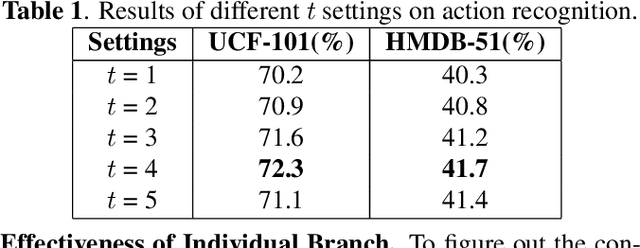
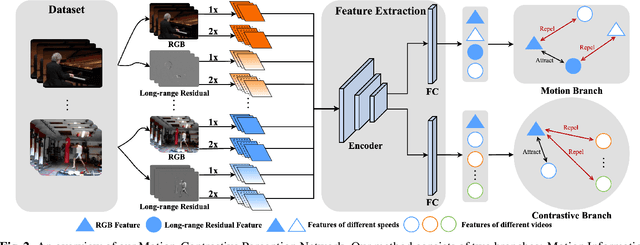

Visual-only self-supervised learning has achieved significant improvement in video representation learning. Existing related methods encourage models to learn video representations by utilizing contrastive learning or designing specific pretext tasks. However, some models are likely to focus on the background, which is unimportant for learning video representations. To alleviate this problem, we propose a new view called long-range residual frame to obtain more motion-specific information. Based on this, we propose the Motion-Contrastive Perception Network (MCPNet), which consists of two branches, namely, Motion Information Perception (MIP) and Contrastive Instance Perception (CIP), to learn generic video representations by focusing on the changing areas in videos. Specifically, the MIP branch aims to learn fine-grained motion features, and the CIP branch performs contrastive learning to learn overall semantics information for each instance. Experiments on two benchmark datasets UCF-101 and HMDB-51 show that our method outperforms current state-of-the-art visual-only self-supervised approaches.
Acoustic-to-articulatory Inversion based on Speech Decomposition and Auxiliary Feature
Apr 02, 2022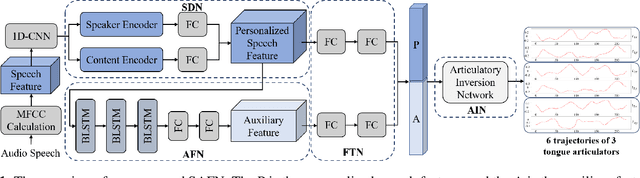
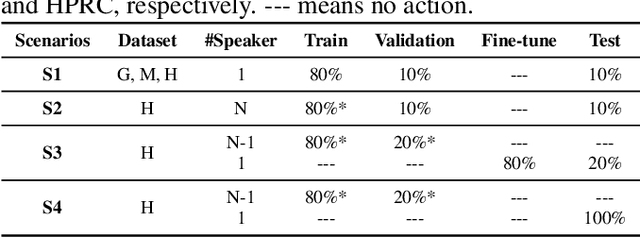
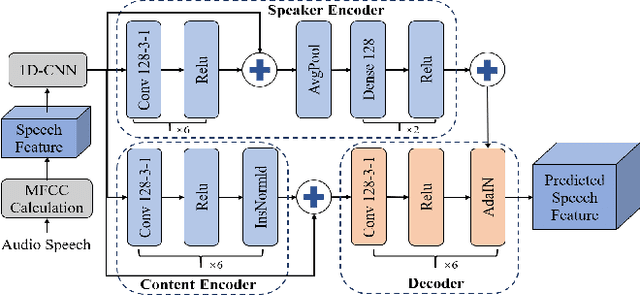
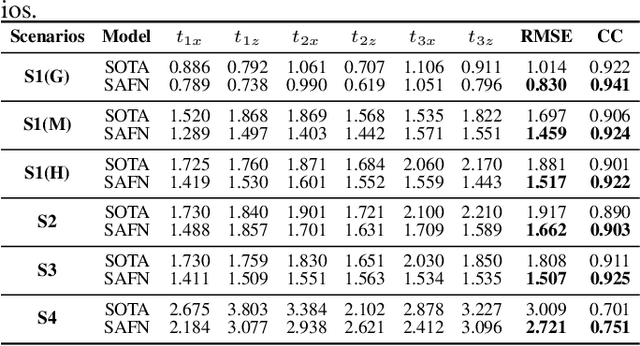
Acoustic-to-articulatory inversion (AAI) is to obtain the movement of articulators from speech signals. Until now, achieving a speaker-independent AAI remains a challenge given the limited data. Besides, most current works only use audio speech as input, causing an inevitable performance bottleneck. To solve these problems, firstly, we pre-train a speech decomposition network to decompose audio speech into speaker embedding and content embedding as the new personalized speech features to adapt to the speaker-independent case. Secondly, to further improve the AAI, we propose a novel auxiliary feature network to estimate the lip auxiliary features from the above personalized speech features. Experimental results on three public datasets show that, compared with the state-of-the-art only using the audio speech feature, the proposed method reduces the average RMSE by 0.25 and increases the average correlation coefficient by 2.0% in the speaker-dependent case. More importantly, the average RMSE decreases by 0.29 and the average correlation coefficient increases by 5.0% in the speaker-independent case.