 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSO: Multi-Feature Space Joint Optimization Network for RGB-Infrared Person Re-Identification
Oct 21, 2021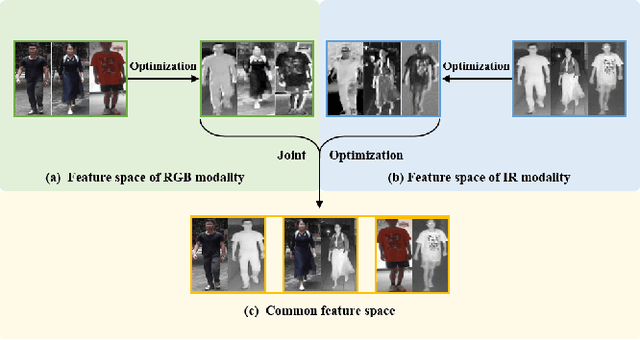
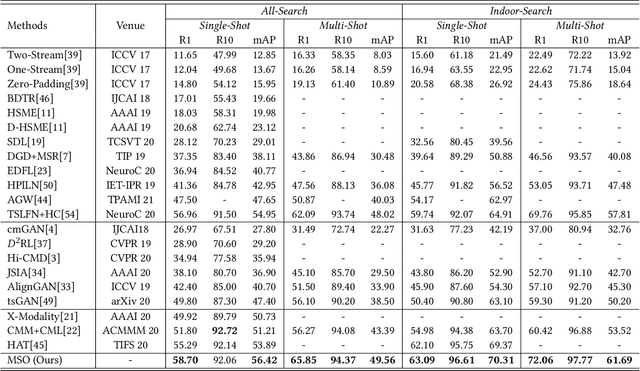
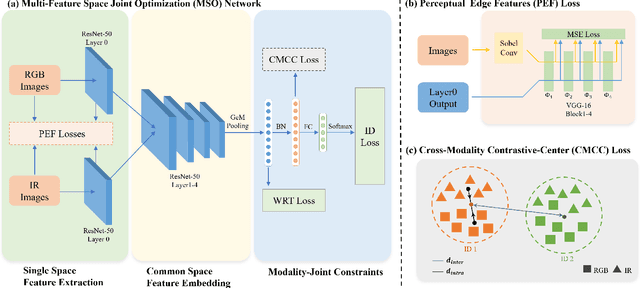
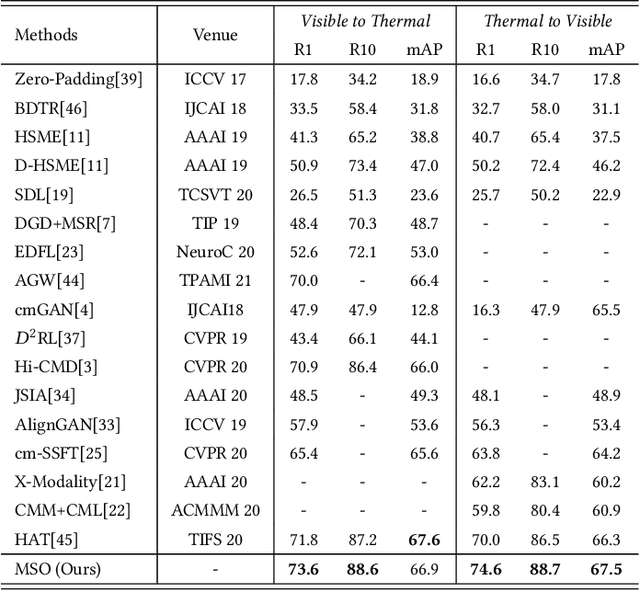
The RGB-infrared cross-modality person re-identification (ReID) task aims to recognize the images of the same identity between the visible modality and the infrared modality. Existing methods mainly use a two-stream architecture to eliminate the discrepancy between the two modalities in the final common feature space, which ignore the single space of each modality in the shallow layers. To solve it, in this paper, we present a novel multi-feature space joint optimization (MSO) network, which can learn modality-sharable features in both the single-modality space and the common space. Firstly, based on the observation that edge information is modality-invariant, we propose an edge features enhancement module to enhance the modality-sharable features in each single-modality space. Specifically, we design a perceptual edge features (PEF) loss after the edge fusion strategy analysis. According to our knowledge, this is the first work that proposes explicit optimization in the single-modality feature space on cross-modality ReID task. Moreover, to increase the difference between cross-modality distance and class distance, we introduce a novel cross-modality contrastive-center (CMCC) loss into the modality-joint constraints in the common feature space. The PEF loss and CMCC loss jointly optimize the model in an end-to-end manner, which markedly improves the network's performance. Extensive experiments demonstrate that the proposed model significantly outperforms state-of-the-art methods on both the SYSU-MM01 and RegDB datasets.
CMTR: Cross-modality Transformer for Visible-infrared Person Re-identification
Oct 18, 2021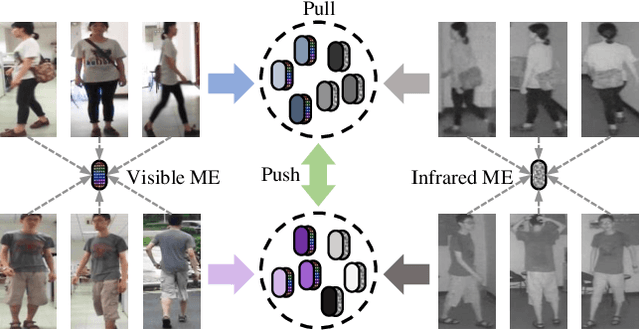
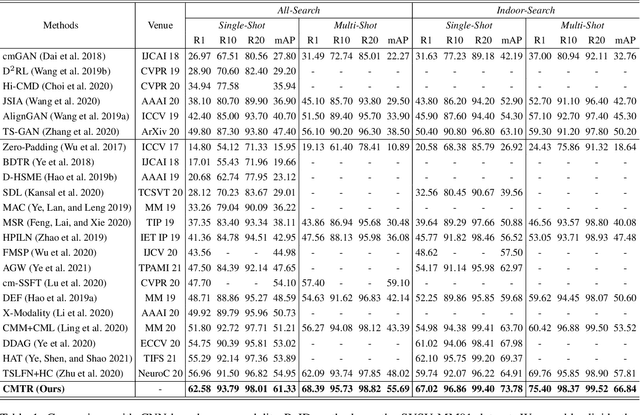
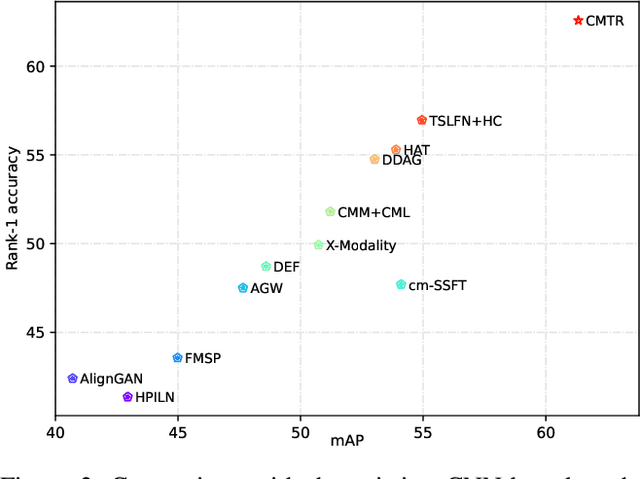
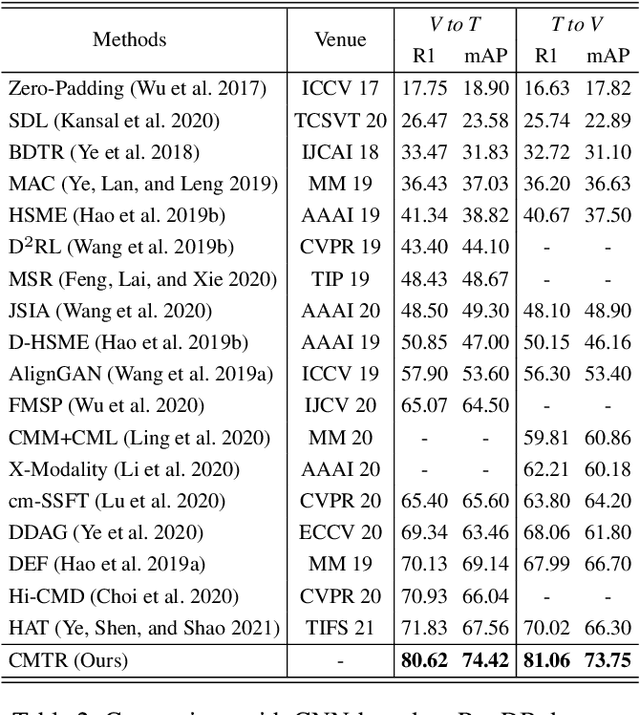
Visible-infrared cross-modality person re-identification is a challenging ReID task, which aims to retrieve and match the same identity's images between the heterogeneous visible and infrared modalities. Thus, the core of this task is to bridge the huge gap between these two modalities. The existing convolutional neural network-based methods mainly face the problem of insufficient perception of modalities' information, and can not learn good discriminative modality-invariant embeddings for identities, which limits their performance. To solve these problems, we propose a cross-modality transformer-based method (CMTR) for the visible-infrared person re-identification task, which can explicitly mine the information of each modality and generate better discriminative features based on it. Specifically, to capture modalities' characteristics, we design the novel modality embeddings, which are fused with token embeddings to encode modalities' information. Furthermore, to enhance representation of modality embeddings and adjust matching embeddings' distribution, we propose a modality-aware enhancement loss based on the learned modalities' information, reducing intra-class distance and enlarging inter-class distance. To our knowledge, this is the first work of applying transformer network to the cross-modality re-identification task. We implement extensive experiments on the public SYSU-MM01 and RegDB datasets, and our proposed CMTR model's performance significantly surpasses existing outstanding CNN-based methods.
Joint Graph Learning and Matching for Semantic Feature Correspondence
Sep 01, 2021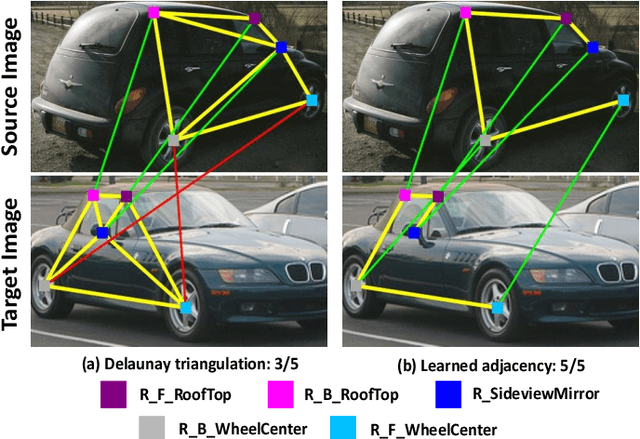

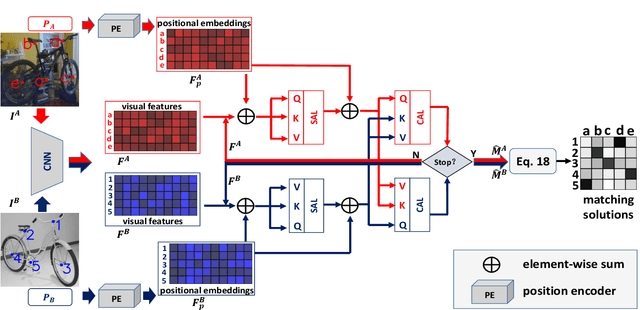

In recent years, powered by the learned discriminative representation via graph neural network (GNN) models, deep graph matching methods have made great progresses in the task of matching semantic features. However, these methods usually rely on heuristically generated graph patterns, which may introduce unreliable relationships to hurt the matching performance. In this paper, we propose a joint \emph{graph learning and matching} network, named GLAM, to explore reliable graph structures for boosting graph matching. GLAM adopts a pure attention-based framework for both graph learning and graph matching. Specifically, it employs two types of attention mechanisms, self-attention and cross-attention for the task. The self-attention discovers the relationships between features and to further update feature representations over the learnt structures; and the cross-attention computes cross-graph correlations between the two feature sets to be matched for feature reconstruction. Moreover, the final matching solution is directly derived from the output of the cross-attention layer, without employing a specific matching decision module. The proposed method is evaluated on three popular visual matching benchmarks (Pascal VOC, Willow Object and SPair-71k), and it outperforms previous state-of-the-art graph matching methods by significant margins on all benchmarks. Furthermore, the graph patterns learnt by our model are validated to be able to remarkably enhance previous deep graph matching methods by replacing their handcrafted graph structures with the learnt ones.
A Universal Model for Cross Modality Mapping by Relational Reasoning
Feb 26, 2021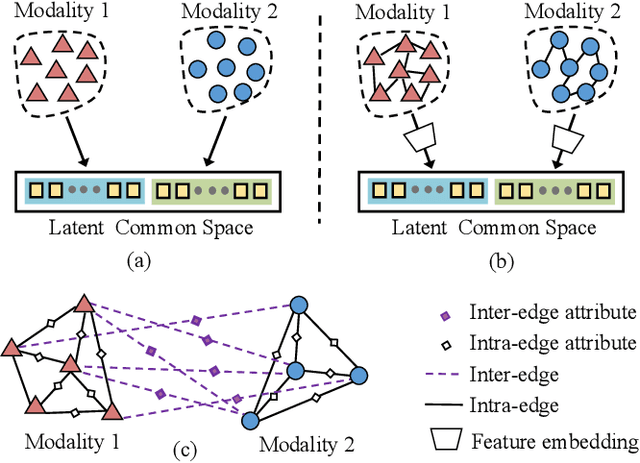
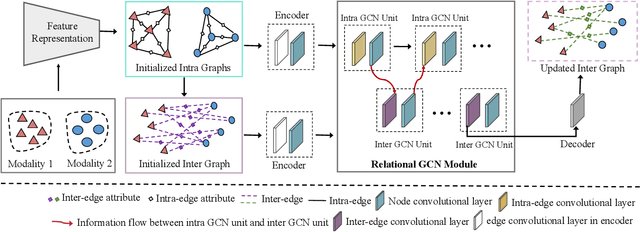
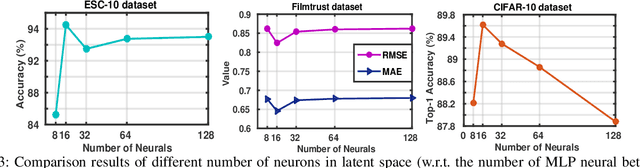
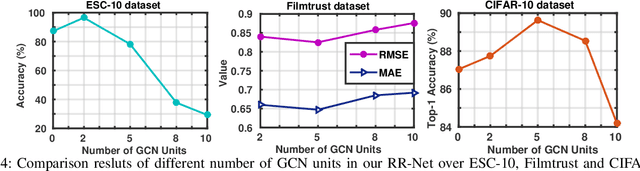
With the aim of matching a pair of instances from two different modalities, cross modality mapping has attracted growing attention in the computer vision community. Existing methods usually formulate the mapping function as the similarity measure between the pair of instance features, which are embedded to a common space. However, we observe that the relationships among the instances within a single modality (intra relations) and those between the pair of heterogeneous instances (inter relations) are insufficiently explored in previous approaches. Motivated by this, we redefine the mapping function with relational reasoning via graph modeling, and further propose a GCN-based Relational Reasoning Network (RR-Net) in which inter and intra relations are efficiently computed to universally resolve the cross modality mapping problem. Concretely, we first construct two kinds of graph, i.e., Intra Graph and Inter Graph, to respectively model intra relations and inter relations. Then RR-Net updates all the node features and edge features in an iterative manner for learning intra and inter relations simultaneously. Last, RR-Net outputs the probabilities over the edges which link a pair of heterogeneous instances to estimate the mapping results. Extensive experiments on three example tasks, i.e., image classification, social recommendation and sound recognition, clearly demonstrate the superiority and universality of our proposed model.
Attention Models for Point Clouds in Deep Learning: A Survey
Feb 22, 2021Recently, the advancement of 3D point clouds in deep learning has attracted intensive research in different application domains such as computer vision and robotic tasks. However, creating feature representation of robust, discriminative from unordered and irregular point clouds is challenging. In this paper, our ultimate goal is to provide a comprehensive overview of the point clouds feature representation which uses attention models. More than 75+ key contributions in the recent three years are summarized in this survey, including the 3D objective detection, 3D semantic segmentation, 3D pose estimation, point clouds completion etc. We provide a detailed characterization (1) the role of attention mechanisms, (2) the usability of attention models into different tasks, (3) the development trend of key technology.
Multi-intersection Traffic Optimisation: A Benchmark Dataset and a Strong Baseline
Jan 24, 2021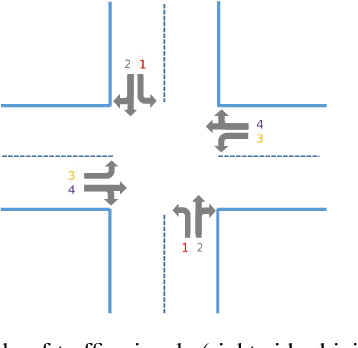
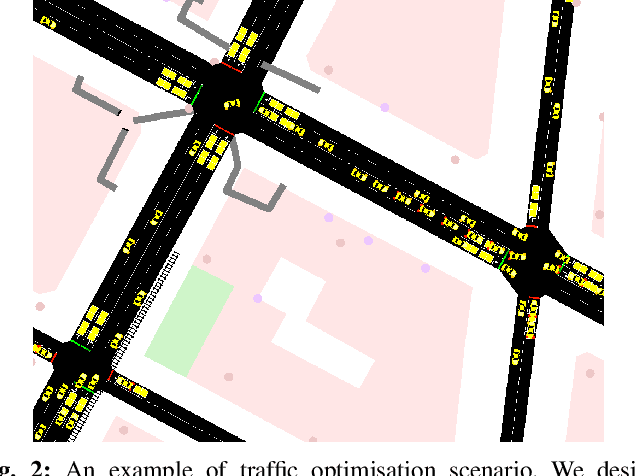
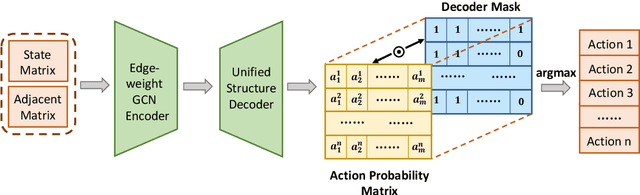
The control of traffic signals is fundamental and critical to alleviate traffic congestion in urban areas. However, it is challenging since traffic dynamics are complicated in real situations. Because of the high complexity of modelling the optimisation problem, experimental settings of current works are often inconsistent. Moreover, it is not trivial to control multiple intersections properly in real complex traffic scenarios due to its vast state and action space. Failing to take intersection topology relations into account also results in inferior traffic condition. To address these issues, in this work we carefully design our settings and propose new data including both synthetic and real traffic data in more complex scenarios. Additionally, we propose a novel and strong baseline model based on deep reinforcement learning with the encoder-decoder structure: an edge-weighted graph convolutional encoder to excavate multi-intersection relations; and a unified structure decoder to jointly model multiple junctions in a comprehensive manner, which significantly reduces the number of the model parameters. By doing so, the proposed model is able to effectively deal with multi-intersection traffic optimisation problems. Models have been trained and tested on both synthetic and real maps and traffic data with the Simulation of Urban Mobility (SUMO) simulator. Experimental results show that the proposed model surpasses existing methods in the literature.
Robust Watermarking Using Inverse Gradient Attention
Nov 21, 2020
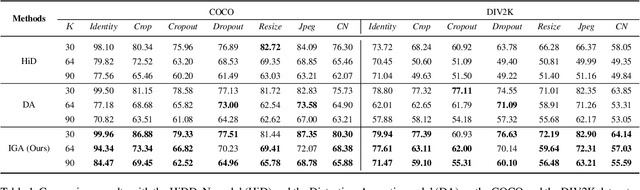
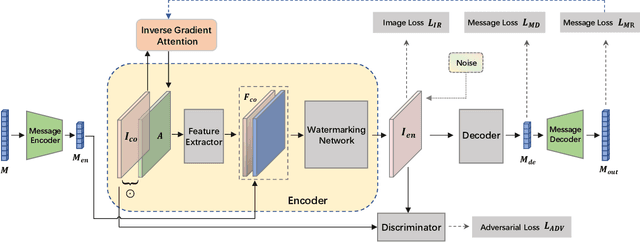
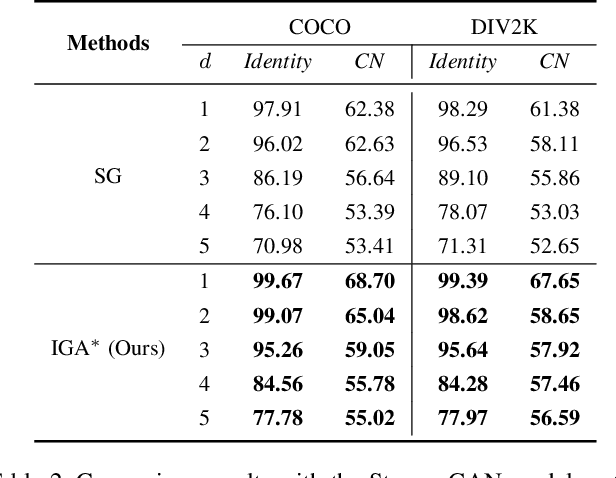
Watermarking is the procedure of encoding desired information into an image to resist potential noises while ensuring the embedded image has little perceptual perturbations from the original image. Recently, with the tremendous successes gained by deep neural networks in various fields, digital watermarking has attracted increasing number of attentions. The neglect of considering the pixel importance within the cover image of deep neural models will inevitably affect the model robustness for information hiding. Targeting at the problem, in this paper, we propose a novel deep watermarking scheme with Inverse Gradient Attention (IGA), combing the ideas of adversarial learning and attention mechanism to endow different importance to different pixels. With the proposed method, the model is able to spotlight pixels with more robustness for embedding data. Besides, from an orthogonal point of view, in order to increase the model embedding capacity, we propose a complementary message coding module. Empirically, extensive experiments show that the proposed model outperforms the state-of-the-art methods on two prevalent datasets under multiple settings.
EDCNN: Edge enhancement-based Densely Connected Network with Compound Loss for Low-Dose CT Denoising
Oct 30, 2020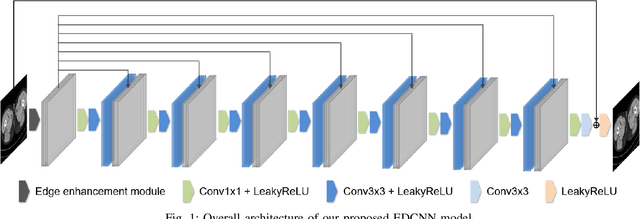
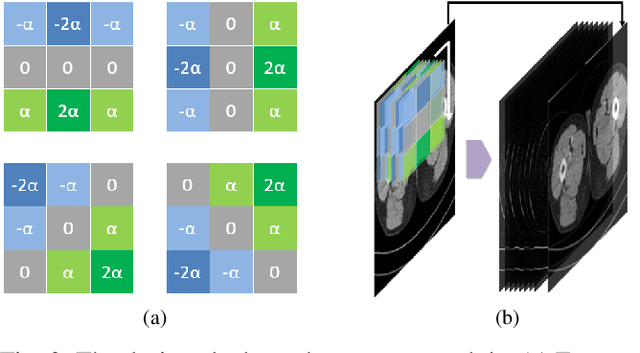
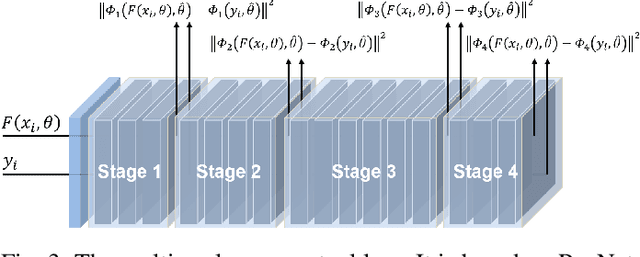
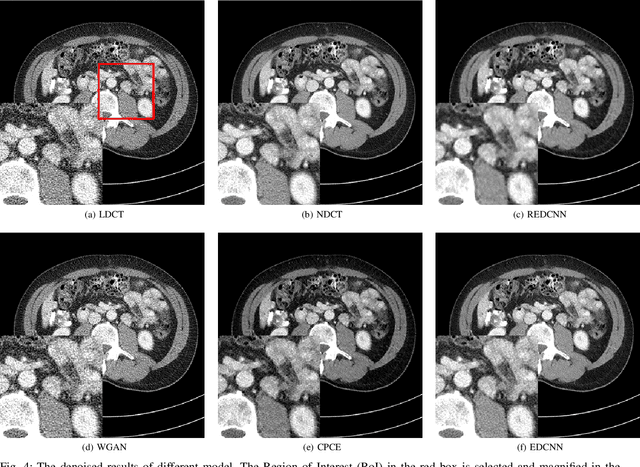
In the past few decades, to reduce the risk of X-ray in computed tomography (CT), low-dose CT image denoising has attracted extensive attention from researchers, which has become an important research issue in the field of medical images. In recent years, with the rapid development of deep learning technology, many algorithms have emerged to apply convolutional neural networks to this task, achieving promising results. However, there are still some problems such as low denoising efficiency, over-smoothed result, etc. In this paper, we propose the Edge enhancement based Densely connected Convolutional Neural Network (EDCNN). In our network, we design an edge enhancement module using the proposed novel trainable Sobel convolution. Based on this module, we construct a model with dense connections to fuse the extracted edge information and realize end-to-end image denoising. Besides, when training the model, we introduce a compound loss that combines MSE loss and multi-scales perceptual loss to solve the over-smoothed problem and attain a marked improvement in image quality after denoising. Compared with the existing low-dose CT image denoising algorithms, our proposed model has a better performance in preserving details and suppressing noise.
CelebA-Spoof: Large-Scale Face Anti-Spoofing Dataset with Rich Annotations
Aug 01, 2020
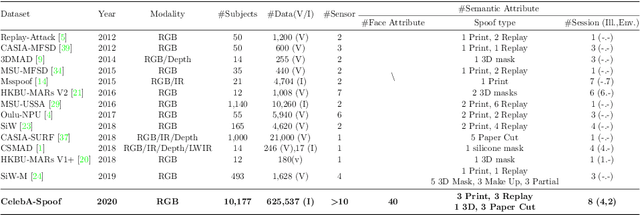

As facial interaction systems are prevalently deployed, security and reliability of these systems become a critical issue, with substantial research efforts devoted. Among them, face anti-spoofing emerges as an important area, whose objective is to identify whether a presented face is live or spoof. Though promising progress has been achieved, existing works still have difficulty in handling complex spoof attacks and generalizing to real-world scenarios. The main reason is that current face anti-spoofing datasets are limited in both quantity and diversity. To overcome these obstacles, we contribute a large-scale face anti-spoofing dataset, CelebA-Spoof, with the following appealing properties: 1) Quantity: CelebA-Spoof comprises of 625,537 pictures of 10,177 subjects, significantly larger than the existing datasets. 2) Diversity: The spoof images are captured from 8 scenes (2 environments * 4 illumination conditions) with more than 10 sensors. 3) Annotation Richness: CelebA-Spoof contains 10 spoof type annotations, as well as the 40 attribute annotations inherited from the original CelebA dataset. Equipped with CelebA-Spoof, we carefully benchmark existing methods in a unified multi-task framework, Auxiliary Information Embedding Network (AENet), and reveal several valuable observations.
Cross-layer Feature Pyramid Network for Salient Object Detection
Feb 25, 2020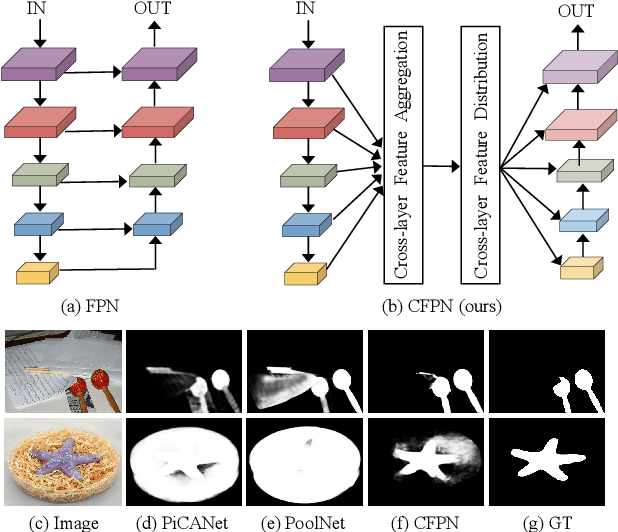
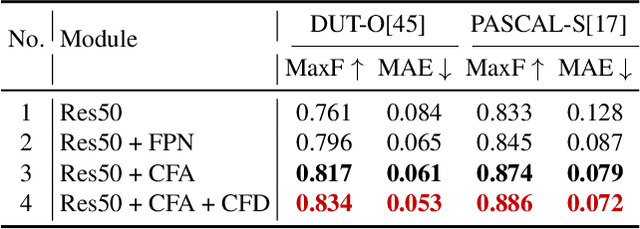
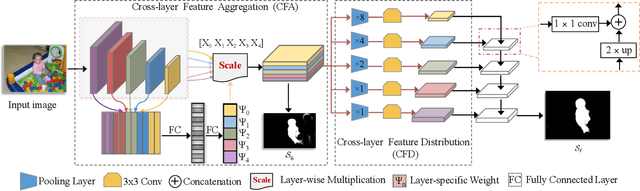
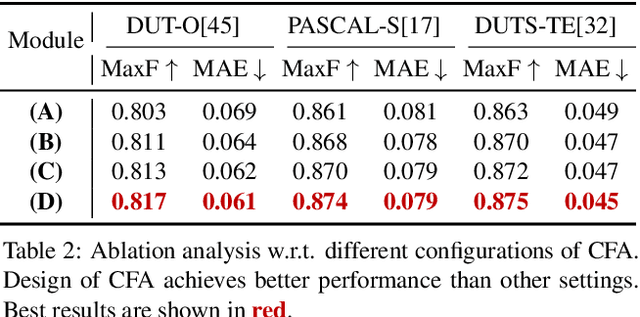
Feature pyramid network (FPN) based models, which fuse the semantics and salient details in a progressive manner, have been proven highly effective in salient object detection. However, it is observed that these models often generate saliency maps with incomplete object structures or unclear object boundaries, due to the \emph{indirect} information propagation among distant layers that makes such fusion structure less effective. In this work, we propose a novel Cross-layer Feature Pyramid Network (CFPN), in which direct cross-layer communication is enabled to improve the progressive fusion in salient object detection. Specifically, the proposed network first aggregates multi-scale features from different layers into feature maps that have access to both the high- and low-level information. Then, it distributes the aggregated features to all the involved layers to gain access to richer context. In this way, the distributed features per layer own both semantics and salient details from all other layers simultaneously, and suffer reduced loss of important information. Extensive experimental results over six widely used salient object detection benchmarks and with three popular backbones clearly demonstrate that CFPN can accurately locate fairly complete salient regions and effectively segment the object boundaries.