 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamerAD: Efficient Reinforcement Learning via Latent World Model for Autonomous Driving
Mar 25, 2026We introduce DreamerAD, the first latent world model framework that enables efficient reinforcement learning for autonomous driving by compressing diffusion sampling from 100 steps to 1 - achieving 80x speedup while maintaining visual interpretability. Training RL policies on real-world driving data incurs prohibitive costs and safety risks. While existing pixel-level diffusion world models enable safe imagination-based training, they suffer from multi-step diffusion inference latency (2s/frame) that prevents high-frequency RL interaction. Our approach leverages denoised latent features from video generation models through three key mechanisms: (1) shortcut forcing that reduces sampling complexity via recursive multi-resolution step compression, (2) an autoregressive dense reward model operating directly on latent representations for fine-grained credit assignment, and (3) Gaussian vocabulary sampling for GRPO that constrains exploration to physically plausible trajectories. DreamerAD achieves 87.7 EPDMS on NavSim v2, establishing state-of-the-art performance and demonstrating that latent-space RL is effective for autonomous driving.
Latent-WAM: Latent World Action Modeling for End-to-End Autonomous Driving
Mar 25, 2026We introduce Latent-WAM, an efficient end-to-end autonomous driving framework that achieves strong trajectory planning through spatially-aware and dynamics-informed latent world representations. Existing world-model-based planners suffer from inadequately compressed representations, limited spatial understanding, and underutilized temporal dynamics, resulting in sub-optimal planning under constrained data and compute budgets. Latent-WAM addresses these limitations with two core modules: a Spatial-Aware Compressive World Encoder (SCWE) that distills geometric knowledge from a foundation model and compresses multi-view images into compact scene tokens via learnable queries, and a Dynamic Latent World Model (DLWM) that employs a causal Transformer to autoregressively predict future world status conditioned on historical visual and motion representations. Extensive experiments on NAVSIM v2 and HUGSIM demonstrate new state-of-the-art results: 89.3 EPDMS on NAVSIM v2 and 28.9 HD-Score on HUGSIM, surpassing the best prior perception-free method by 3.2 EPDMS with significantly less training data and a compact 104M-parameter model.
DexViTac: Collecting Human Visuo-Tactile-Kinematic Demonstrations for Contact-Rich Dexterous Manipulation
Mar 18, 2026Large-scale, high-quality multimodal demonstrations are essential for robot learning of contact-rich dexterous manipulation. While human-centric data collection systems lower the barrier to scaling, they struggle to capture the tactile information during physical interactions. Motivated by this, we present DexViTac, a portable, human-centric data collection system tailored for contact-rich dexterous manipulation. The system enables the high-fidelity acquisition of first-person vision, high-density tactile sensing, end-effector poses, and hand kinematics within unstructured, in-the-wild environments. Building upon this hardware, we propose a kinematics-grounded tactile representation learning algorithm that effectively resolves semantic ambiguities within tactile signals. Leveraging the efficiency of DexViTac, we construct a multimodal dataset comprising over 2,400 visuo-tactile-kinematic demonstrations. Experiments demonstrate that DexViTac achieves a collection efficiency exceeding 248 demonstrations per hour and remains robust against complex visual occlusions. Real-world deployment confirms that policies trained with the proposed dataset and learning strategy achieve an average success rate exceeding 85% across four challenging tasks. This performance significantly outperforms baseline methods, thereby validating the substantial improvement the system provides for learning contact-rich dexterous manipulation. Project page: https://xitong-c.github.io/DexViTac/.
TakeAD: Preference-based Post-optimization for End-to-end Autonomous Driving with Expert Takeover Data
Dec 22, 2025



Existing end-to-end autonomous driving methods typically rely on imitation learning (IL) but face a key challenge: the misalignment between open-loop training and closed-loop deployment. This misalignment often triggers driver-initiated takeovers and system disengagements during closed-loop execution. How to leverage those expert takeover data from disengagement scenarios and effectively expand the IL policy's capability presents a valuable yet unexplored challenge. In this paper, we propose TakeAD, a novel preference-based post-optimization framework that fine-tunes the pre-trained IL policy with this disengagement data to enhance the closed-loop driving performance. First, we design an efficient expert takeover data collection pipeline inspired by human takeover mechanisms in real-world autonomous driving systems. Then, this post optimization framework integrates iterative Dataset Aggregation (DAgger) for imitation learning with Direct Preference Optimization (DPO) for preference alignment. The DAgger stage equips the policy with fundamental capabilities to handle disengagement states through direct imitation of expert interventions. Subsequently, the DPO stage refines the policy's behavior to better align with expert preferences in disengagement scenarios. Through multiple iterations, the policy progressively learns recovery strategies for disengagement states, thereby mitigating the open-loop gap. Experiments on the closed-loop Bench2Drive benchmark demonstrate our method's effectiveness compared with pure IL methods, with comprehensive ablations confirming the contribution of each component.
GraphAD: Interaction Scene Graph for End-to-end Autonomous Driving
Apr 07, 2024



Modeling complicated interactions among the ego-vehicle, road agents, and map elements has been a crucial part for safety-critical autonomous driving. Previous works on end-to-end autonomous driving rely on the attention mechanism for handling heterogeneous interactions, which fails to capture the geometric priors and is also computationally intensive. In this paper, we propose the Interaction Scene Graph (ISG) as a unified method to model the interactions among the ego-vehicle, road agents, and map elements. With the representation of the ISG, the driving agents aggregate essential information from the most influential elements, including the road agents with potential collisions and the map elements to follow. Since a mass of unnecessary interactions are omitted, the more efficient scene-graph-based framework is able to focus on indispensable connections and leads to better performance. We evaluate the proposed method for end-to-end autonomous driving on the nuScenes dataset. Compared with strong baselines, our method significantly outperforms in the full-stack driving tasks, including perception, prediction, and planning. Code will be released at https://github.com/zhangyp15/GraphAD.
V2X-Seq: A Large-Scale Sequential Dataset for Vehicle-Infrastructure Cooperative Perception and Forecasting
May 10, 2023



Utilizing infrastructure and vehicle-side information to track and forecast the behaviors of surrounding traffic participants can significantly improve decision-making and safety in autonomous driving. However, the lack of real-world sequential datasets limits research in this area. To address this issue, we introduce V2X-Seq, the first large-scale sequential V2X dataset, which includes data frames, trajectories, vector maps, and traffic lights captured from natural scenery. V2X-Seq comprises two parts: the sequential perception dataset, which includes more than 15,000 frames captured from 95 scenarios, and the trajectory forecasting dataset, which contains about 80,000 infrastructure-view scenarios, 80,000 vehicle-view scenarios, and 50,000 cooperative-view scenarios captured from 28 intersections' areas, covering 672 hours of data. Based on V2X-Seq, we introduce three new tasks for vehicle-infrastructure cooperative (VIC) autonomous driving: VIC3D Tracking, Online-VIC Forecasting, and Offline-VIC Forecasting. We also provide benchmarks for the introduced tasks. Find data, code, and more up-to-date information at \href{https://github.com/AIR-THU/DAIR-V2X-Seq}{https://github.com/AIR-THU/DAIR-V2X-Seq}.
A High Fidelity Simulation Framework for Potential Safety Benefits Estimation of Cooperative Pedestrian Perception
Oct 18, 2022
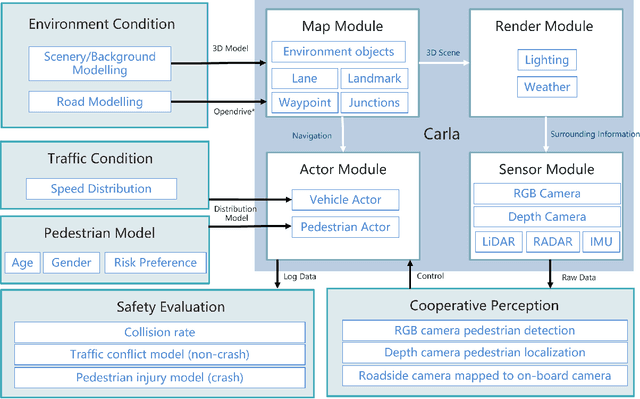
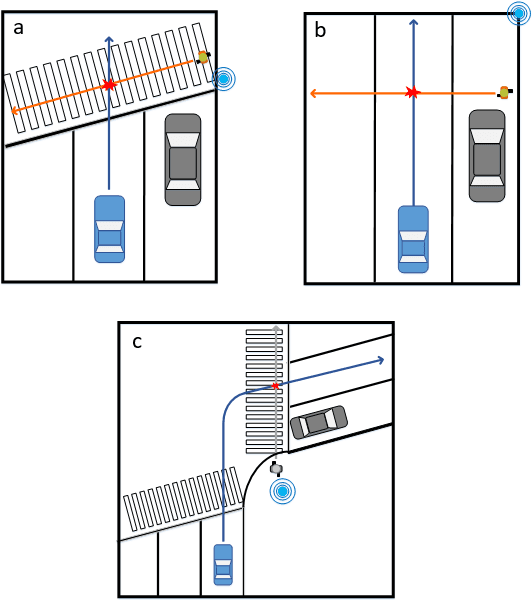
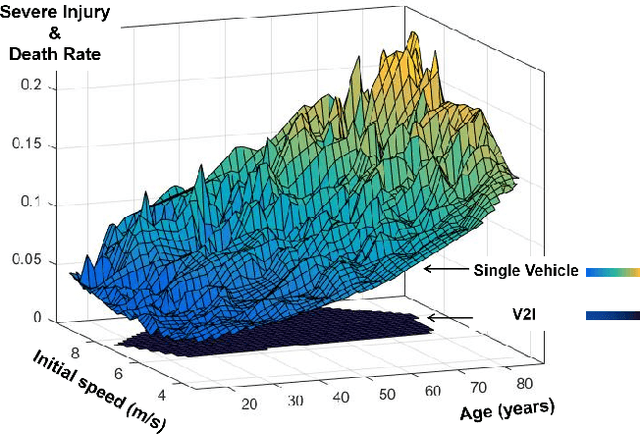
This paper proposes a high-fidelity simulation framework that can estimate the potential safety benefits of vehicle-to-infrastructure (V2I) pedestrian safety strategies. This simulator can support cooperative perception algorithms in the loop by simulating the environmental conditions, traffic conditions, and pedestrian characteristics at the same time. Besides, the benefit estimation model applied in our framework can systematically quantify both the risk conflict (non-crash condition) and the severity of the pedestrian's injuries (crash condition). An experiment was conducted in this paper that built a digital twin of a crowded urban intersection in China. The result shows that our framework is efficient for safety benefit estimation of V2I pedestrian safety strategies.
Text Flow: A Unified Text Detection System in Natural Scene Images
Apr 23, 2016
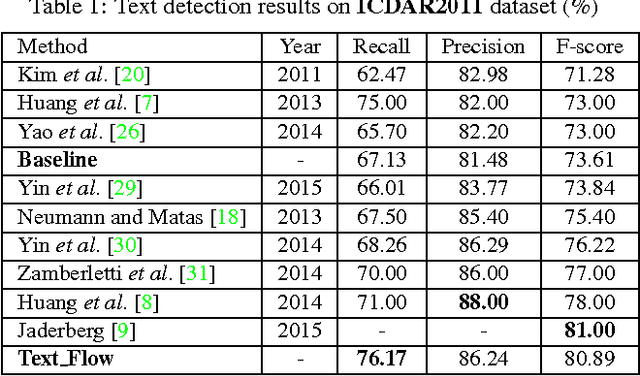
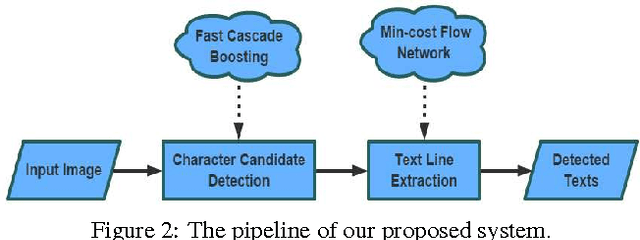
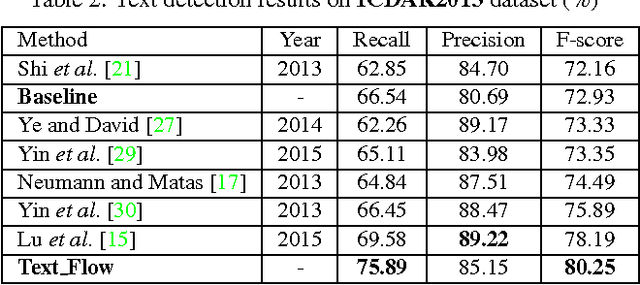
The prevalent scene text detection approach follows four sequential steps comprising character candidate detection, false character candidate removal, text line extraction, and text line verification. However, errors occur and accumulate throughout each of these sequential steps which often lead to low detection performance. To address these issues, we propose a unified scene text detection system, namely Text Flow, by utilizing the minimum cost (min-cost) flow network model. With character candidates detected by cascade boosting, the min-cost flow network model integrates the last three sequential steps into a single process which solves the error accumulation problem at both character level and text line level effectively. The proposed technique has been tested on three public datasets, i.e, ICDAR2011 dataset, ICDAR2013 dataset and a multilingual dataset and it outperforms the state-of-the-art methods on all three datasets with much higher recall and F-score. The good performance on the multilingual dataset shows that the proposed technique can be used for the detection of texts in different languages.