 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text
Apr 22, 2021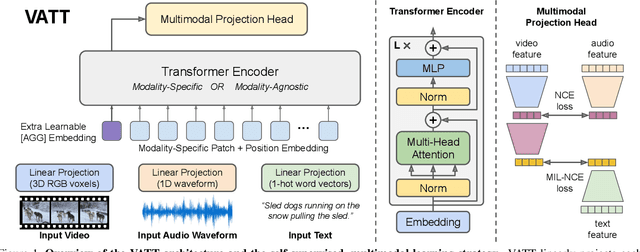
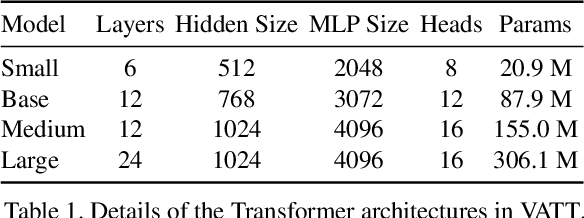
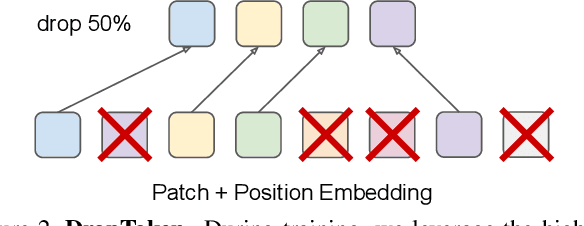
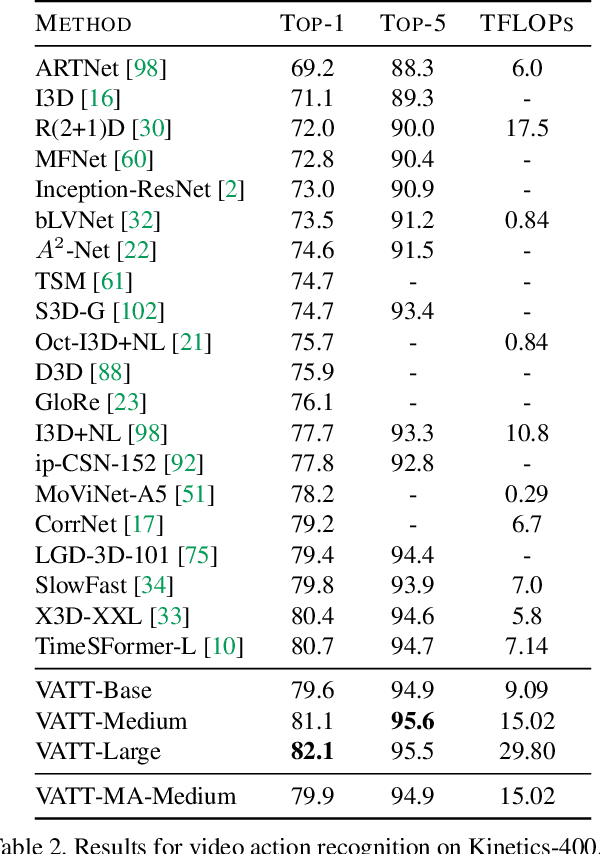
We present a framework for learning multimodal representations from unlabeled data using convolution-free Transformer architectures. Specifically, our Video-Audio-Text Transformer (VATT) takes raw signals as inputs and extracts multimodal representations that are rich enough to benefit a variety of downstream tasks. We train VATT end-to-end from scratch using multimodal contrastive losses and evaluate its performance by the downstream tasks of video action recognition, audio event classification, image classification, and text-to-video retrieval. Furthermore, we study a modality-agnostic single-backbone Transformer by sharing weights among the three modalities. We show that the convolution-free VATT outperforms state-of-the-art ConvNet-based architectures in the downstream tasks. Especially, VATT's vision Transformer achieves the top-1 accuracy of 82.1% on Kinetics-400, 83.6% on Kinetics-600,and 41.1% on Moments in Time, new records while avoiding supervised pre-training. Transferring to image classification leads to 78.7% top-1 accuracy on ImageNet compared to 64.7% by training the same Transformer from scratch, showing the generalizability of our model despite the domain gap between videos and images. VATT's audio Transformer also sets a new record on waveform-based audio event recognition by achieving the mAP of 39.4% on AudioSet without any supervised pre-training.
Simple Copy-Paste is a Strong Data Augmentation Method for Instance Segmentation
Dec 13, 2020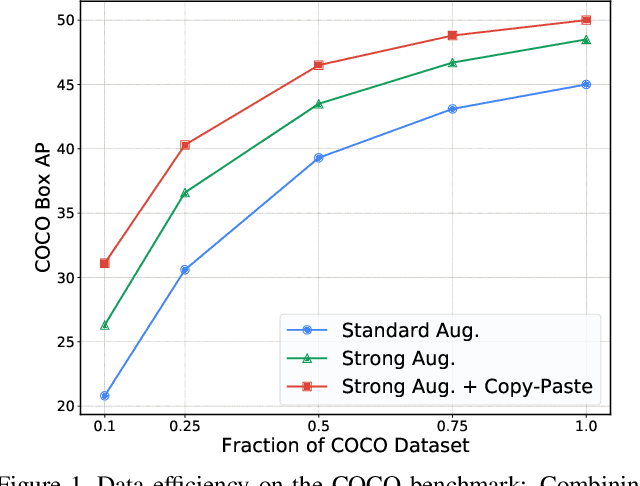
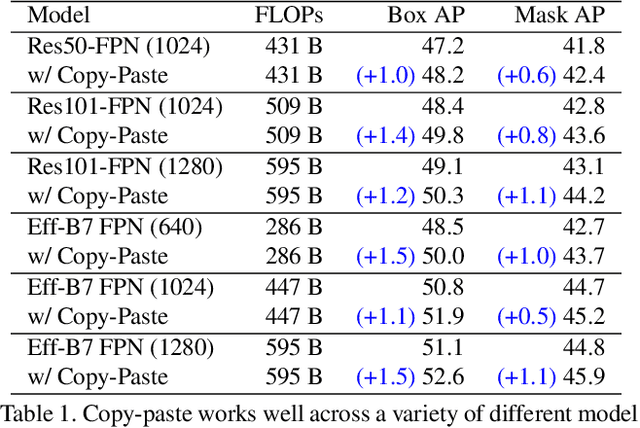

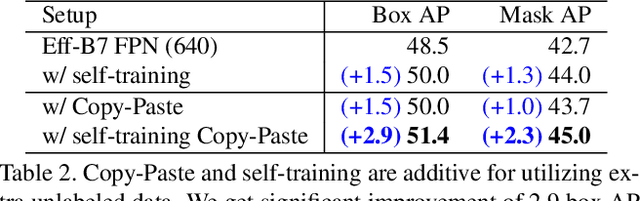
Building instance segmentation models that are data-efficient and can handle rare object categories is an important challenge in computer vision. Leveraging data augmentations is a promising direction towards addressing this challenge. Here, we perform a systematic study of the Copy-Paste augmentation ([13, 12]) for instance segmentation where we randomly paste objects onto an image. Prior studies on Copy-Paste relied on modeling the surrounding visual context for pasting the objects. However, we find that the simple mechanism of pasting objects randomly is good enough and can provide solid gains on top of strong baselines. Furthermore, we show Copy-Paste is additive with semi-supervised methods that leverage extra data through pseudo labeling (e.g. self-training). On COCO instance segmentation, we achieve 49.1 mask AP and 57.3 box AP, an improvement of +0.6 mask AP and +1.5 box AP over the previous state-of-the-art. We further demonstrate that Copy-Paste can lead to significant improvements on the LVIS benchmark. Our baseline model outperforms the LVIS 2020 Challenge winning entry by +3.6 mask AP on rare categories.
Efficient Scale-Permuted Backbone with Learned Resource Distribution
Oct 22, 2020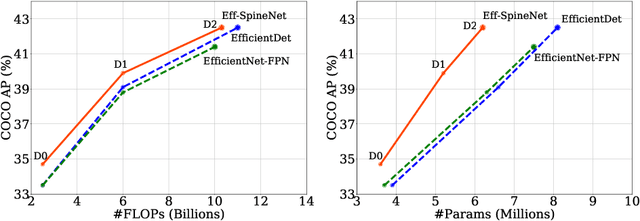
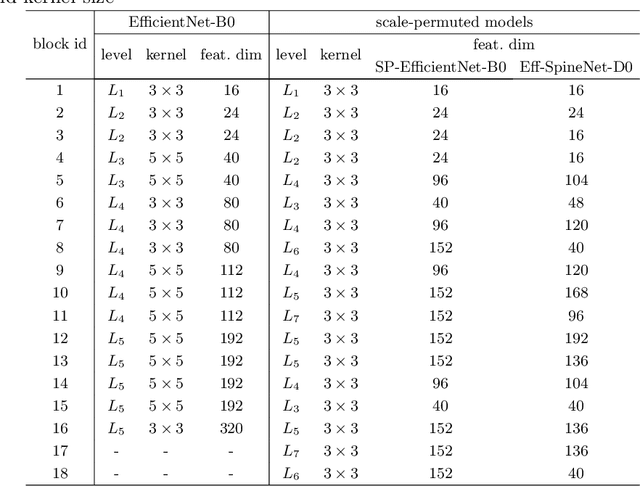
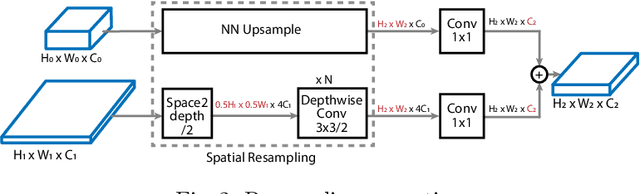

Recently, SpineNet has demonstrated promising results on object detection and image classification over ResNet model. However, it is unclear if the improvement adds up when combining scale-permuted backbone with advanced efficient operations and compound scaling. Furthermore, SpineNet is built with a uniform resource distribution over operations. While this strategy seems to be prevalent for scale-decreased models, it may not be an optimal design for scale-permuted models. In this work, we propose a simple technique to combine efficient operations and compound scaling with a previously learned scale-permuted architecture. We demonstrate the efficiency of scale-permuted model can be further improved by learning a resource distribution over the entire network. The resulting efficient scale-permuted models outperform state-of-the-art EfficientNet-based models on object detection and achieve competitive performance on image classification and semantic segmentation. Code and models will be open-sourced soon.
Small-floating Target Detection in Sea Clutter via Visual Feature Classifying in the Time-Doppler Spectra
Sep 09, 2020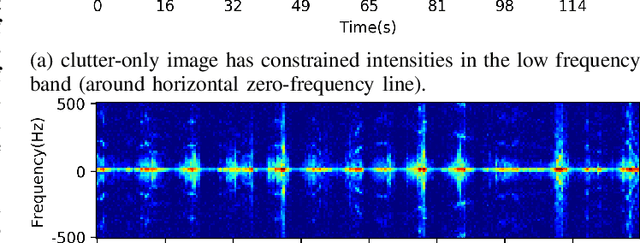
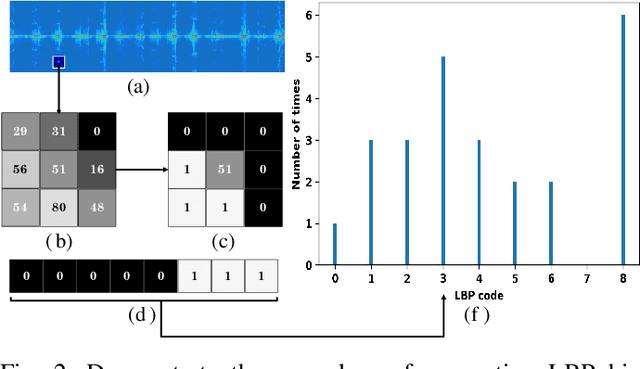
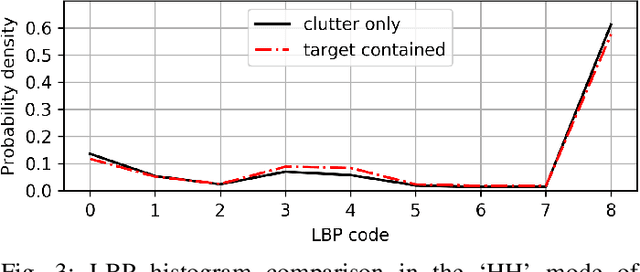
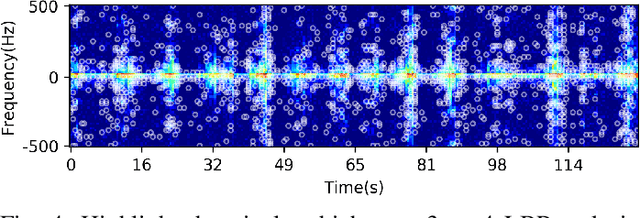
It is challenging to detect small-floating object in the sea clutter for a surface radar. In this paper, we have observed that the backscatters from the target brake the continuity of the underlying motion of the sea surface in the time-Doppler spectra (TDS) images. Following this visual clue, we exploit the local binary pattern (LBP) to measure the variations of texture in the TDS images. It is shown that the radar returns containing target and those only having clutter are separable in the feature space of LBP. An unsupervised one-class support vector machine (SVM) is then utilized to detect the deviation of the LBP histogram of the clutter. The outiler of the detector is classified as the target. In the real-life IPIX radar data sets, our visual feature based detector shows favorable detection rate compared to other three existing approaches.
Spatiotemporal Contrastive Video Representation Learning
Aug 09, 2020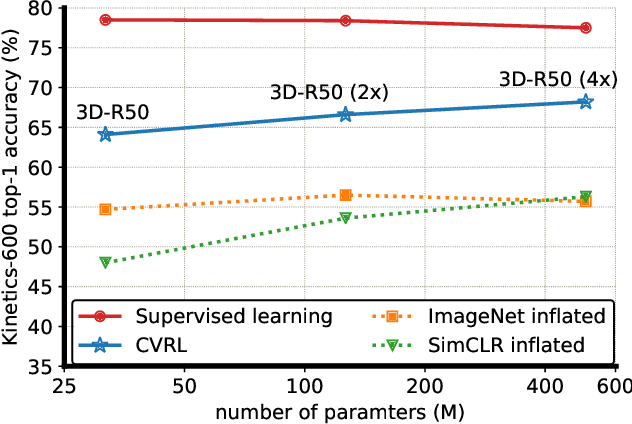

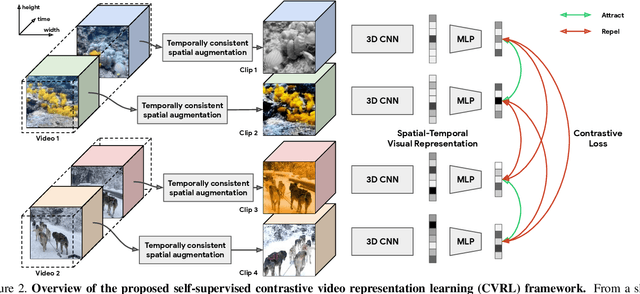
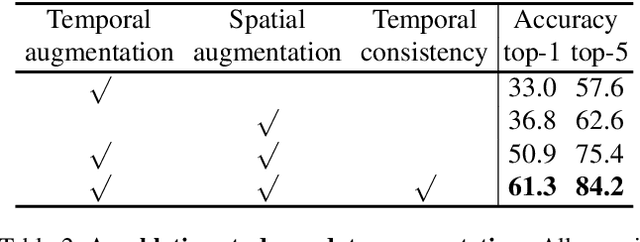
We present a self-supervised Contrastive Video Representation Learning (CVRL) method to learn spatiotemporal visual representations from unlabeled videos. Inspired by the recently proposed self-supervised contrastive learning framework, our representations are learned using a contrastive loss, where two clips from the same short video are pulled together in the embedding space, while clips from different videos are pushed away. We study what makes for good data augmentation for video self-supervised learning and find both spatial and temporal information are crucial. In particular, we propose a simple yet effective temporally consistent spatial augmentation method to impose strong spatial augmentations on each frame of a video clip while maintaining the temporal consistency across frames. For Kinetics-600 action recognition, a linear classifier trained on representations learned by CVRL achieves 64.1\% top-1 accuracy with a 3D-ResNet50 backbone, outperforming ImageNet supervised pre-training by 9.4\% and SimCLR unsupervised pre-training by 16.1\% using the same inflated 3D-ResNet50. The performance of CVRL can be further improved to 68.2\% with a larger 3D-ResNet50 (4$\times$) backbone, significantly closing the gap between unsupervised and supervised video representation learning.
Rethinking Pre-training and Self-training
Jun 11, 2020
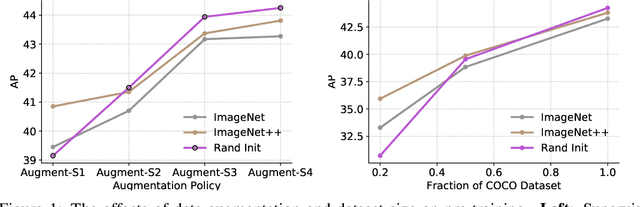

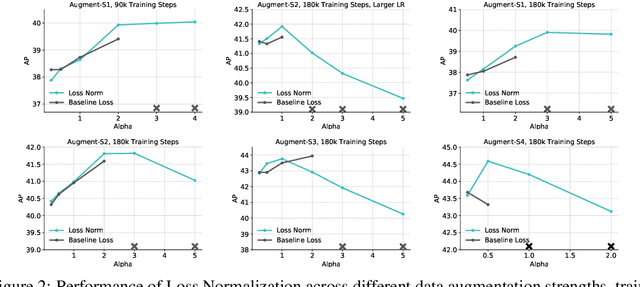
Pre-training is a dominant paradigm in computer vision. For example, supervised ImageNet pre-training is commonly used to initialize the backbones of object detection and segmentation models. He et al., however, show a surprising result that ImageNet pre-training has limited impact on COCO object detection. Here we investigate self-training as another method to utilize additional data on the same setup and contrast it against ImageNet pre-training. Our study reveals the generality and flexibility of self-training with three additional insights: 1) stronger data augmentation and more labeled data further diminish the value of pre-training, 2) unlike pre-training, self-training is always helpful when using stronger data augmentation, in both low-data and high-data regimes, and 3) in the case that pre-training is helpful, self-training improves upon pre-training. For example, on the COCO object detection dataset, pre-training benefits when we use one fifth of the labeled data, and hurts accuracy when we use all labeled data. Self-training, on the other hand, shows positive improvements from +1.3 to +3.4AP across all dataset sizes. In other words, self-training works well exactly on the same setup that pre-training does not work (using ImageNet to help COCO). On the PASCAL segmentation dataset, which is a much smaller dataset than COCO, though pre-training does help significantly, self-training improves upon the pre-trained model. On COCO object detection, we achieve 54.3AP, an improvement of +1.5AP over the strongest SpineNet model. On PASCAL segmentation, we achieve 90.5 mIOU, an improvement of +1.5% mIOU over the previous state-of-the-art result by DeepLabv3+.
Fashionpedia: Ontology, Segmentation, and an Attribute Localization Dataset
Apr 26, 2020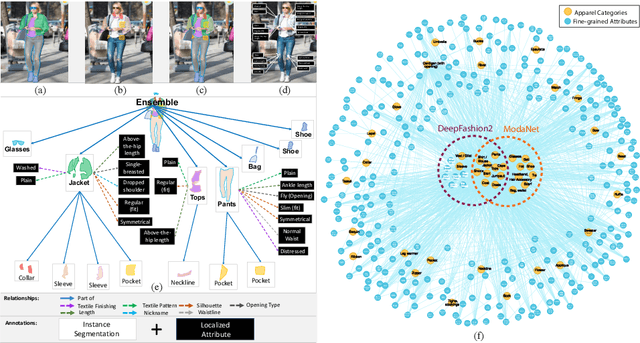


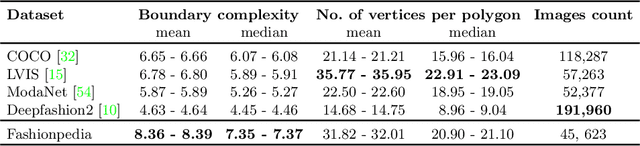
In this work we explore the task of instance segmentation with attribute localization, which unifies instance segmentation (detect and segment each object instance) and fine-grained visual attribute categorization (recognize one or multiple attributes). The proposed task requires both localizing an object and describing its properties. To illustrate the various aspects of this task, we focus on the domain of fashion and introduce Fashionpedia as a step toward mapping out the visual aspects of the fashion world. Fashionpedia consists of two parts: (1) an ontology built by fashion experts containing 27 main apparel categories, 19 apparel parts, 294 fine-grained attributes and their relationships; (2) a dataset with everyday and celebrity event fashion images annotated with segmentation masks and their associated per-mask fine-grained attributes, built upon the Fashionpedia ontology. In order to solve this challenging task, we propose a novel Attribute-Mask RCNN model to jointly perform instance segmentation and localized attribute recognition, and provide a novel evaluation metric for the task. We also demonstrate instance segmentation models pre-trained on Fashionpedia achieve better transfer learning performance on other fashion datasets than ImageNet pre-training. Fashionpedia is available at: https://fashionpedia.github.io/home/index.html.
Measuring Dataset Granularity
Dec 21, 2019
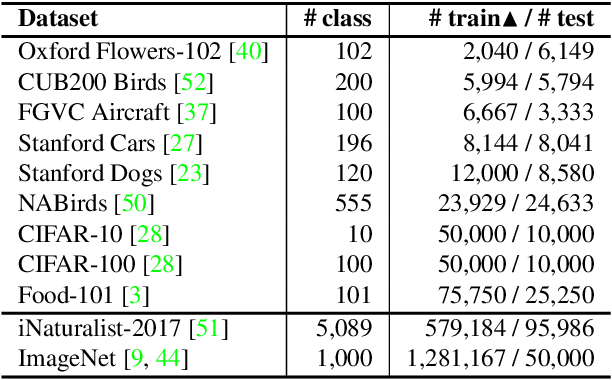
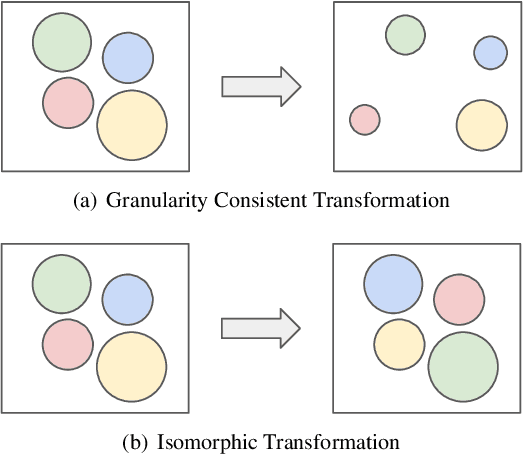
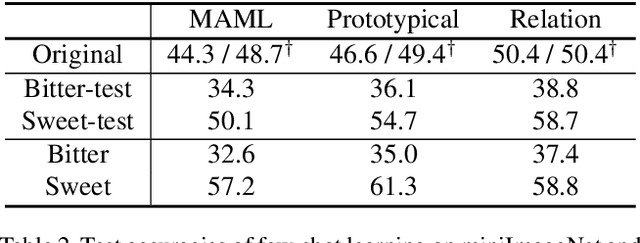
Despite the increasing visibility of fine-grained recognition in our field, "fine-grained'' has thus far lacked a precise definition. In this work, building upon clustering theory, we pursue a framework for measuring dataset granularity. We argue that dataset granularity should depend not only on the data samples and their labels, but also on the distance function we choose. We propose an axiomatic framework to capture desired properties for a dataset granularity measure and provide examples of measures that satisfy these properties. We assess each measure via experiments on datasets with hierarchical labels of varying granularity. When measuring granularity in commonly used datasets with our measure, we find that certain datasets that are widely considered fine-grained in fact contain subsets of considerable size that are substantially more coarse-grained than datasets generally regarded as coarse-grained. We also investigate the interplay between dataset granularity with a variety of factors and find that fine-grained datasets are more difficult to learn from, more difficult to transfer to, more difficult to perform few-shot learning with, and more vulnerable to adversarial attacks.
SpineNet: Learning Scale-Permuted Backbone for Recognition and Localization
Dec 10, 2019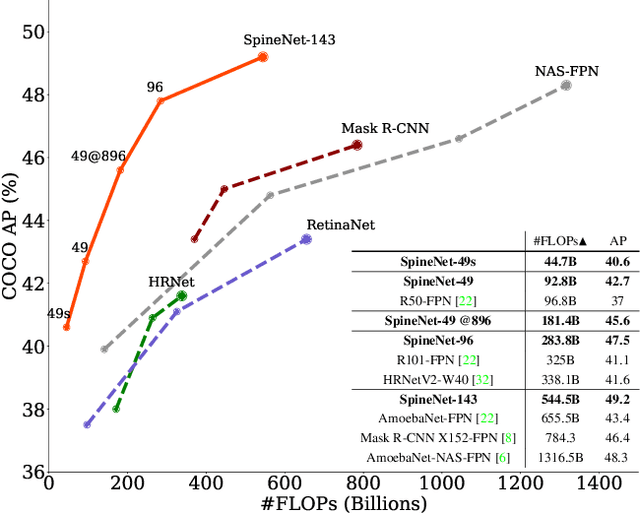
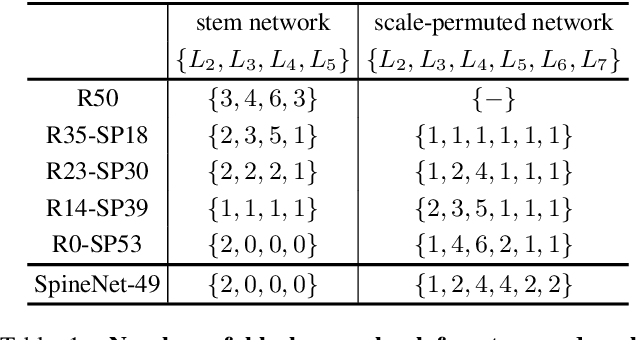
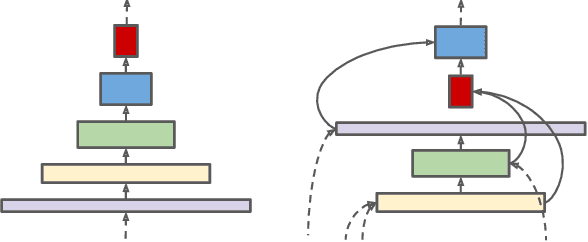
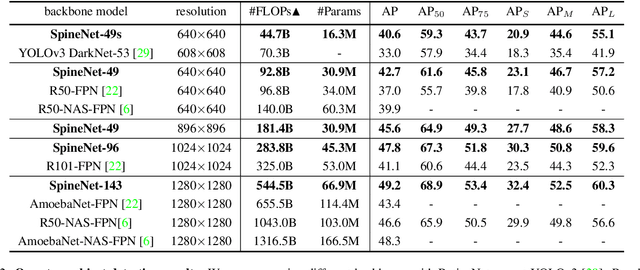
Convolutional neural networks typically encode an input image into a series of intermediate features with decreasing resolutions. While this structure is suited to classification tasks, it does not perform well for tasks requiring simultaneous recognition and localization (e.g., object detection). The encoder-decoder architectures are proposed to resolve this by applying a decoder network onto a backbone model designed for classification tasks. In this paper, we argue that encoder-decoder architecture is ineffective in generating strong multi-scale features because of the scale-decreased backbone. We propose SpineNet, a backbone with scale-permuted intermediate features and cross-scale connections that is learned on an object detection task by Neural Architecture Search. SpineNet achieves state-of-the-art performance of one-stage object detector on COCO with 60% less computation, and outperforms ResNet-FPN counterparts by 6% AP. SpineNet architecture can transfer to classification tasks, achieving 6% top-1 accuracy improvement on a challenging iNaturalist fine-grained dataset.
The iMaterialist Fashion Attribute Dataset
Jun 14, 2019
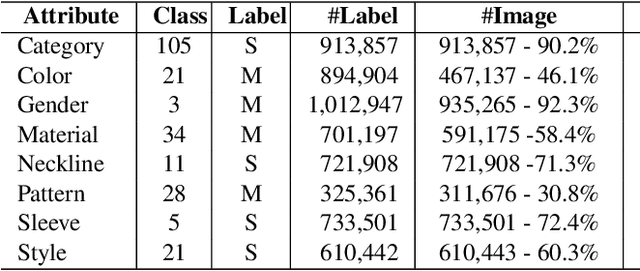
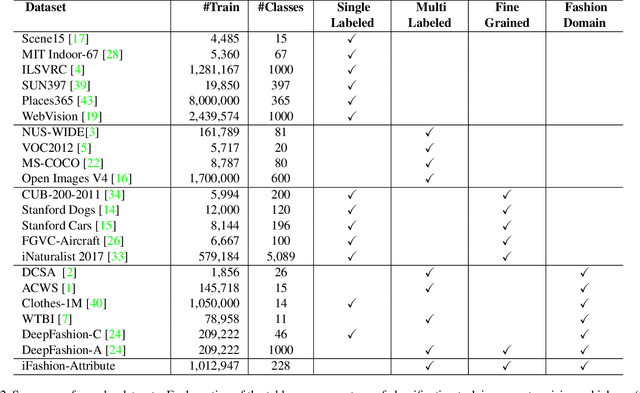
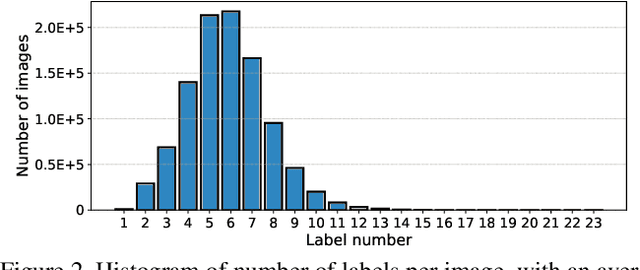
Large-scale image databases such as ImageNet have significantly advanced image classification and other visual recognition tasks. However much of these datasets are constructed only for single-label and coarse object-level classification. For real-world applications, multiple labels and fine-grained categories are often needed, yet very few such datasets exist publicly, especially those of large-scale and high quality. In this work, we contribute to the community a new dataset called iMaterialist Fashion Attribute (iFashion-Attribute) to address this problem in the fashion domain. The dataset is constructed from over one million fashion images with a label space that includes 8 groups of 228 fine-grained attributes in total. Each image is annotated by experts with multiple, high-quality fashion attributes. The result is the first known million-scale multi-label and fine-grained image dataset. We conduct extensive experiments and provide baseline results with modern deep Convolutional Neural Networks (CNNs). Additionally, we demonstrate models pre-trained on iFashion-Attribute achieve superior transfer learning performance on fashion related tasks compared with pre-training from ImageNet or other fashion datasets. Data is available at: https://github.com/visipedia/imat_fashion_comp