 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial-Magnifier: Spatial upsampling for multichannel speech enhancement
May 06, 2026While the spatial directivity of multichannel speech enhancement algorithms improves with the number of microphones, fitting large capture arrays into real-world edge devices is typically limited by physical constraints. To overcome this limitation, we propose Spatial-Magnifier, a neural network designed to generate virtual microphone (VM) signals from a limited set of real microphone (RM) measurements. Moreover, we introduce the Spatial Audio Representation Learning (SARL) framework, which leverages estimated VM signals and features to condition a downstream speech enhancement system. Experimental results demonstrate that the proposed framework outperforms existing spatial upsampling baselines across various speech extraction systems, including end-to-end multichannel speech enhancement and neural beamforming. The proposed method nearly recovers the oracle performance achieved when all microphones are available.
ArrayDPS-Refine: Generative Refinement of Discriminative Multi-Channel Speech Enhancement
Mar 25, 2026Multi-channel speech enhancement aims to recover clean speech from noisy multi-channel recordings. Most deep learning methods employ discriminative training, which can lead to non-linear distortions from regression-based objectives, especially under challenging environmental noise conditions. Inspired by ArrayDPS for unsupervised multi-channel source separation, we introduce ArrayDPS-Refine, a method designed to enhance the outputs of discriminative models using a clean speech diffusion prior. ArrayDPS-Refine is training-free, generative, and array-agnostic. It first estimates the noise spatial covariance matrix (SCM) from the enhanced speech produced by a discriminative model, then uses this estimated noise SCM for diffusion posterior sampling. This approach allows direct refinement of any discriminative model's output without retraining. Our results show that ArrayDPS-Refine consistently improves the performance of various discriminative models, including state-of-the-art waveform and STFT domain models. Audio demos are provided at https://xzwy.github.io/ArrayDPSRefineDemo/.
Unified Diffusion Refinement for Multi-Channel Speech Enhancement and Separation
Mar 25, 2026We propose Uni-ArrayDPS, a novel diffusion-based refinement framework for unified multi-channel speech enhancement and separation. Existing methods for multi-channel speech enhancement/separation are mostly discriminative and are highly effective at producing high-SNR outputs. However, they can still generate unnatural speech with non-linear distortions caused by the neural network and regression-based objectives. To address this issue, we propose Uni-ArrayDPS, which refines the outputs of any strong discriminative model using a speech diffusion prior. Uni-ArrayDPS is generative, array-agnostic, and training-free, and supports both enhancement and separation. Given a discriminative model's enhanced/separated speech, we use it, together with the noisy mixtures, to estimate the noise spatial covariance matrix (SCM). We then use this SCM to compute the likelihood required for diffusion posterior sampling of the clean speech source(s). Uni-ArrayDPS requires only a pre-trained clean-speech diffusion model as a prior and does not require additional training or fine-tuning, allowing it to generalize directly across tasks (enhancement/separation), microphone array geometries, and discriminative model backbones. Extensive experiments show that Uni-ArrayDPS consistently improves a wide range of discriminative models for both enhancement and separation tasks. We also report strong results on a real-world dataset. Audio demos are provided at \href{https://xzwy.github.io/Uni-ArrayDPS/}{https://xzwy.github.io/Uni-ArrayDPS/}.
Text-to-Stage: Spatial Layouts from Long-form Narratives
Mar 18, 2026In this work, we probe the ability of a language model to demonstrate spatial reasoning from unstructured text, mimicking human capabilities and automating a process that benefits many downstream media applications. Concretely, we study the narrative-to-play task: inferring stage-play layouts (scenes, speaker positions, movements, and room types) from text that lacks explicit spatial, positional, or relational cues. We then introduce a dramaturgy-inspired deterministic evaluation suite and, finally, a training and inference recipe that combines rejection SFT using Best-of-N sampling with RL from verifiable rewards via GRPO. Experiments on a text-only corpus of classical English literature demonstrate improvements over vanilla models across multiple metrics (character attribution, spatial plausibility, and movement economy), as well as alignment with an LLM-as-a-judge and subjective human preferences.
Conditional Flow Matching for Visually-Guided Acoustic Highlighting
Feb 03, 2026Visually-guided acoustic highlighting seeks to rebalance audio in alignment with the accompanying video, creating a coherent audio-visual experience. While visual saliency and enhancement have been widely studied, acoustic highlighting remains underexplored, often leading to misalignment between visual and auditory focus. Existing approaches use discriminative models, which struggle with the inherent ambiguity in audio remixing, where no natural one-to-one mapping exists between poorly-balanced and well-balanced audio mixes. To address this limitation, we reframe this task as a generative problem and introduce a Conditional Flow Matching (CFM) framework. A key challenge in iterative flow-based generation is that early prediction errors -- in selecting the correct source to enhance -- compound over steps and push trajectories off-manifold. To address this, we introduce a rollout loss that penalizes drift at the final step, encouraging self-correcting trajectories and stabilizing long-range flow integration. We further propose a conditioning module that fuses audio and visual cues before vector field regression, enabling explicit cross-modal source selection. Extensive quantitative and qualitative evaluations show that our method consistently surpasses the previous state-of-the-art discriminative approach, establishing that visually-guided audio remixing is best addressed through generative modeling.
Sound Event Detection with Boundary-Aware Optimization and Inference
Jan 07, 2026Temporal detection problems appear in many fields including time-series estimation, activity recognition and sound event detection (SED). In this work, we propose a new approach to temporal event modeling by explicitly modeling event onsets and offsets, and by introducing boundary-aware optimization and inference strategies that substantially enhance temporal event detection. The presented methodology incorporates new temporal modeling layers - Recurrent Event Detection (RED) and Event Proposal Network (EPN) - which, together with tailored loss functions, enable more effective and precise temporal event detection. We evaluate the proposed method in the SED domain using a subset of the temporally-strongly annotated portion of AudioSet. Experimental results show that our approach not only outperforms traditional frame-wise SED models with state-of-the-art post-processing, but also removes the need for post-processing hyperparameter tuning, and scales to achieve new state-of-the-art performance across all AudioSet Strong classes.
Learning to Highlight Audio by Watching Movies
May 17, 2025



Recent years have seen a significant increase in video content creation and consumption. Crafting engaging content requires the careful curation of both visual and audio elements. While visual cue curation, through techniques like optimal viewpoint selection or post-editing, has been central to media production, its natural counterpart, audio, has not undergone equivalent advancements. This often results in a disconnect between visual and acoustic saliency. To bridge this gap, we introduce a novel task: visually-guided acoustic highlighting, which aims to transform audio to deliver appropriate highlighting effects guided by the accompanying video, ultimately creating a more harmonious audio-visual experience. We propose a flexible, transformer-based multimodal framework to solve this task. To train our model, we also introduce a new dataset -- the muddy mix dataset, leveraging the meticulous audio and video crafting found in movies, which provides a form of free supervision. We develop a pseudo-data generation process to simulate poorly mixed audio, mimicking real-world scenarios through a three-step process -- separation, adjustment, and remixing. Our approach consistently outperforms several baselines in both quantitative and subjective evaluation. We also systematically study the impact of different types of contextual guidance and difficulty levels of the dataset. Our project page is here: https://wikichao.github.io/VisAH/.
Efficient Audiovisual Speech Processing via MUTUD: Multimodal Training and Unimodal Deployment
Jan 30, 2025



Building reliable speech systems often requires combining multiple modalities, like audio and visual cues. While such multimodal solutions frequently lead to improvements in performance and may even be critical in certain cases, they come with several constraints such as increased sensory requirements, computational cost, and modality synchronization, to mention a few. These challenges constrain the direct uses of these multimodal solutions in real-world applications. In this work, we develop approaches where the learning happens with all available modalities but the deployment or inference is done with just one or reduced modalities. To do so, we propose a Multimodal Training and Unimodal Deployment (MUTUD) framework which includes a Temporally Aligned Modality feature Estimation (TAME) module that can estimate information from missing modality using modalities present during inference. This innovative approach facilitates the integration of information across different modalities, enhancing the overall inference process by leveraging the strengths of each modality to compensate for the absence of certain modalities during inference. We apply MUTUD to various audiovisual speech tasks and show that it can reduce the performance gap between the multimodal and corresponding unimodal models to a considerable extent. MUTUD can achieve this while reducing the model size and compute compared to multimodal models, in some cases by almost 80%.
Tackling Interpretability in Audio Classification Networks with Non-negative Matrix Factorization
May 11, 2023This paper tackles two major problem settings for interpretability of audio processing networks, post-hoc and by-design interpretation. For post-hoc interpretation, we aim to interpret decisions of a network in terms of high-level audio objects that are also listenable for the end-user. This is extended to present an inherently interpretable model with high performance. To this end, we propose a novel interpreter design that incorporates non-negative matrix factorization (NMF). In particular, an interpreter is trained to generate a regularized intermediate embedding from hidden layers of a target network, learnt as time-activations of a pre-learnt NMF dictionary. Our methodology allows us to generate intuitive audio-based interpretations that explicitly enhance parts of the input signal most relevant for a network's decision. We demonstrate our method's applicability on a variety of classification tasks, including multi-label data for real-world audio and music.
Listen to Interpret: Post-hoc Interpretability for Audio Networks with NMF
Feb 23, 2022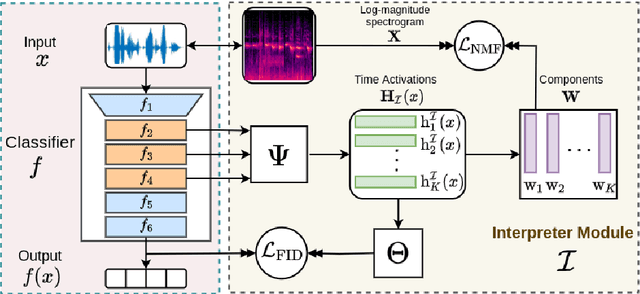
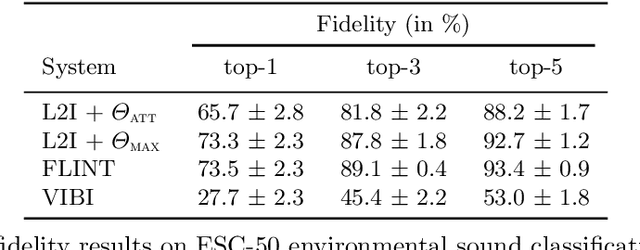

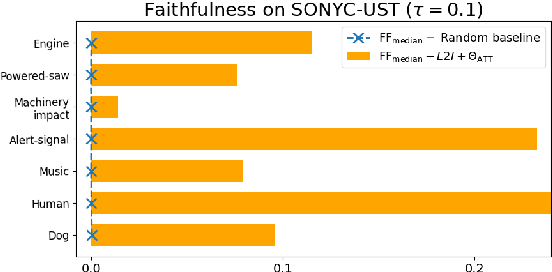
This paper tackles post-hoc interpretability for audio processing networks. Our goal is to interpret decisions of a network in terms of high-level audio objects that are also listenable for the end-user. To this end, we propose a novel interpreter design that incorporates non-negative matrix factorization (NMF). In particular, a carefully regularized interpreter module is trained to take hidden layer representations of the targeted network as input and produce time activations of pre-learnt NMF components as intermediate outputs. Our methodology allows us to generate intuitive audio-based interpretations that explicitly enhance parts of the input signal most relevant for a network's decision. We demonstrate our method's applicability on popular benchmarks, including a real-world multi-label classification task.