 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Bellman: High-Order Generator Regression for Continuous-Time Policy Evaluation
Apr 21, 2026We study finite-horizon continuous-time policy evaluation from discrete closed-loop trajectories under time-inhomogeneous dynamics. The target value surface solves a backward parabolic equation, but the Bellman baseline obtained from one-step recursion is only first-order in the grid width. We estimate the time-dependent generator from multi-step transitions using moment-matching coefficients that cancel lower-order truncation terms, and combine the resulting surrogate with backward regression. The main theory gives an end-to-end decomposition into generator misspecification, projection error, pooling bias, finite-sample error, and start-up error, together with a decision-frequency regime map explaining when higher-order gains should be visible. Across calibration studies, four-scale benchmarks, feature and start-up ablations, and gain-mismatch stress tests, the second-order estimator consistently improves on the Bellman baseline and remains stable in the regime where the theory predicts visible gains. These results position high-order generator regression as an interpretable continuous-time policy-evaluation method with a clear operating region.
Hyperparameter Transfer Laws for Non-Recurrent Multi-Path Neural Networks
Feb 07, 2026Deeper modern architectures are costly to train, making hyperparameter transfer preferable to expensive repeated tuning. Maximal Update Parametrization ($μ$P) helps explain why many hyperparameters transfer across width. Yet depth scaling is less understood for modern architectures, whose computation graphs contain multiple parallel paths and residual aggregation. To unify various non-recurrent multi-path neural networks such as CNNs, ResNets, and Transformers, we introduce a graph-based notion of effective depth. Under stabilizing initializations and a maximal-update criterion, we show that the optimal learning rate decays with effective depth following a universal -3/2 power law. Here, the maximal-update criterion maximizes the typical one-step representation change at initialization without causing instability, and effective depth is the minimal path length from input to output, counting layers and residual additions. Experiments across diverse architectures confirm the predicted slope and enable reliable zero-shot transfer of learning rates across depths and widths, turning depth scaling into a predictable hyperparameter-transfer problem.
Arithmetic-Mean $μ$P for Modern Architectures: A Unified Learning-Rate Scale for CNNs and ResNets
Oct 05, 2025Choosing an appropriate learning rate remains a key challenge in scaling depth of modern deep networks. The classical maximal update parameterization ($\mu$P) enforces a fixed per-layer update magnitude, which is well suited to homogeneous multilayer perceptrons (MLPs) but becomes ill-posed in heterogeneous architectures where residual accumulation and convolutions introduce imbalance across layers. We introduce Arithmetic-Mean $\mu$P (AM-$\mu$P), which constrains not each individual layer but the network-wide average one-step pre-activation second moment to a constant scale. Combined with a residual-aware He fan-in initialization - scaling residual-branch weights by the number of blocks ($\mathrm{Var}[W]=c/(K\cdot \mathrm{fan\text{-}in})$) - AM-$\mu$P yields width-robust depth laws that transfer consistently across depths. We prove that, for one- and two-dimensional convolutional networks, the maximal-update learning rate satisfies $\eta^\star(L)\propto L^{-3/2}$; with zero padding, boundary effects are constant-level as $N\gg k$. For standard residual networks with general conv+MLP blocks, we establish $\eta^\star(L)=\Theta(L^{-3/2})$, with $L$ the minimal depth. Empirical results across a range of depths confirm the $-3/2$ scaling law and enable zero-shot learning-rate transfer, providing a unified and practical LR principle for convolutional and deep residual networks without additional tuning overhead.
Combined CNN Transformer Encoder for Enhanced Fine-grained Human Action Recognition
Aug 03, 2022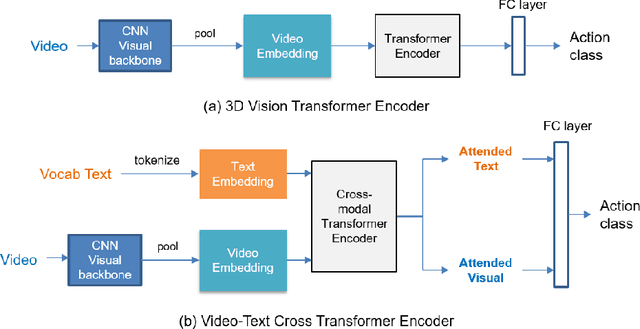

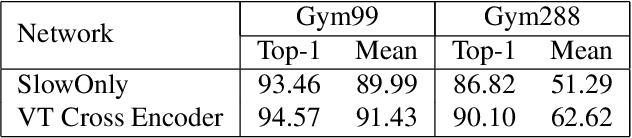
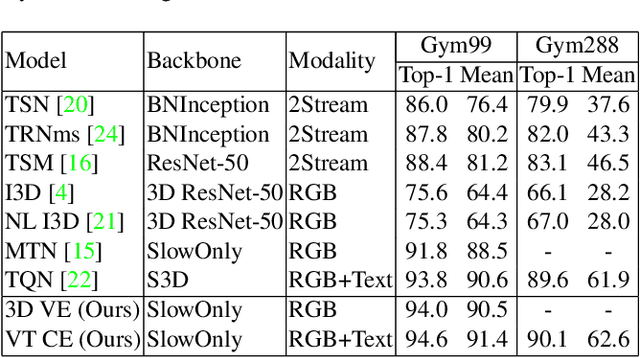
Fine-grained action recognition is a challenging task in computer vision. As fine-grained datasets have small inter-class variations in spatial and temporal space, fine-grained action recognition model requires good temporal reasoning and discrimination of attribute action semantics. Leveraging on CNN's ability in capturing high level spatial-temporal feature representations and Transformer's modeling efficiency in capturing latent semantics and global dependencies, we investigate two frameworks that combine CNN vision backbone and Transformer Encoder to enhance fine-grained action recognition: 1) a vision-based encoder to learn latent temporal semantics, and 2) a multi-modal video-text cross encoder to exploit additional text input and learn cross association between visual and text semantics. Our experimental results show that both our Transformer encoder frameworks effectively learn latent temporal semantics and cross-modality association, with improved recognition performance over CNN vision model. We achieve new state-of-the-art performance on the FineGym benchmark dataset for both proposed architectures.
Joint Learning On The Hierarchy Representation for Fine-Grained Human Action Recognition
Oct 12, 2021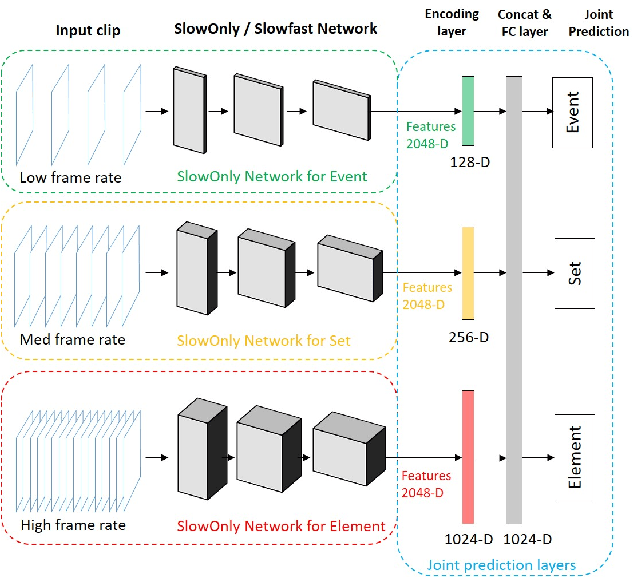
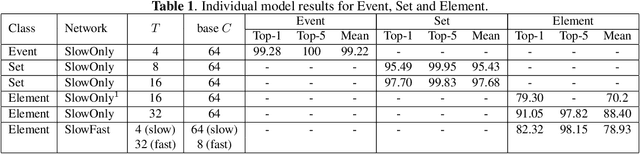

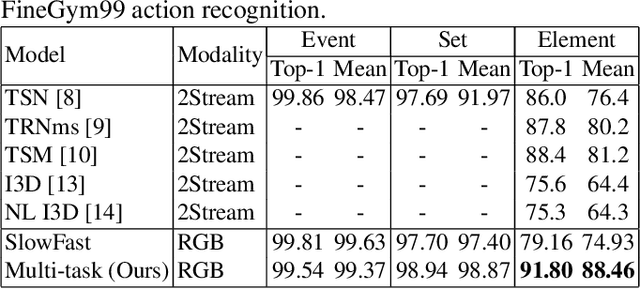
Fine-grained human action recognition is a core research topic in computer vision. Inspired by the recently proposed hierarchy representation of fine-grained actions in FineGym and SlowFast network for action recognition, we propose a novel multi-task network which exploits the FineGym hierarchy representation to achieve effective joint learning and prediction for fine-grained human action recognition. The multi-task network consists of three pathways of SlowOnly networks with gradually increased frame rates for events, sets and elements of fine-grained actions, followed by our proposed integration layers for joint learning and prediction. It is a two-stage approach, where it first learns deep feature representation at each hierarchical level, and is followed by feature encoding and fusion for multi-task learning. Our empirical results on the FineGym dataset achieve a new state-of-the-art performance, with 91.80% Top-1 accuracy and 88.46% mean accuracy for element actions, which are 3.40% and 7.26% higher than the previous best results.
* Camera ready for IEEE ICIP 2021