 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Scene Inference under Noise-Blur Dual Corruptions
Jul 24, 2022
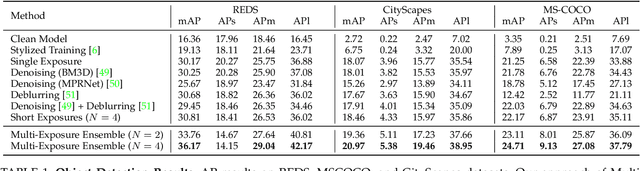
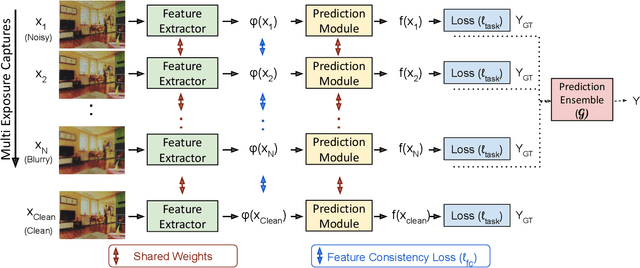
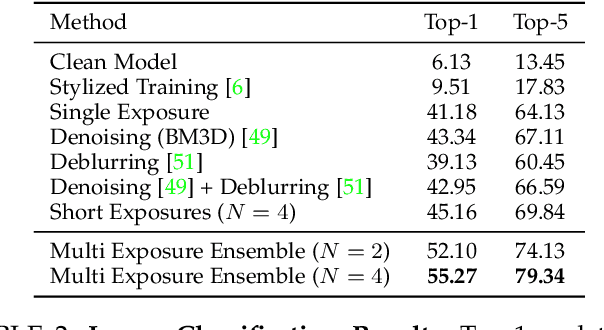
Scene inference under low-light is a challenging problem due to severe noise in the captured images. One way to reduce noise is to use longer exposure during the capture. However, in the presence of motion (scene or camera motion), longer exposures lead to motion blur, resulting in loss of image information. This creates a trade-off between these two kinds of image degradations: motion blur (due to long exposure) vs. noise (due to short exposure), also referred as a dual image corruption pair in this paper. With the rise of cameras capable of capturing multiple exposures of the same scene simultaneously, it is possible to overcome this trade-off. Our key observation is that although the amount and nature of degradation varies for these different image captures, the semantic content remains the same across all images. To this end, we propose a method to leverage these multi exposure captures for robust inference under low-light and motion. Our method builds on a feature consistency loss to encourage similar results from these individual captures, and uses the ensemble of their final predictions for robust visual recognition. We demonstrate the effectiveness of our approach on simulated images as well as real captures with multiple exposures, and across the tasks of object detection and image classification.
Reconstructing the Universe with Variational self-Boosted Sampling
Jun 28, 2022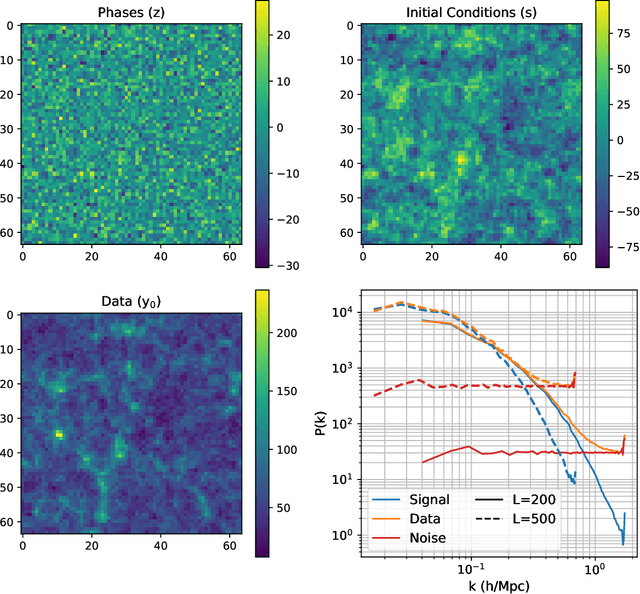
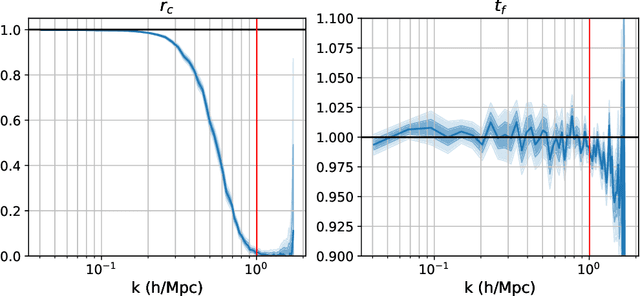
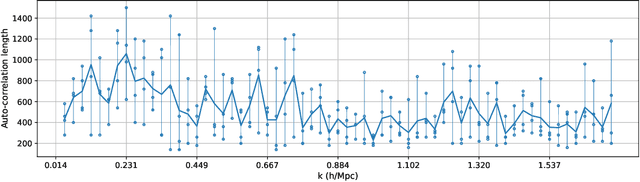
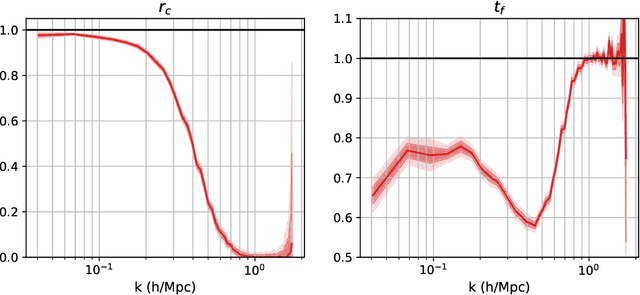
Forward modeling approaches in cosmology have made it possible to reconstruct the initial conditions at the beginning of the Universe from the observed survey data. However the high dimensionality of the parameter space still poses a challenge to explore the full posterior, with traditional algorithms such as Hamiltonian Monte Carlo (HMC) being computationally inefficient due to generating correlated samples and the performance of variational inference being highly dependent on the choice of divergence (loss) function. Here we develop a hybrid scheme, called variational self-boosted sampling (VBS) to mitigate the drawbacks of both these algorithms by learning a variational approximation for the proposal distribution of Monte Carlo sampling and combine it with HMC. The variational distribution is parameterized as a normalizing flow and learnt with samples generated on the fly, while proposals drawn from it reduce auto-correlation length in MCMC chains. Our normalizing flow uses Fourier space convolutions and element-wise operations to scale to high dimensions. We show that after a short initial warm-up and training phase, VBS generates better quality of samples than simple VI approaches and reduces the correlation length in the sampling phase by a factor of 10-50 over using only HMC to explore the posterior of initial conditions in 64$^3$ and 128$^3$ dimensional problems, with larger gains for high signal-to-noise data observations.
Simple lessons from complex learning: what a neural network model learns about cosmic structure formation
Jun 14, 2022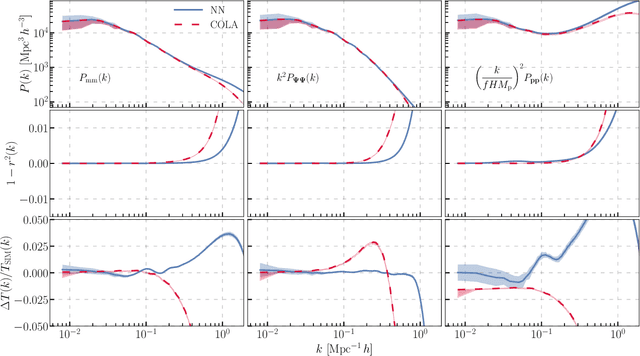
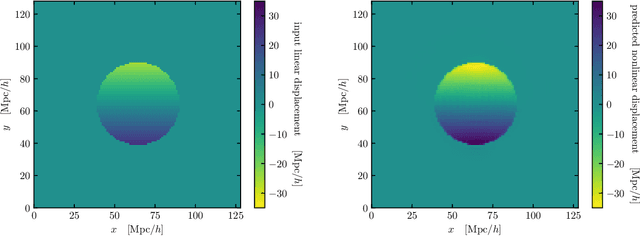
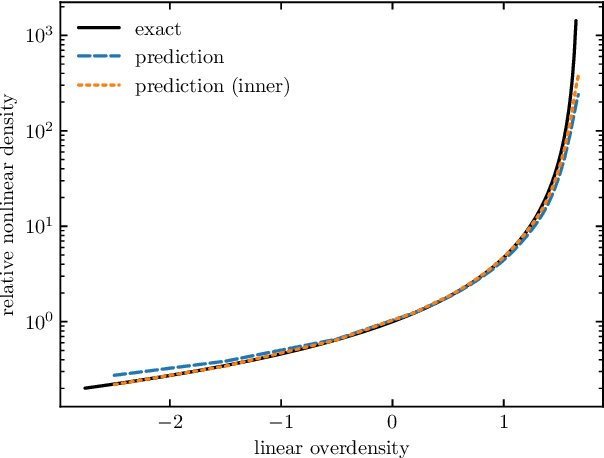
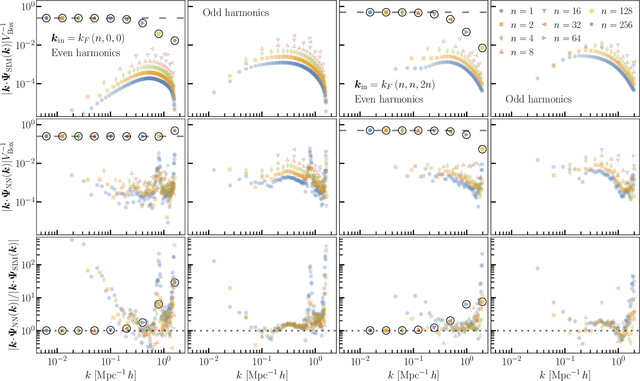
We train a neural network model to predict the full phase space evolution of cosmological N-body simulations. Its success implies that the neural network model is accurately approximating the Green's function expansion that relates the initial conditions of the simulations to its outcome at later times in the deeply nonlinear regime. We test the accuracy of this approximation by assessing its performance on well understood simple cases that have either known exact solutions or well understood expansions. These scenarios include spherical configurations, isolated plane waves, and two interacting plane waves: initial conditions that are very different from the Gaussian random fields used for training. We find our model generalizes well to these well understood scenarios, demonstrating that the networks have inferred general physical principles and learned the nonlinear mode couplings from the complex, random Gaussian training data. These tests also provide a useful diagnostic for finding the model's strengths and weaknesses, and identifying strategies for model improvement. We also test the model on initial conditions that contain only transverse modes, a family of modes that differ not only in their phases but also in their evolution from the longitudinal growing modes used in the training set. When the network encounters these initial conditions that are orthogonal to the training set, the model fails completely. In addition to these simple configurations, we evaluate the model's predictions for the density, displacement, and momentum power spectra with standard initial conditions for N-body simulations. We compare these summary statistics against N-body results and an approximate, fast simulation method called COLA. Our model achieves percent level accuracy at nonlinear scales of $k\sim 1\ \mathrm{Mpc}^{-1}\, h$, representing a significant improvement over COLA.
Field Level Neural Network Emulator for Cosmological N-body Simulations
Jun 14, 2022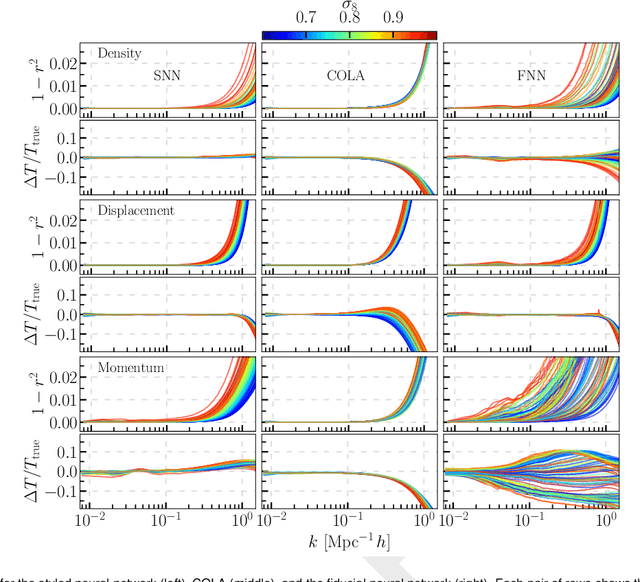
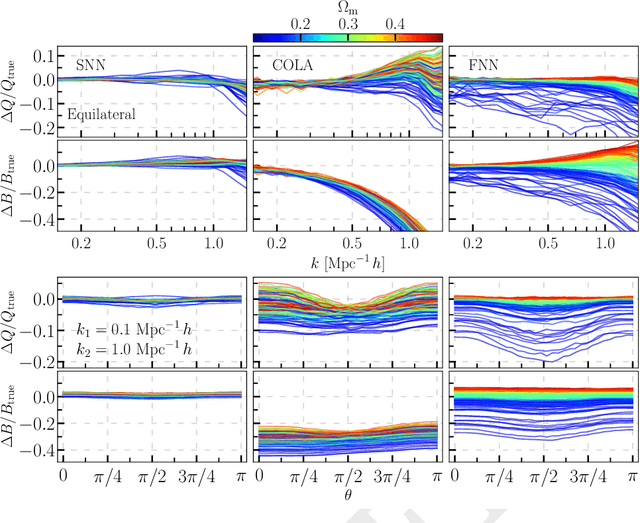
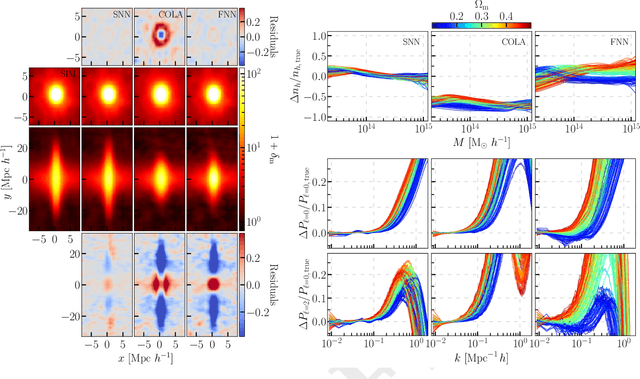
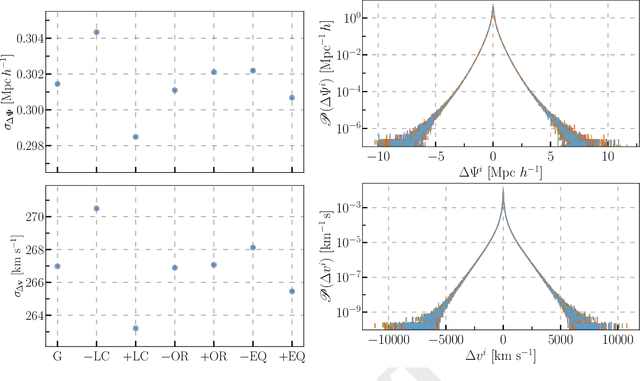
We build a field level emulator for cosmic structure formation that is accurate in the nonlinear regime. Our emulator consists of two convolutional neural networks trained to output the nonlinear displacements and velocities of N-body simulation particles based on their linear inputs. Cosmology dependence is encoded in the form of style parameters at each layer of the neural network, enabling the emulator to effectively interpolate the outcomes of structure formation between different flat $\Lambda$CDM cosmologies over a wide range of background matter densities. The neural network architecture makes the model differentiable by construction, providing a powerful tool for fast field level inference. We test the accuracy of our method by considering several summary statistics, including the density power spectrum with and without redshift space distortions, the displacement power spectrum, the momentum power spectrum, the density bispectrum, halo abundances, and halo profiles with and without redshift space distortions. We compare these statistics from our emulator with the full N-body results, the COLA method, and a fiducial neural network with no cosmological dependence. We find our emulator gives accurate results down to scales of $k \sim 1\ \mathrm{Mpc}^{-1}\, h$, representing a considerable improvement over both COLA and the fiducial neural network. We also demonstrate that our emulator generalizes well to initial conditions containing primordial non-Gaussianity, without the need for any additional style parameters or retraining.
EnergyMatch: Energy-based Pseudo-Labeling for Semi-Supervised Learning
Jun 13, 2022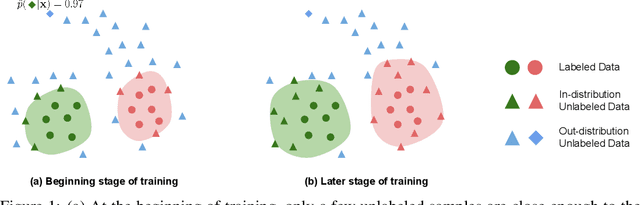

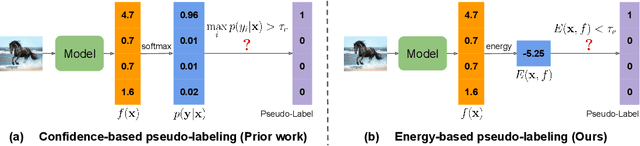
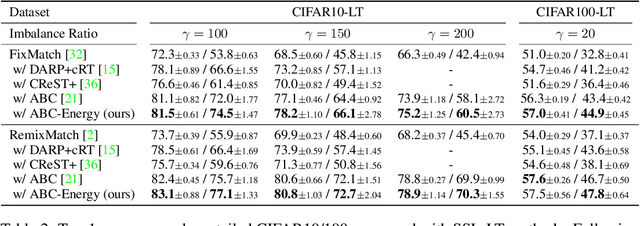
Recent state-of-the-art methods in semi-supervised learning (SSL) combine consistency regularization with confidence-based pseudo-labeling. To obtain high-quality pseudo-labels, a high confidence threshold is typically adopted. However, it has been shown that softmax-based confidence scores in deep networks can be arbitrarily high for samples far from the training data, and thus, the pseudo-labels for even high-confidence unlabeled samples may still be unreliable. In this work, we present a new perspective of pseudo-labeling: instead of relying on model confidence, we instead measure whether an unlabeled sample is likely to be "in-distribution"; i.e., close to the current training data. To classify whether an unlabeled sample is "in-distribution" or "out-of-distribution", we adopt the energy score from out-of-distribution detection literature. As training progresses and more unlabeled samples become in-distribution and contribute to training, the combined labeled and pseudo-labeled data can better approximate the true distribution to improve the model. Experiments demonstrate that our energy-based pseudo-labeling method, albeit conceptually simple, significantly outperforms confidence-based methods on imbalanced SSL benchmarks, and achieves competitive performance on class-balanced data. For example, it produces a 4-6% absolute accuracy improvement on CIFAR10-LT when the imbalance ratio is higher than 50. When combined with state-of-the-art long-tailed SSL methods, further improvements are attained.
Physics to the Rescue: Deep Non-line-of-sight Reconstruction for High-speed Imaging
May 03, 2022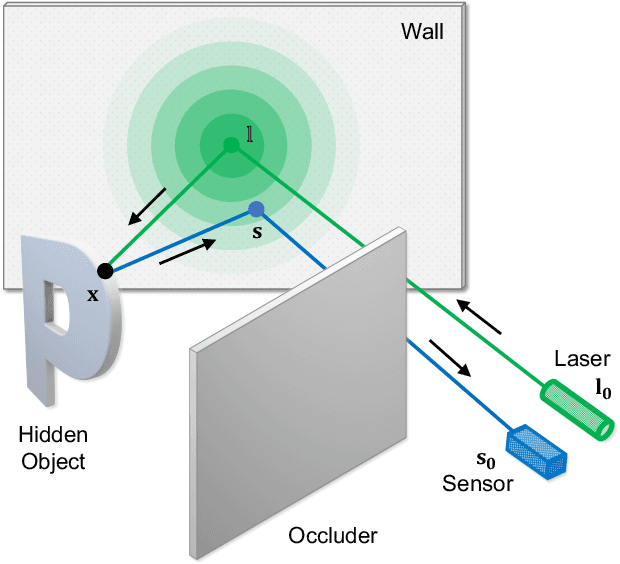
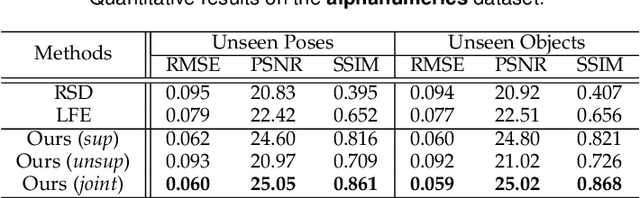
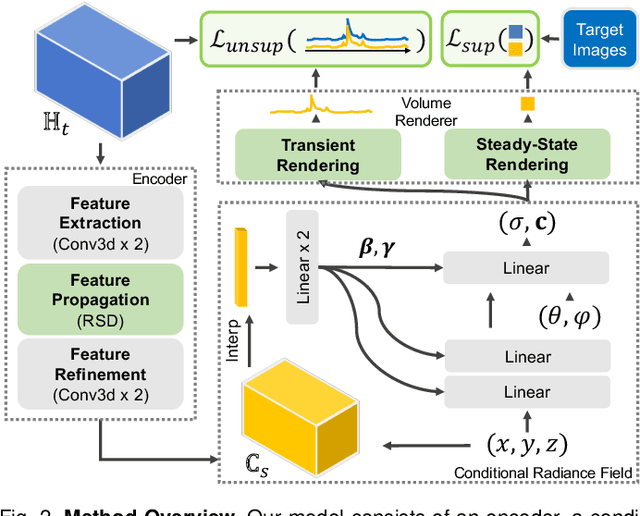
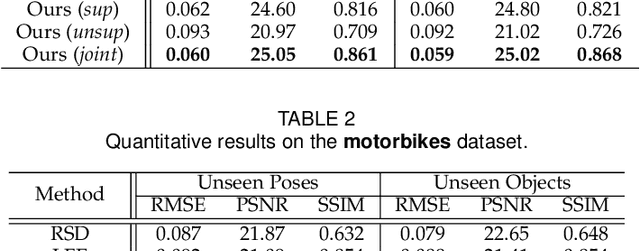
Computational approach to imaging around the corner, or non-line-of-sight (NLOS) imaging, is becoming a reality thanks to major advances in imaging hardware and reconstruction algorithms. A recent development towards practical NLOS imaging, Nam et al. demonstrated a high-speed non-confocal imaging system that operates at 5Hz, 100x faster than the prior art. This enormous gain in acquisition rate, however, necessitates numerous approximations in light transport, breaking many existing NLOS reconstruction methods that assume an idealized image formation model. To bridge the gap, we present a novel deep model that incorporates the complementary physics priors of wave propagation and volume rendering into a neural network for high-quality and robust NLOS reconstruction. This orchestrated design regularizes the solution space by relaxing the image formation model, resulting in a deep model that generalizes well on real captures despite being exclusively trained on synthetic data. Further, we devise a unified learning framework that enables our model to be flexibly trained using diverse supervision signals, including target intensity images or even raw NLOS transient measurements. Once trained, our model renders both intensity and depth images at inference time in a single forward pass, capable of processing more than 5 captures per second on a high-end GPU. Through extensive qualitative and quantitative experiments, we show that our method outperforms prior physics and learning based approaches on both synthetic and real measurements. We anticipate that our method along with the fast capturing system will accelerate future development of NLOS imaging for real world applications that require high-speed imaging.
ActionFormer: Localizing Moments of Actions with Transformers
Feb 16, 2022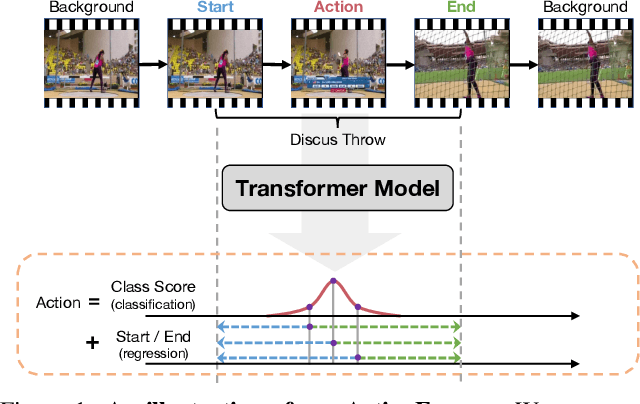
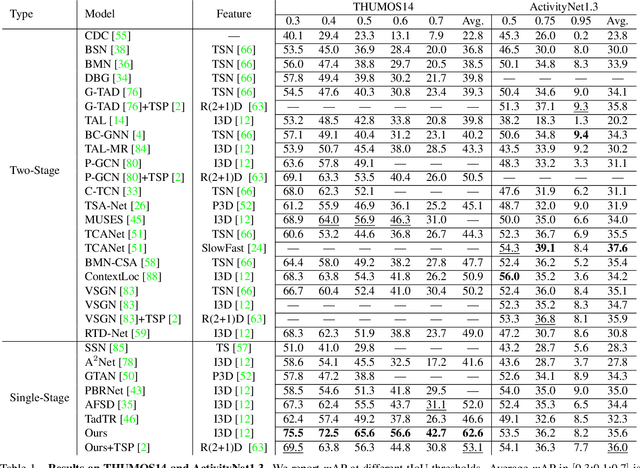
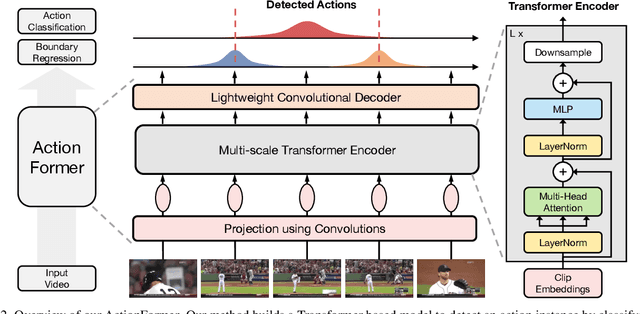
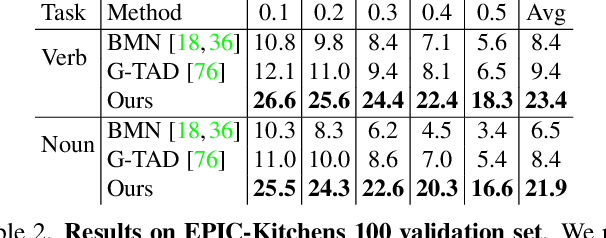
Self-attention based Transformer models have demonstrated impressive results for image classification and object detection, and more recently for video understanding. Inspired by this success, we investigate the application of Transformer networks for temporal action localization in videos. To this end, we present ActionFormer -- a simple yet powerful model to identify actions in time and recognize their categories in a single shot, without using action proposals or relying on pre-defined anchor windows. ActionFormer combines a multiscale feature representation with local self-attention, and uses a light-weighted decoder to classify every moment in time and estimate the corresponding action boundaries. We show that this orchestrated design results in major improvements upon prior works. Without bells and whistles, ActionFormer achieves 65.6% mAP at tIoU=0.5 on THUMOS14, outperforming the best prior model by 8.7 absolute percentage points and crossing the 60% mAP for the first time. Further, ActionFormer demonstrates strong results on ActivityNet 1.3 (36.0% average mAP) and the more recent EPIC-Kitchens 100 (+13.5% average mAP over prior works). Our code is available at http://github.com/happyharrycn/actionformer_release
The CAMELS project: public data release
Jan 04, 2022
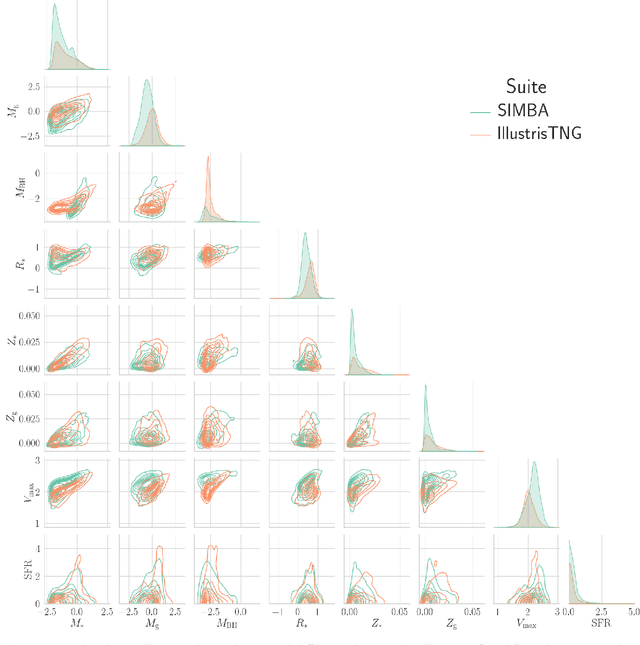
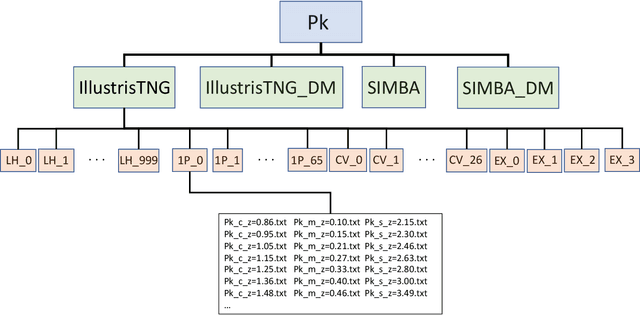
The Cosmology and Astrophysics with MachinE Learning Simulations (CAMELS) project was developed to combine cosmology with astrophysics through thousands of cosmological hydrodynamic simulations and machine learning. CAMELS contains 4,233 cosmological simulations, 2,049 N-body and 2,184 state-of-the-art hydrodynamic simulations that sample a vast volume in parameter space. In this paper we present the CAMELS public data release, describing the characteristics of the CAMELS simulations and a variety of data products generated from them, including halo, subhalo, galaxy, and void catalogues, power spectra, bispectra, Lyman-$\alpha$ spectra, probability distribution functions, halo radial profiles, and X-rays photon lists. We also release over one thousand catalogues that contain billions of galaxies from CAMELS-SAM: a large collection of N-body simulations that have been combined with the Santa Cruz Semi-Analytic Model. We release all the data, comprising more than 350 terabytes and containing 143,922 snapshots, millions of halos, galaxies and summary statistics. We provide further technical details on how to access, download, read, and process the data at \url{https://camels.readthedocs.io}.
Virtuoso: Video-based Intelligence for real-time tuning on SOCs
Dec 24, 2021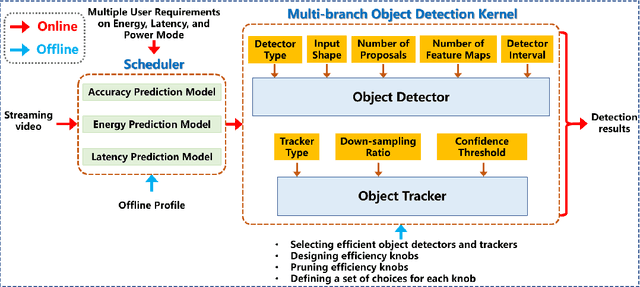
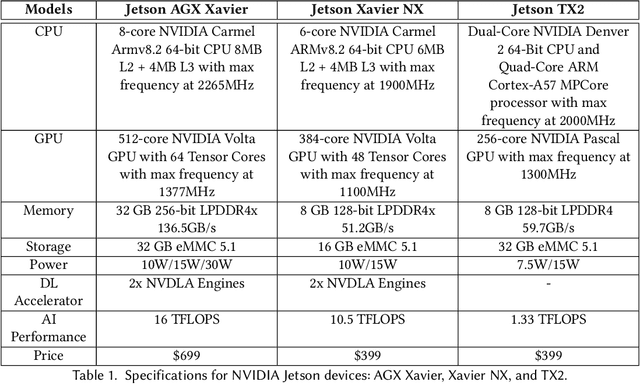
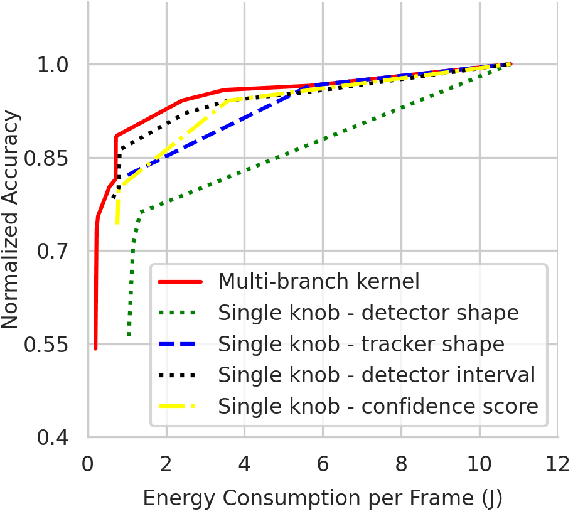
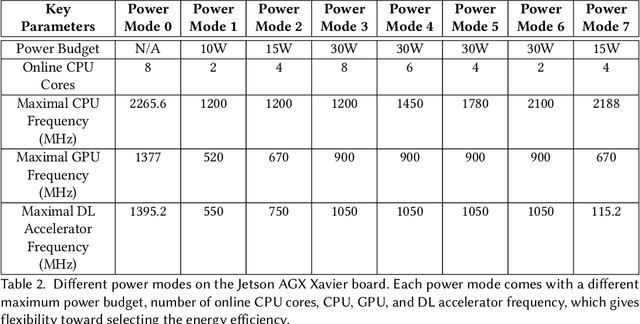
Efficient and adaptive computer vision systems have been proposed to make computer vision tasks, such as image classification and object detection, optimized for embedded or mobile devices. These solutions, quite recent in their origin, focus on optimizing the model (a deep neural network, DNN) or the system by designing an adaptive system with approximation knobs. In spite of several recent efforts, we show that existing solutions suffer from two major drawbacks. First, the system does not consider energy consumption of the models while making a decision on which model to run. Second, the evaluation does not consider the practical scenario of contention on the device, due to other co-resident workloads. In this work, we propose an efficient and adaptive video object detection system, Virtuoso, which is jointly optimized for accuracy, energy efficiency, and latency. Underlying Virtuoso is a multi-branch execution kernel that is capable of running at different operating points in the accuracy-energy-latency axes, and a lightweight runtime scheduler to select the best fit execution branch to satisfy the user requirement. To fairly compare with Virtuoso, we benchmark 15 state-of-the-art or widely used protocols, including Faster R-CNN (FRCNN), YOLO v3, SSD, EfficientDet, SELSA, MEGA, REPP, FastAdapt, and our in-house adaptive variants of FRCNN+, YOLO+, SSD+, and EfficientDet+ (our variants have enhanced efficiency for mobiles). With this comprehensive benchmark, Virtuoso has shown superiority to all the above protocols, leading the accuracy frontier at every efficiency level on NVIDIA Jetson mobile GPUs. Specifically, Virtuoso has achieved an accuracy of 63.9%, which is more than 10% higher than some of the popular object detection models, FRCNN at 51.1%, and YOLO at 49.5%.
RegionCLIP: Region-based Language-Image Pretraining
Dec 16, 2021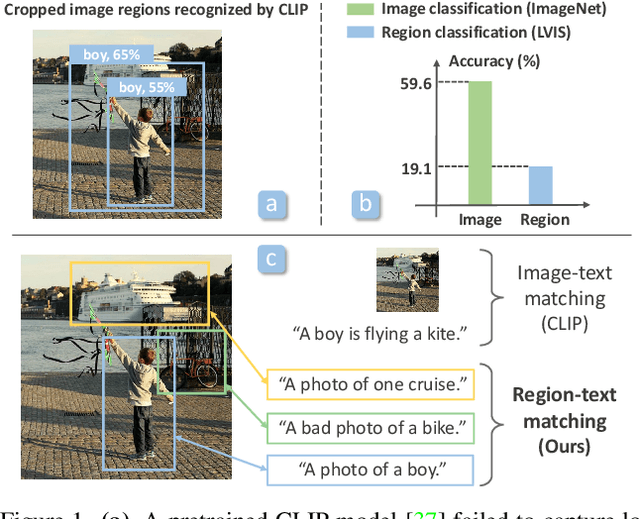
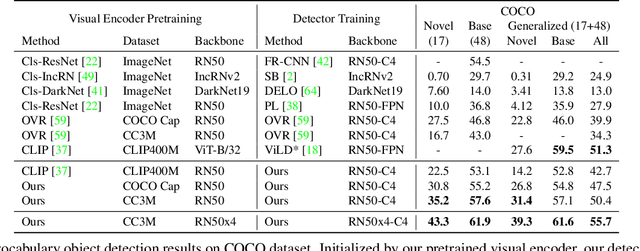
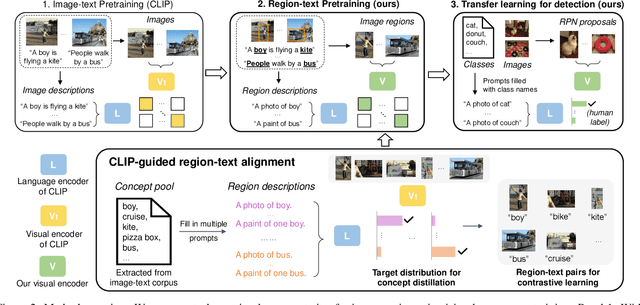
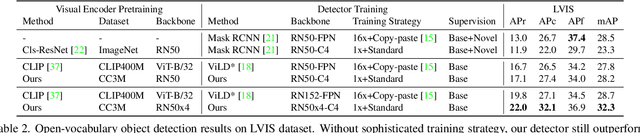
Contrastive language-image pretraining (CLIP) using image-text pairs has achieved impressive results on image classification in both zero-shot and transfer learning settings. However, we show that directly applying such models to recognize image regions for object detection leads to poor performance due to a domain shift: CLIP was trained to match an image as a whole to a text description, without capturing the fine-grained alignment between image regions and text spans. To mitigate this issue, we propose a new method called RegionCLIP that significantly extends CLIP to learn region-level visual representations, thus enabling fine-grained alignment between image regions and textual concepts. Our method leverages a CLIP model to match image regions with template captions and then pretrains our model to align these region-text pairs in the feature space. When transferring our pretrained model to the open-vocabulary object detection tasks, our method significantly outperforms the state of the art by 3.8 AP50 and 2.2 AP for novel categories on COCO and LVIS datasets, respectively. Moreoever, the learned region representations support zero-shot inference for object detection, showing promising results on both COCO and LVIS datasets. Our code is available at https://github.com/microsoft/RegionCLIP.