 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Value Alignment in Large Language Models through Neuron-Level Editing
Feb 07, 2026Aligning large language models (LLMs) with human values has become increasingly important as their influence on human behavior and decision-making expands. However, existing steering-based alignment methods suffer from limited controllability: steering a target value often unintentionally activates other, non-target values. To characterize this limitation, we introduce value leakage, a diagnostic notion that captures the unintended activation of non-target values during value steering, along with a normalized leakage metric grounded in Schwartz's value theory. In light of this analysis, we propose NeVA, a neuron-level editing framework for controllable value alignment in LLMs. NeVA identifies sparse, value-relevant neurons and performs inference-time activation editing, enabling fine-grained control without parameter updates or retraining. Experiments show that NeVA achieves stronger target value alignment while incurring smaller performance degradation on general capability. Moreover, NeVA significantly reduces the average leakage, with residual effects largely confined to semantically related value classes. Overall, NeVA offers a more controllable and interpretable mechanism for value alignment.
CodeCircuit: Toward Inferring LLM-Generated Code Correctness via Attribution Graphs
Feb 06, 2026Current paradigms for code verification rely heavily on external mechanisms-such as execution-based unit tests or auxiliary LLM judges-which are often labor-intensive or limited by the judging model's own capabilities. This raises a fundamental, yet unexplored question: Can an LLM's functional correctness be assessed purely from its internal computational structure? Our primary objective is to investigate whether the model's neural dynamics encode internally decodable signals that are predictive of logical validity during code generation. Inspired by mechanistic interpretability, we propose to treat code verification as a mechanistic diagnostic task, mapping the model's explicit algorithmic trajectory into line-level attribution graphs. By decomposing complex residual flows, we aim to identify the structural signatures that distinguish sound reasoning from logical failure within the model's internal circuits. Analysis across Python, C++, and Java confirms that intrinsic correctness signals are robust across diverse syntaxes. Topological features from these internal graphs predict correctness more reliably than surface heuristics and enable targeted causal interventions to fix erroneous logic. These findings establish internal introspection as a decodable property for verifying generated code. Our code is at https:// github.com/bruno686/CodeCircuit.
Beyond Max Tokens: Stealthy Resource Amplification via Tool Calling Chains in LLM Agents
Jan 16, 2026The agent-tool communication loop is a critical attack surface in modern Large Language Model (LLM) agents. Existing Denial-of-Service (DoS) attacks, primarily triggered via user prompts or injected retrieval-augmented generation (RAG) context, are ineffective for this new paradigm. They are fundamentally single-turn and often lack a task-oriented approach, making them conspicuous in goal-oriented workflows and unable to exploit the compounding costs of multi-turn agent-tool interactions. We introduce a stealthy, multi-turn economic DoS attack that operates at the tool layer under the guise of a correctly completed task. Our method adjusts text-visible fields and a template-governed return policy in a benign, Model Context Protocol (MCP)-compatible tool server, optimizing these edits with a Monte Carlo Tree Search (MCTS) optimizer. These adjustments leave function signatures unchanged and preserve the final payload, steering the agent into prolonged, verbose tool-calling sequences using text-only notices. This compounds costs across turns, escaping single-turn caps while keeping the final answer correct to evade validation. Across six LLMs on the ToolBench and BFCL benchmarks, our attack expands tasks into trajectories exceeding 60,000 tokens, inflates costs by up to 658x, and raises energy by 100-560x. It drives GPU KV cache occupancy from <1% to 35-74% and cuts co-running throughput by approximately 50%. Because the server remains protocol-compatible and task outcomes are correct, conventional checks fail. These results elevate the agent-tool interface to a first-class security frontier, demanding a paradigm shift from validating final answers to monitoring the economic and computational cost of the entire agentic process.
EchoFoley: Event-Centric Hierarchical Control for Video Grounded Creative Sound Generation
Dec 31, 2025Sound effects build an essential layer of multimodal storytelling, shaping the emotional atmosphere and the narrative semantics of videos. Despite recent advancement in video-text-to-audio (VT2A), the current formulation faces three key limitations: First, an imbalance between visual and textual conditioning that leads to visual dominance; Second, the absence of a concrete definition for fine-grained controllable generation; Third, weak instruction understanding and following, as existing datasets rely on brief categorical tags. To address these limitations, we introduce EchoFoley, a new task designed for video-grounded sound generation with both event level local control and hierarchical semantic control. Our symbolic representation for sounding events specifies when, what, and how each sound is produced within a video or instruction, enabling fine-grained controls like sound generation, insertion, and editing. To support this task, we construct EchoFoley-6k, a large-scale, expert-curated benchmark containing over 6,000 video-instruction-annotation triplets. Building upon this foundation, we propose EchoVidia a sounding-event-centric agentic generation framework with slow-fast thinking strategy. Experiments show that EchoVidia surpasses recent VT2A models by 40.7% in controllability and 12.5% in perceptual quality.
VisPlay: Self-Evolving Vision-Language Models from Images
Nov 19, 2025Reinforcement learning (RL) provides a principled framework for improving Vision-Language Models (VLMs) on complex reasoning tasks. However, existing RL approaches often rely on human-annotated labels or task-specific heuristics to define verifiable rewards, both of which are costly and difficult to scale. We introduce VisPlay, a self-evolving RL framework that enables VLMs to autonomously improve their reasoning abilities using large amounts of unlabeled image data. Starting from a single base VLM, VisPlay assigns the model into two interacting roles: an Image-Conditioned Questioner that formulates challenging yet answerable visual questions, and a Multimodal Reasoner that generates silver responses. These roles are jointly trained with Group Relative Policy Optimization (GRPO), which incorporates diversity and difficulty rewards to balance the complexity of generated questions with the quality of the silver answers. VisPlay scales efficiently across two model families. When trained on Qwen2.5-VL and MiMo-VL, VisPlay achieves consistent improvements in visual reasoning, compositional generalization, and hallucination reduction across eight benchmarks, including MM-Vet and MMMU, demonstrating a scalable path toward self-evolving multimodal intelligence. The project page is available at https://bruno686.github.io/VisPlay/
Optimizing NeRF-based SLAM with Trajectory Smoothness Constraints
Oct 11, 2024



The joint optimization of Neural Radiance Fields (NeRF) and camera trajectories has been widely applied in SLAM tasks due to its superior dense mapping quality and consistency. NeRF-based SLAM learns camera poses using constraints by implicit map representation. A widely observed phenomenon that results from the constraints of this form is jerky and physically unrealistic estimated camera motion, which in turn affects the map quality. To address this deficiency of current NeRF-based SLAM, we propose in this paper TS-SLAM (TS for Trajectory Smoothness). It introduces smoothness constraints on camera trajectories by representing them with uniform cubic B-splines with continuous acceleration that guarantees smooth camera motion. Benefiting from the differentiability and local control properties of B-splines, TS-SLAM can incrementally learn the control points end-to-end using a sliding window paradigm. Additionally, we regularize camera trajectories by exploiting the dynamics prior to further smooth trajectories. Experimental results demonstrate that TS-SLAM achieves superior trajectory accuracy and improves mapping quality versus NeRF-based SLAM that does not employ the above smoothness constraints.
PISR: Polarimetric Neural Implicit Surface Reconstruction for Textureless and Specular Objects
Sep 22, 2024



Neural implicit surface reconstruction has achieved remarkable progress recently. Despite resorting to complex radiance modeling, state-of-the-art methods still struggle with textureless and specular surfaces. Different from RGB images, polarization images can provide direct constraints on the azimuth angles of the surface normals. In this paper, we present PISR, a novel method that utilizes a geometrically accurate polarimetric loss to refine shape independently of appearance. In addition, PISR smooths surface normals in image space to eliminate severe shape distortions and leverages the hash-grid-based neural signed distance function to accelerate the reconstruction. Experimental results demonstrate that PISR achieves higher accuracy and robustness, with an L1 Chamfer distance of 0.5 mm and an F-score of 99.5% at 1 mm, while converging 4~30 times faster than previous polarimetric surface reconstruction methods.
Dataset Bias Mitigation in Multiple-Choice Visual Question Answering and Beyond
Oct 31, 2023Vision-language (VL) understanding tasks evaluate models' comprehension of complex visual scenes through multiple-choice questions. However, we have identified two dataset biases that models can exploit as shortcuts to resolve various VL tasks correctly without proper understanding. The first type of dataset bias is \emph{Unbalanced Matching} bias, where the correct answer overlaps the question and image more than the incorrect answers. The second type of dataset bias is \emph{Distractor Similarity} bias, where incorrect answers are overly dissimilar to the correct answer but significantly similar to other incorrect answers within the same sample. To address these dataset biases, we first propose Adversarial Data Synthesis (ADS) to generate synthetic training and debiased evaluation data. We then introduce Intra-sample Counterfactual Training (ICT) to assist models in utilizing the synthesized training data, particularly the counterfactual data, via focusing on intra-sample differentiation. Extensive experiments demonstrate the effectiveness of ADS and ICT in consistently improving model performance across different benchmarks, even in domain-shifted scenarios.
* EMNLP 2023
Understanding ME? Multimodal Evaluation for Fine-grained Visual Commonsense
Nov 10, 2022



Visual commonsense understanding requires Vision Language (VL) models to not only understand image and text but also cross-reference in-between to fully integrate and achieve comprehension of the visual scene described. Recently, various approaches have been developed and have achieved high performance on visual commonsense benchmarks. However, it is unclear whether the models really understand the visual scene and underlying commonsense knowledge due to limited evaluation data resources. To provide an in-depth analysis, we present a Multimodal Evaluation (ME) pipeline to automatically generate question-answer pairs to test models' understanding of the visual scene, text, and related knowledge. We then take a step further to show that training with the ME data boosts the model's performance in standard VCR evaluation. Lastly, our in-depth analysis and comparison reveal interesting findings: (1) semantically low-level information can assist the learning of high-level information but not the opposite; (2) visual information is generally under utilization compared with text.
Query Adaptive Few-Shot Object Detection with Heterogeneous Graph Convolutional Networks
Dec 17, 2021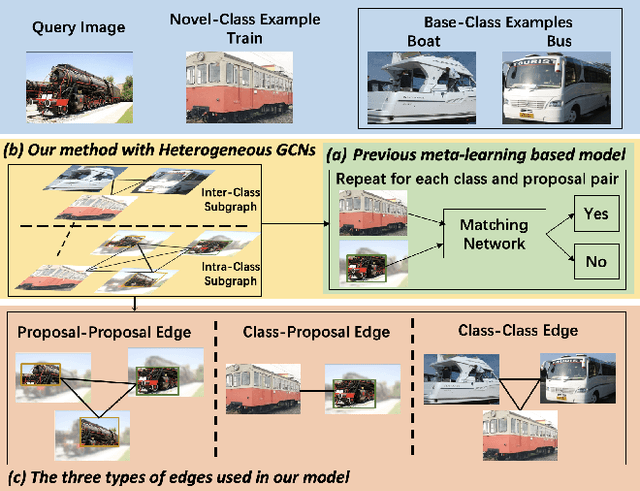
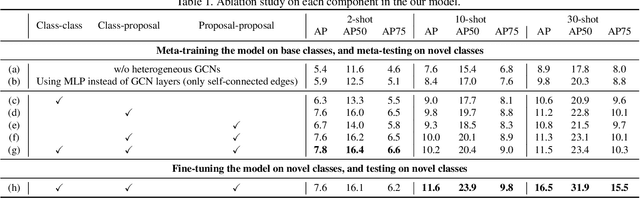
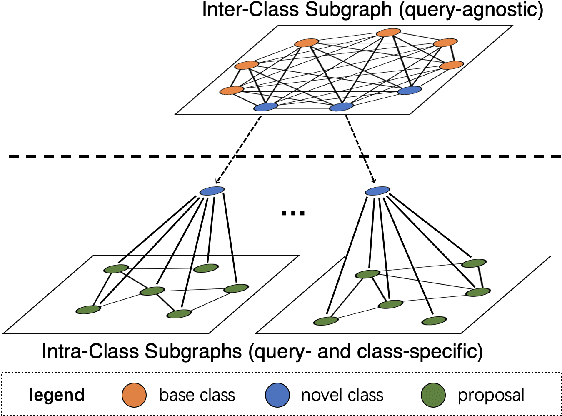
Few-shot object detection (FSOD) aims to detect never-seen objects using few examples. This field sees recent improvement owing to the meta-learning techniques by learning how to match between the query image and few-shot class examples, such that the learned model can generalize to few-shot novel classes. However, currently, most of the meta-learning-based methods perform pairwise matching between query image regions (usually proposals) and novel classes separately, therefore failing to take into account multiple relationships among them. In this paper, we propose a novel FSOD model using heterogeneous graph convolutional networks. Through efficient message passing among all the proposal and class nodes with three different types of edges, we could obtain context-aware proposal features and query-adaptive, multiclass-enhanced prototype representations for each class, which could help promote the pairwise matching and improve final FSOD accuracy. Extensive experimental results show that our proposed model, denoted as QA-FewDet, outperforms the current state-of-the-art approaches on the PASCAL VOC and MSCOCO FSOD benchmarks under different shots and evaluation metrics.