 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel What Matters: Modality-Balanced and Difficulty-Aware Multimodal Active Learning
Mar 26, 2026Multimodal learning integrates complementary information from different modalities such as image, text, and audio to improve model performance, but its success relies on large-scale labeled data, which is costly to obtain. Active learning (AL) mitigates this challenge by selectively annotating informative samples. In multimodal settings, many approaches implicitly assume that modality importance is stable across rounds and keep selection rules fixed at the fusion stage, which leaves them insensitive to the dynamic nature of multimodal learning, where the relative value of modalities and the difficulty of instances shift as training proceeds. To address this issue, we propose RL-MBA, a reinforcement-learning framework for modality-balanced, difficulty-aware multimodal active learning. RL-MBA models sample selection as a Markov Decision Process, where the policy adapts to modality contributions, uncertainty, and diversity, and the reward encourages accuracy gains and balance. Two key components drive this adaptability: (1) Adaptive Modality Contribution Balancing (AMCB), which dynamically adjusts modality weights via reinforcement feedback, and (2) Evidential Fusion for DifficultyAware Policy Adjustment (EFDA), which estimates sample difficulty via uncertainty-based evidential fusion to prioritize informative samples. Experiments on Food101, KineticsSound, and VGGSound demonstrate that RL-MBA consistently outperforms strong baselines, improving both classification accuracy and modality fairness under limited labeling budgets.
Bridging the Gap: Multi-Level Cross-Modality Joint Alignment for Visible-Infrared Person Re-Identification
Jul 17, 2023Visible-Infrared person Re-IDentification (VI-ReID) is a challenging cross-modality image retrieval task that aims to match pedestrians' images across visible and infrared cameras. To solve the modality gap, existing mainstream methods adopt a learning paradigm converting the image retrieval task into an image classification task with cross-entropy loss and auxiliary metric learning losses. These losses follow the strategy of adjusting the distribution of extracted embeddings to reduce the intra-class distance and increase the inter-class distance. However, such objectives do not precisely correspond to the final test setting of the retrieval task, resulting in a new gap at the optimization level. By rethinking these keys of VI-ReID, we propose a simple and effective method, the Multi-level Cross-modality Joint Alignment (MCJA), bridging both modality and objective-level gap. For the former, we design the Modality Alignment Augmentation, which consists of three novel strategies, the weighted grayscale, cross-channel cutmix, and spectrum jitter augmentation, effectively reducing modality discrepancy in the image space. For the latter, we introduce a new Cross-Modality Retrieval loss. It is the first work to constrain from the perspective of the ranking list, aligning with the goal of the testing stage. Moreover, based on the global feature only, our method exhibits good performance and can serve as a strong baseline method for the VI-ReID community.
Boundary Corrected Multi-scale Fusion Network for Real-time Semantic Segmentation
Mar 01, 2022

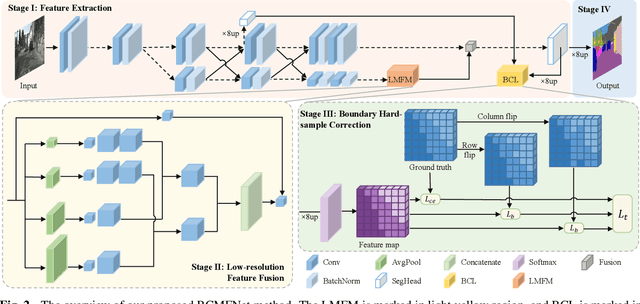
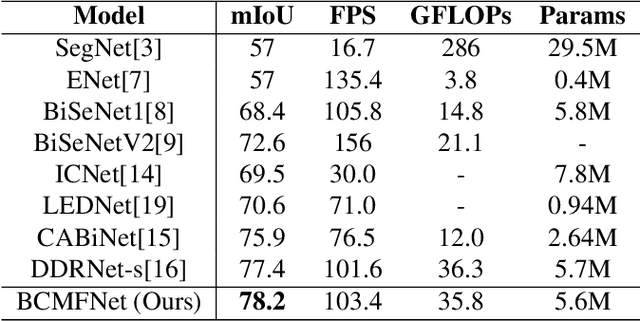
Image semantic segmentation aims at the pixel-level classification of images, which has requirements for both accuracy and speed in practical application. Existing semantic segmentation methods mainly rely on the high-resolution input to achieve high accuracy and do not meet the requirements of inference time. Although some methods focus on high-speed scene parsing with lightweight architectures, they can not fully mine semantic features under low computation with relatively low performance. To realize the real-time and high-precision segmentation, we propose a new method named Boundary Corrected Multi-scale Fusion Network, which uses the designed Low-resolution Multi-scale Fusion Module to extract semantic information. Moreover, to deal with boundary errors caused by low-resolution feature map fusion, we further design an additional Boundary Corrected Loss to constrain overly smooth features. Extensive experiments show that our method achieves a state-of-the-art balance of accuracy and speed for the real-time semantic segmentation.
Camera-aware Style Separation and Contrastive Learning for Unsupervised Person Re-identification
Dec 19, 2021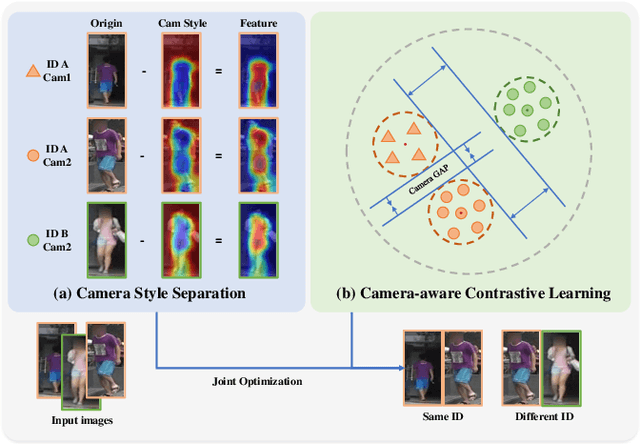
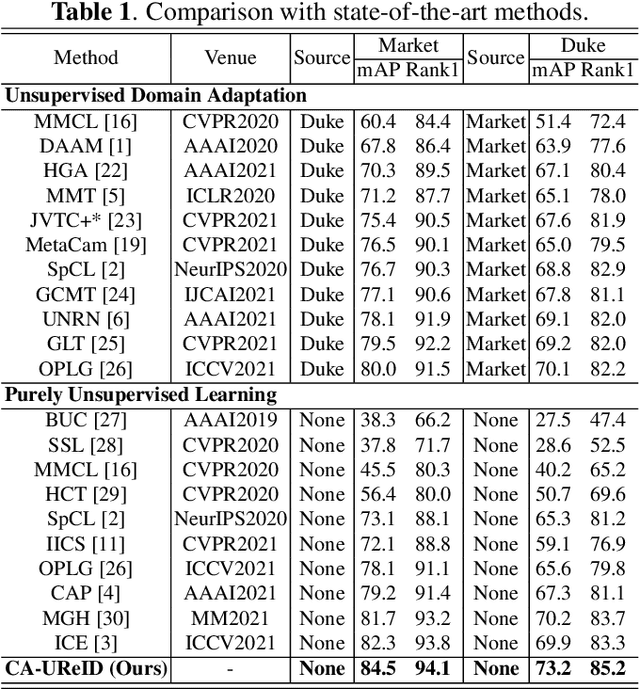
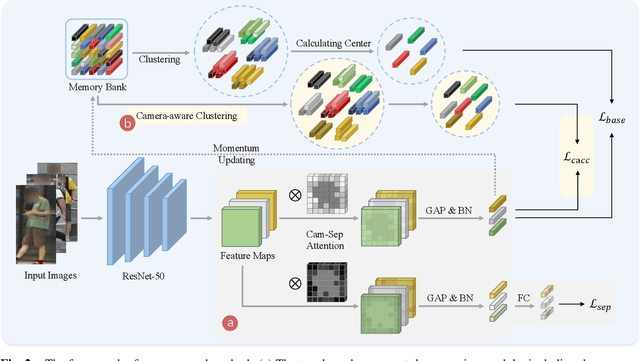
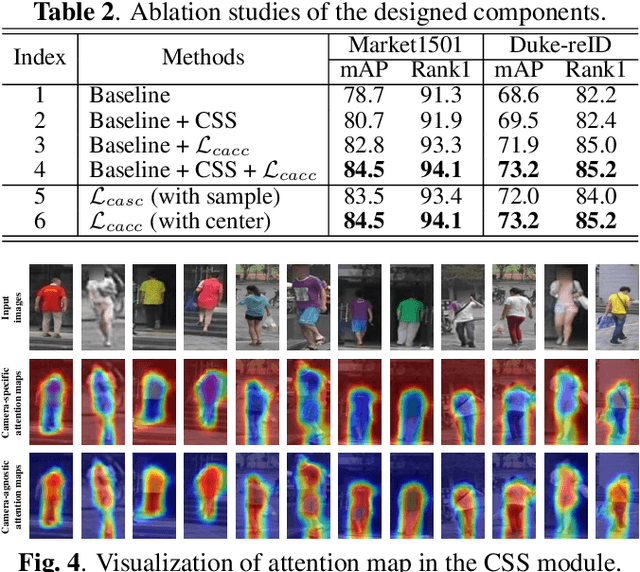
Unsupervised person re-identification (ReID) is a challenging task without data annotation to guide discriminative learning. Existing methods attempt to solve this problem by clustering extracted embeddings to generate pseudo labels. However, most methods ignore the intra-class gap caused by camera style variance, and some methods are relatively complex and indirect although they try to solve the negative impact of the camera style on feature distribution. To solve this problem, we propose a camera-aware style separation and contrastive learning method (CA-UReID), which directly separates camera styles in the feature space with the designed camera-aware attention module. It can explicitly divide the learnable feature into camera-specific and camera-agnostic parts, reducing the influence of different cameras. Moreover, to further narrow the gap across cameras, we design a camera-aware contrastive center loss to learn more discriminative embedding for each identity. Extensive experiments demonstrate the superiority of our method over the state-of-the-art methods on the unsupervised person ReID task.
MSO: Multi-Feature Space Joint Optimization Network for RGB-Infrared Person Re-Identification
Oct 21, 2021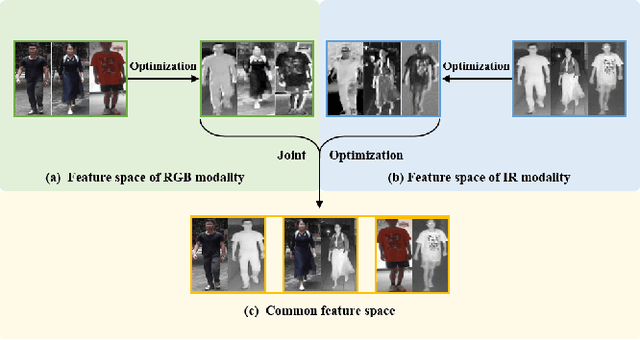
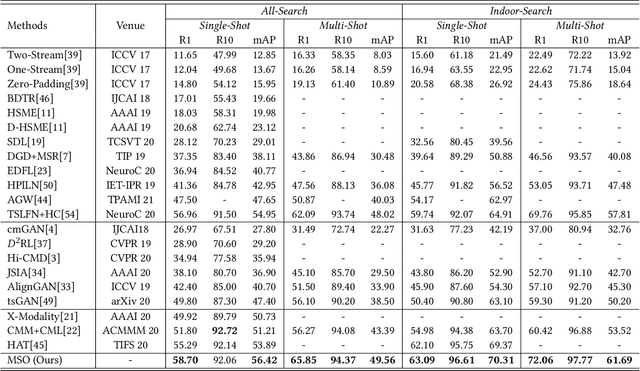
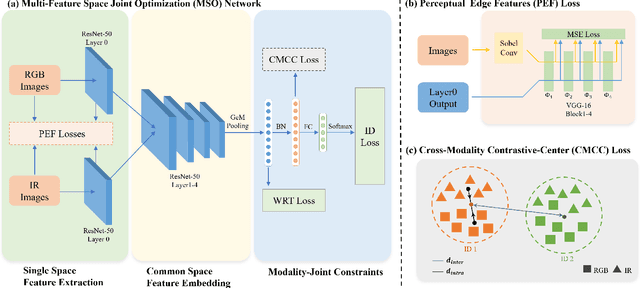
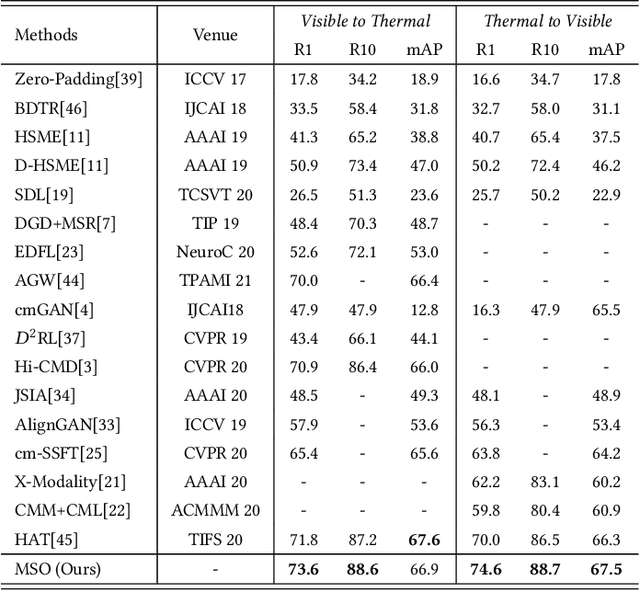
The RGB-infrared cross-modality person re-identification (ReID) task aims to recognize the images of the same identity between the visible modality and the infrared modality. Existing methods mainly use a two-stream architecture to eliminate the discrepancy between the two modalities in the final common feature space, which ignore the single space of each modality in the shallow layers. To solve it, in this paper, we present a novel multi-feature space joint optimization (MSO) network, which can learn modality-sharable features in both the single-modality space and the common space. Firstly, based on the observation that edge information is modality-invariant, we propose an edge features enhancement module to enhance the modality-sharable features in each single-modality space. Specifically, we design a perceptual edge features (PEF) loss after the edge fusion strategy analysis. According to our knowledge, this is the first work that proposes explicit optimization in the single-modality feature space on cross-modality ReID task. Moreover, to increase the difference between cross-modality distance and class distance, we introduce a novel cross-modality contrastive-center (CMCC) loss into the modality-joint constraints in the common feature space. The PEF loss and CMCC loss jointly optimize the model in an end-to-end manner, which markedly improves the network's performance. Extensive experiments demonstrate that the proposed model significantly outperforms state-of-the-art methods on both the SYSU-MM01 and RegDB datasets.
CMTR: Cross-modality Transformer for Visible-infrared Person Re-identification
Oct 18, 2021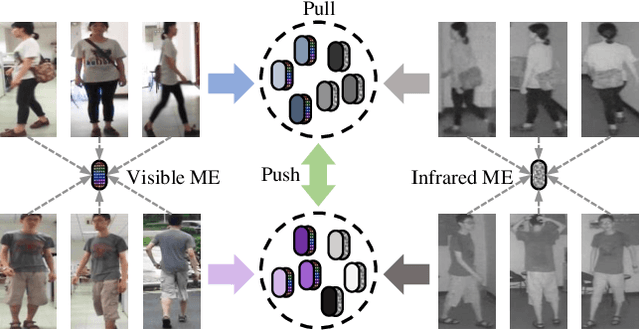
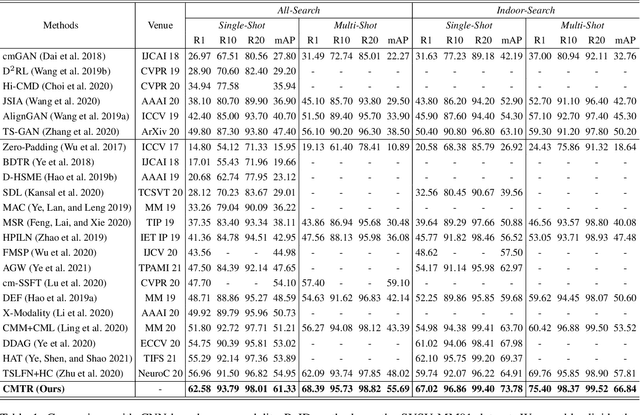
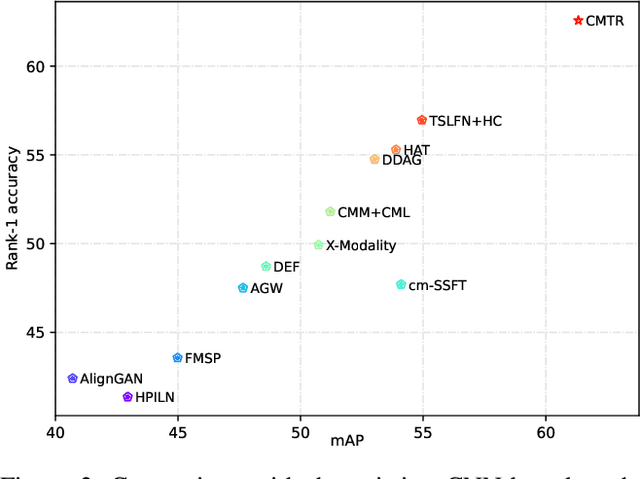
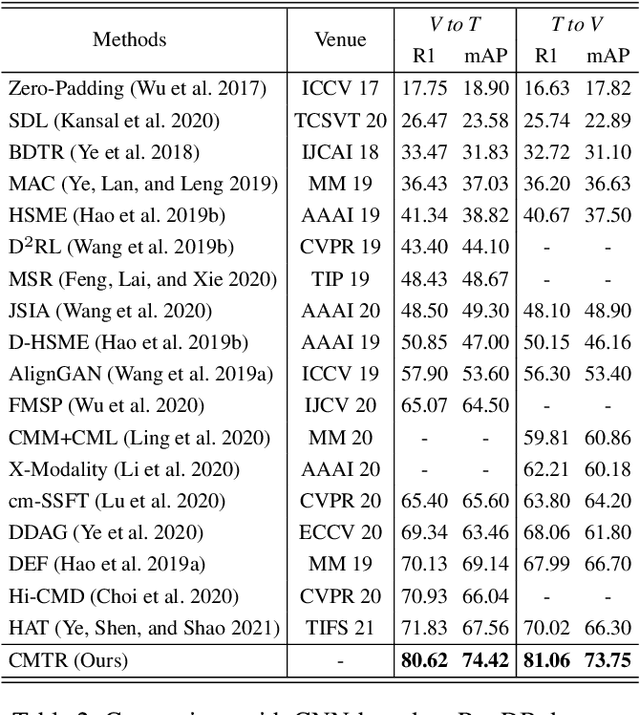
Visible-infrared cross-modality person re-identification is a challenging ReID task, which aims to retrieve and match the same identity's images between the heterogeneous visible and infrared modalities. Thus, the core of this task is to bridge the huge gap between these two modalities. The existing convolutional neural network-based methods mainly face the problem of insufficient perception of modalities' information, and can not learn good discriminative modality-invariant embeddings for identities, which limits their performance. To solve these problems, we propose a cross-modality transformer-based method (CMTR) for the visible-infrared person re-identification task, which can explicitly mine the information of each modality and generate better discriminative features based on it. Specifically, to capture modalities' characteristics, we design the novel modality embeddings, which are fused with token embeddings to encode modalities' information. Furthermore, to enhance representation of modality embeddings and adjust matching embeddings' distribution, we propose a modality-aware enhancement loss based on the learned modalities' information, reducing intra-class distance and enlarging inter-class distance. To our knowledge, this is the first work of applying transformer network to the cross-modality re-identification task. We implement extensive experiments on the public SYSU-MM01 and RegDB datasets, and our proposed CMTR model's performance significantly surpasses existing outstanding CNN-based methods.
EDCNN: Edge enhancement-based Densely Connected Network with Compound Loss for Low-Dose CT Denoising
Oct 30, 2020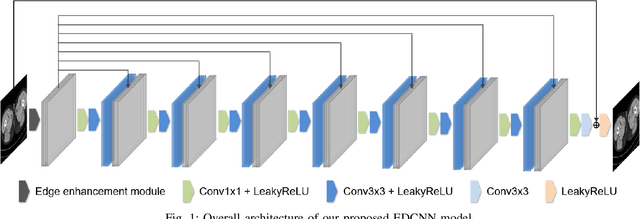
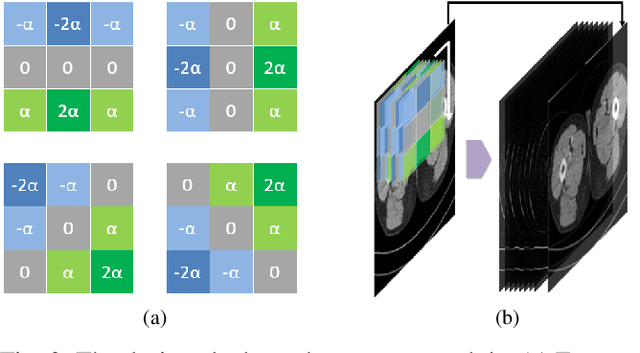
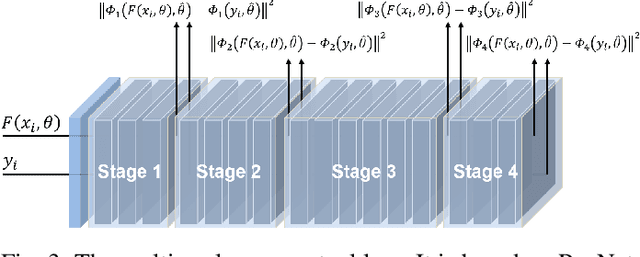
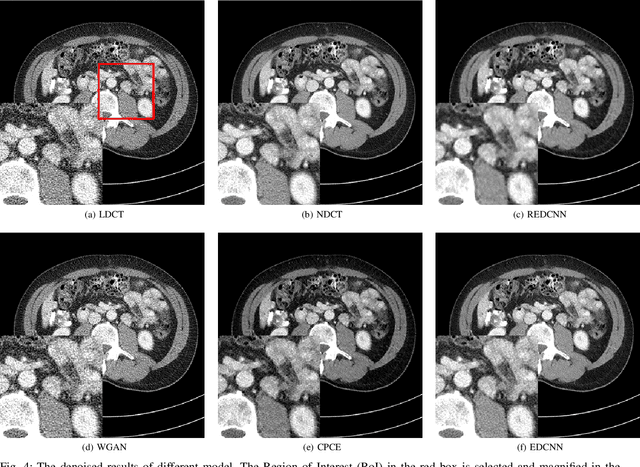
In the past few decades, to reduce the risk of X-ray in computed tomography (CT), low-dose CT image denoising has attracted extensive attention from researchers, which has become an important research issue in the field of medical images. In recent years, with the rapid development of deep learning technology, many algorithms have emerged to apply convolutional neural networks to this task, achieving promising results. However, there are still some problems such as low denoising efficiency, over-smoothed result, etc. In this paper, we propose the Edge enhancement based Densely connected Convolutional Neural Network (EDCNN). In our network, we design an edge enhancement module using the proposed novel trainable Sobel convolution. Based on this module, we construct a model with dense connections to fuse the extracted edge information and realize end-to-end image denoising. Besides, when training the model, we introduce a compound loss that combines MSE loss and multi-scales perceptual loss to solve the over-smoothed problem and attain a marked improvement in image quality after denoising. Compared with the existing low-dose CT image denoising algorithms, our proposed model has a better performance in preserving details and suppressing noise.