 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge6D Movable Antenna Enhanced Cell-free MIMO: Two-timescale Decentralized Beamforming and Antenna Movement Optimization
Jan 08, 2026This paper investigates a six-dimensional movable antenna (6DMA)-aided cell-free multi-user multiple-input multiple-output (MIMO) communication system. In this system, each distributed access point (AP) can flexibly adjust its array orientation and antenna positions to adapt to spatial channel variations and enhance communication performance. However, frequent antenna movements and centralized beamforming based on global instantaneous channel state information (CSI) sharing among APs entail extremely high signal processing delay and system overhead, which is difficult to be practically implemented in high-mobility scenarios with short channel coherence time. To address these practical implementation challenges and improve scalability, a two-timescale decentralized optimization framework is proposed in this paper to jointly design the beamformer, antenna positions, and array orientations. In the short timescale, each AP updates its receive beamformer based on local instantaneous CSI and global statistical CSI. In the long timescale, the central processing unit optimizes the antenna positions and array orientations at all APs based on global statistical CSI to maximize the ergodic sum rate of all users. The resulting optimization problem is non-convex and involves highly coupled variables, thus posing significant challenges for obtaining efficient solutions. To address this problem, a constrained stochastic successive convex approximation algorithm is developed. Numerical results demonstrate that the proposed 6DMA-aided cell-free system with decentralized beamforming significantly outperforms other antenna movement schemes with less flexibility and even achieves a performance comparable to that of the centralized beamforming benchmark.
Standardized Evaluation of Automatic Methods for Perivascular Spaces Segmentation in MRI -- MICCAI 2024 Challenge Results
Dec 20, 2025



Perivascular spaces (PVS), when abnormally enlarged and visible in magnetic resonance imaging (MRI) structural sequences, are important imaging markers of cerebral small vessel disease and potential indicators of neurodegenerative conditions. Despite their clinical significance, automatic enlarged PVS (EPVS) segmentation remains challenging due to their small size, variable morphology, similarity with other pathological features, and limited annotated datasets. This paper presents the EPVS Challenge organized at MICCAI 2024, which aims to advance the development of automated algorithms for EPVS segmentation across multi-site data. We provided a diverse dataset comprising 100 training, 50 validation, and 50 testing scans collected from multiple international sites (UK, Singapore, and China) with varying MRI protocols and demographics. All annotations followed the STRIVE protocol to ensure standardized ground truth and covered the full brain parenchyma. Seven teams completed the full challenge, implementing various deep learning approaches primarily based on U-Net architectures with innovations in multi-modal processing, ensemble strategies, and transformer-based components. Performance was evaluated using dice similarity coefficient, absolute volume difference, recall, and precision metrics. The winning method employed MedNeXt architecture with a dual 2D/3D strategy for handling varying slice thicknesses. The top solutions showed relatively good performance on test data from seen datasets, but significant degradation of performance was observed on the previously unseen Shanghai cohort, highlighting cross-site generalization challenges due to domain shift. This challenge establishes an important benchmark for EPVS segmentation methods and underscores the need for the continued development of robust algorithms that can generalize in diverse clinical settings.
A Conditional Generative Framework for Synthetic Data Augmentation in Segmenting Thin and Elongated Structures in Biological Images
Dec 11, 2025



Thin and elongated filamentous structures, such as microtubules and actin filaments, often play important roles in biological systems. Segmenting these filaments in biological images is a fundamental step for quantitative analysis. Recent advances in deep learning have significantly improved the performance of filament segmentation. However, there is a big challenge in acquiring high quality pixel-level annotated dataset for filamentous structures, as the dense distribution and geometric properties of filaments making manual annotation extremely laborious and time-consuming. To address the data shortage problem, we propose a conditional generative framework based on the Pix2Pix architecture to generate realistic filaments in microscopy images from binary masks. We also propose a filament-aware structural loss to improve the structure similarity when generating synthetic images. Our experiments have demonstrated the effectiveness of our approach and outperformed existing model trained without synthetic data.
Arithmetic-Mean $μ$P for Modern Architectures: A Unified Learning-Rate Scale for CNNs and ResNets
Oct 05, 2025Choosing an appropriate learning rate remains a key challenge in scaling depth of modern deep networks. The classical maximal update parameterization ($\mu$P) enforces a fixed per-layer update magnitude, which is well suited to homogeneous multilayer perceptrons (MLPs) but becomes ill-posed in heterogeneous architectures where residual accumulation and convolutions introduce imbalance across layers. We introduce Arithmetic-Mean $\mu$P (AM-$\mu$P), which constrains not each individual layer but the network-wide average one-step pre-activation second moment to a constant scale. Combined with a residual-aware He fan-in initialization - scaling residual-branch weights by the number of blocks ($\mathrm{Var}[W]=c/(K\cdot \mathrm{fan\text{-}in})$) - AM-$\mu$P yields width-robust depth laws that transfer consistently across depths. We prove that, for one- and two-dimensional convolutional networks, the maximal-update learning rate satisfies $\eta^\star(L)\propto L^{-3/2}$; with zero padding, boundary effects are constant-level as $N\gg k$. For standard residual networks with general conv+MLP blocks, we establish $\eta^\star(L)=\Theta(L^{-3/2})$, with $L$ the minimal depth. Empirical results across a range of depths confirm the $-3/2$ scaling law and enable zero-shot learning-rate transfer, providing a unified and practical LR principle for convolutional and deep residual networks without additional tuning overhead.
Pixel Motion Diffusion is What We Need for Robot Control
Sep 26, 2025We present DAWN (Diffusion is All We Need for robot control), a unified diffusion-based framework for language-conditioned robotic manipulation that bridges high-level motion intent and low-level robot action via structured pixel motion representation. In DAWN, both the high-level and low-level controllers are modeled as diffusion processes, yielding a fully trainable, end-to-end system with interpretable intermediate motion abstractions. DAWN achieves state-of-the-art results on the challenging CALVIN benchmark, demonstrating strong multi-task performance, and further validates its effectiveness on MetaWorld. Despite the substantial domain gap between simulation and reality and limited real-world data, we demonstrate reliable real-world transfer with only minimal finetuning, illustrating the practical viability of diffusion-based motion abstractions for robotic control. Our results show the effectiveness of combining diffusion modeling with motion-centric representations as a strong baseline for scalable and robust robot learning. Project page: https://nero1342.github.io/DAWN/
AimBot: A Simple Auxiliary Visual Cue to Enhance Spatial Awareness of Visuomotor Policies
Aug 11, 2025In this paper, we propose AimBot, a lightweight visual augmentation technique that provides explicit spatial cues to improve visuomotor policy learning in robotic manipulation. AimBot overlays shooting lines and scope reticles onto multi-view RGB images, offering auxiliary visual guidance that encodes the end-effector's state. The overlays are computed from depth images, camera extrinsics, and the current end-effector pose, explicitly conveying spatial relationships between the gripper and objects in the scene. AimBot incurs minimal computational overhead (less than 1 ms) and requires no changes to model architectures, as it simply replaces original RGB images with augmented counterparts. Despite its simplicity, our results show that AimBot consistently improves the performance of various visuomotor policies in both simulation and real-world settings, highlighting the benefits of spatially grounded visual feedback.
PET2Rep: Towards Vision-Language Model-Drived Automated Radiology Report Generation for Positron Emission Tomography
Aug 06, 2025Positron emission tomography (PET) is a cornerstone of modern oncologic and neurologic imaging, distinguished by its unique ability to illuminate dynamic metabolic processes that transcend the anatomical focus of traditional imaging technologies. Radiology reports are essential for clinical decision making, yet their manual creation is labor-intensive and time-consuming. Recent advancements of vision-language models (VLMs) have shown strong potential in medical applications, presenting a promising avenue for automating report generation. However, existing applications of VLMs in the medical domain have predominantly focused on structural imaging modalities, while the unique characteristics of molecular PET imaging have largely been overlooked. To bridge the gap, we introduce PET2Rep, a large-scale comprehensive benchmark for evaluation of general and medical VLMs for radiology report generation for PET images. PET2Rep stands out as the first dedicated dataset for PET report generation with metabolic information, uniquely capturing whole-body image-report pairs that cover dozens of organs to fill the critical gap in existing benchmarks and mirror real-world clinical comprehensiveness. In addition to widely recognized natural language generation metrics, we introduce a series of clinical efficiency metrics to evaluate the quality of radiotracer uptake pattern description in key organs in generated reports. We conduct a head-to-head comparison of 30 cutting-edge general-purpose and medical-specialized VLMs. The results show that the current state-of-the-art VLMs perform poorly on PET report generation task, falling considerably short of fulfilling practical needs. Moreover, we identify several key insufficiency that need to be addressed to advance the development in medical applications.
OpenDCVCs: A PyTorch Open Source Implementation and Performance Evaluation of the DCVC series Video Codecs
Aug 06, 2025We present OpenDCVCs, an open-source PyTorch implementation designed to advance reproducible research in learned video compression. OpenDCVCs provides unified and training-ready implementations of four representative Deep Contextual Video Compression (DCVC) models--DCVC, DCVC with Temporal Context Modeling (DCVC-TCM), DCVC with Hybrid Entropy Modeling (DCVC-HEM), and DCVC with Diverse Contexts (DCVC-DC). While the DCVC series achieves substantial bitrate reductions over both classical codecs and advanced learned models, previous public code releases have been limited to evaluation codes, presenting significant barriers to reproducibility, benchmarking, and further development. OpenDCVCs bridges this gap by offering a comprehensive, self-contained framework that supports both end-to-end training and evaluation for all included algorithms. The implementation includes detailed documentation, evaluation protocols, and extensive benchmarking results across diverse datasets, providing a transparent and consistent foundation for comparison and extension. All code and experimental tools are publicly available at https://gitlab.com/viper-purdue/opendcvcs, empowering the community to accelerate research and foster collaboration.
Hierarchical Rectified Flow Matching with Mini-Batch Couplings
Jul 17, 2025Flow matching has emerged as a compelling generative modeling approach that is widely used across domains. To generate data via a flow matching model, an ordinary differential equation (ODE) is numerically solved via forward integration of the modeled velocity field. To better capture the multi-modality that is inherent in typical velocity fields, hierarchical flow matching was recently introduced. It uses a hierarchy of ODEs that are numerically integrated when generating data. This hierarchy of ODEs captures the multi-modal velocity distribution just like vanilla flow matching is capable of modeling a multi-modal data distribution. While this hierarchy enables to model multi-modal velocity distributions, the complexity of the modeled distribution remains identical across levels of the hierarchy. In this paper, we study how to gradually adjust the complexity of the distributions across different levels of the hierarchy via mini-batch couplings. We show the benefits of mini-batch couplings in hierarchical rectified flow matching via compelling results on synthetic and imaging data. Code is available at https://riccizz.github.io/HRF_coupling.
CriticLean: Critic-Guided Reinforcement Learning for Mathematical Formalization
Jul 08, 2025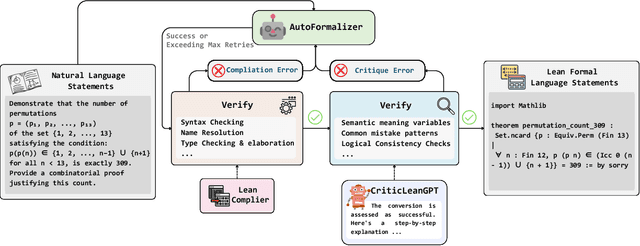

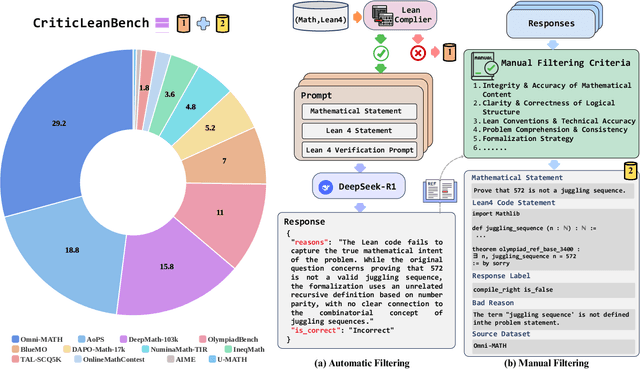
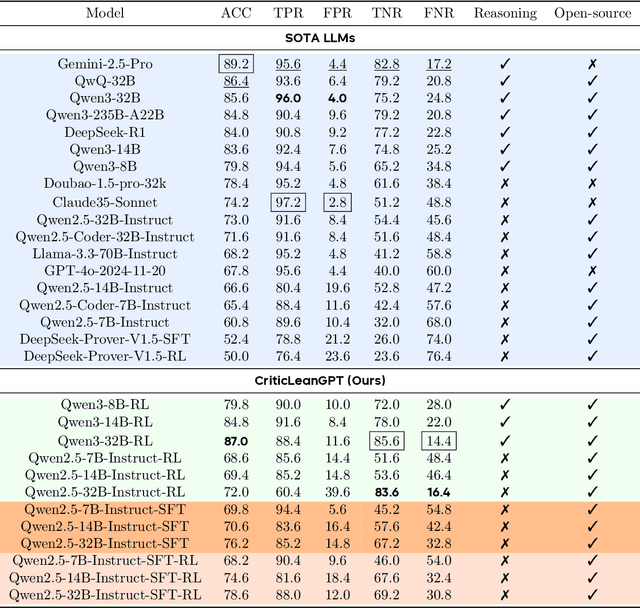
Translating natural language mathematical statements into formal, executable code is a fundamental challenge in automated theorem proving. While prior work has focused on generation and compilation success, little attention has been paid to the critic phase-the evaluation of whether generated formalizations truly capture the semantic intent of the original problem. In this paper, we introduce CriticLean, a novel critic-guided reinforcement learning framework that elevates the role of the critic from a passive validator to an active learning component. Specifically, first, we propose the CriticLeanGPT, trained via supervised fine-tuning and reinforcement learning, to rigorously assess the semantic fidelity of Lean 4 formalizations. Then, we introduce CriticLeanBench, a benchmark designed to measure models' ability to distinguish semantically correct from incorrect formalizations, and demonstrate that our trained CriticLeanGPT models can significantly outperform strong open- and closed-source baselines. Building on the CriticLean framework, we construct FineLeanCorpus, a dataset comprising over 285K problems that exhibits rich domain diversity, broad difficulty coverage, and high correctness based on human evaluation. Overall, our findings highlight that optimizing the critic phase is essential for producing reliable formalizations, and we hope our CriticLean will provide valuable insights for future advances in formal mathematical reasoning.