 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFragRel: Exploiting Fragment-level Relations in the External Memory of Large Language Models
Jun 05, 2024



To process contexts with unlimited length using Large Language Models (LLMs), recent studies explore hierarchically managing the long text. Only several text fragments are taken from the external memory and passed into the temporary working memory, i.e., LLM's context window. However, existing approaches isolatedly handle the text fragments without considering their structural connections, thereby suffering limited capability on texts with intensive inter-relations, e.g., coherent stories and code repositories. This work attempts to resolve this by exploiting the fragment-level relations in external memory. First, we formulate the fragment-level relations and present several instantiations for different text types. Next, we introduce a relation-aware fragment assessment criteria upon previous independent fragment assessment. Finally, we present the fragment-connected Hierarchical Memory based LLM. We validate the benefits of involving these relations on long story understanding, repository-level code generation, and long-term chatting.
PLA4D: Pixel-Level Alignments for Text-to-4D Gaussian Splatting
Jun 04, 2024As text-conditioned diffusion models (DMs) achieve breakthroughs in image, video, and 3D generation, the research community's focus has shifted to the more challenging task of text-to-4D synthesis, which introduces a temporal dimension to generate dynamic 3D objects. In this context, we identify Score Distillation Sampling (SDS), a widely used technique for text-to-3D synthesis, as a significant hindrance to text-to-4D performance due to its Janus-faced and texture-unrealistic problems coupled with high computational costs. In this paper, we propose \textbf{P}ixel-\textbf{L}evel \textbf{A}lignments for Text-to-\textbf{4D} Gaussian Splatting (\textbf{PLA4D}), a novel method that utilizes text-to-video frames as explicit pixel alignment targets to generate static 3D objects and inject motion into them. Specifically, we introduce Focal Alignment to calibrate camera poses for rendering and GS-Mesh Contrastive Learning to distill geometry priors from rendered image contrasts at the pixel level. Additionally, we develop Motion Alignment using a deformation network to drive changes in Gaussians and implement Reference Refinement for smooth 4D object surfaces. These techniques enable 4D Gaussian Splatting to align geometry, texture, and motion with generated videos at the pixel level. Compared to previous methods, PLA4D produces synthesized outputs with better texture details in less time and effectively mitigates the Janus-faced problem. PLA4D is fully implemented using open-source models, offering an accessible, user-friendly, and promising direction for 4D digital content creation. Our project page: https://github.com/MiaoQiaowei/PLA4D.github.io.
Reconstructing and Simulating Dynamic 3D Objects with Mesh-adsorbed Gaussian Splatting
Jun 03, 2024



3D reconstruction and simulation, while interrelated, have distinct objectives: reconstruction demands a flexible 3D representation adaptable to diverse scenes, whereas simulation requires a structured representation to model motion principles effectively. This paper introduces the Mesh-adsorbed Gaussian Splatting (MaGS) method to resolve such a dilemma. MaGS constrains 3D Gaussians to hover on the mesh surface, creating a mutual-adsorbed mesh-Gaussian 3D representation that combines the rendering flexibility of 3D Gaussians with the spatial coherence of meshes. Leveraging this representation, we introduce a learnable Relative Deformation Field (RDF) to model the relative displacement between the mesh and 3D Gaussians, extending traditional mesh-driven deformation paradigms that only rely on ARAP prior, thus capturing the motion of each 3D Gaussian more precisely. By joint optimizing meshes, 3D Gaussians, and RDF, MaGS achieves both high rendering accuracy and realistic deformation. Extensive experiments on the D-NeRF and NeRF-DS datasets demonstrate that MaGS can generate competitive results in both reconstruction and simulation.
Hard Cases Detection in Motion Prediction by Vision-Language Foundation Models
May 31, 2024



Addressing hard cases in autonomous driving, such as anomalous road users, extreme weather conditions, and complex traffic interactions, presents significant challenges. To ensure safety, it is crucial to detect and manage these scenarios effectively for autonomous driving systems. However, the rarity and high-risk nature of these cases demand extensive, diverse datasets for training robust models. Vision-Language Foundation Models (VLMs) have shown remarkable zero-shot capabilities as being trained on extensive datasets. This work explores the potential of VLMs in detecting hard cases in autonomous driving. We demonstrate the capability of VLMs such as GPT-4v in detecting hard cases in traffic participant motion prediction on both agent and scenario levels. We introduce a feasible pipeline where VLMs, fed with sequential image frames with designed prompts, effectively identify challenging agents or scenarios, which are verified by existing prediction models. Moreover, by taking advantage of this detection of hard cases by VLMs, we further improve the training efficiency of the existing motion prediction pipeline by performing data selection for the training samples suggested by GPT. We show the effectiveness and feasibility of our pipeline incorporating VLMs with state-of-the-art methods on NuScenes datasets. The code is accessible at https://github.com/KTH-RPL/Detect_VLM.
Prompt-Aware Adapter: Towards Learning Adaptive Visual Tokens for Multimodal Large Language Models
May 24, 2024To bridge the gap between vision and language modalities, Multimodal Large Language Models (MLLMs) usually learn an adapter that converts visual inputs to understandable tokens for Large Language Models (LLMs). However, most adapters generate consistent visual tokens, regardless of the specific objects of interest mentioned in the prompt. Since these adapters distribute equal attention to every detail in the image and focus on the entire scene, they may increase the cognitive load for LLMs, particularly when processing complex scenes. To alleviate this problem, we propose prompt-aware adapters. These adapters are designed with the capability to dynamically embed visual inputs based on the specific focus of the prompt. Specifically, prompt-aware adapters utilize both global and local textual features to capture the most relevant visual clues from the prompt at both coarse and fine granularity levels. This approach significantly enhances the ability of LLMs to understand and interpret visual content. Experiments on various visual question answering tasks, such as counting and position reasoning, demonstrate the effectiveness of prompt-aware adapters.
TOPA: Extend Large Language Models for Video Understanding via Text-Only Pre-Alignment
May 22, 2024



Recent advancements in image understanding have benefited from the extensive use of web image-text pairs. However, video understanding remains a challenge despite the availability of substantial web video-text data. This difficulty primarily arises from the inherent complexity of videos and the inefficient language supervision in recent web-collected video-text datasets. In this paper, we introduce Text-Only Pre-Alignment (TOPA), a novel approach to extend large language models (LLMs) for video understanding, without the need for pre-training on real video data. Specifically, we first employ an advanced LLM to automatically generate Textual Videos comprising continuous textual frames, along with corresponding annotations to simulate real video-text data. Then, these annotated textual videos are used to pre-align a language-only LLM with the video modality. To bridge the gap between textual and real videos, we employ the CLIP model as the feature extractor to align image and text modalities. During text-only pre-alignment, the continuous textual frames, encoded as a sequence of CLIP text features, are analogous to continuous CLIP image features, thus aligning the LLM with real video representation. Extensive experiments, including zero-shot evaluation and finetuning on various video understanding tasks, demonstrate that TOPA is an effective and efficient framework for aligning video content with LLMs. In particular, without training on any video data, the TOPA-Llama2-13B model achieves a Top-1 accuracy of 51.0% on the challenging long-form video understanding benchmark, Egoschema. This performance surpasses previous video-text pre-training approaches and proves competitive with recent GPT-3.5-based video agents.
BrainODE: Dynamic Brain Signal Analysis via Graph-Aided Neural Ordinary Differential Equations
Apr 30, 2024



Brain network analysis is vital for understanding the neural interactions regarding brain structures and functions, and identifying potential biomarkers for clinical phenotypes. However, widely used brain signals such as Blood Oxygen Level Dependent (BOLD) time series generated from functional Magnetic Resonance Imaging (fMRI) often manifest three challenges: (1) missing values, (2) irregular samples, and (3) sampling misalignment, due to instrumental limitations, impacting downstream brain network analysis and clinical outcome predictions. In this work, we propose a novel model called BrainODE to achieve continuous modeling of dynamic brain signals using Ordinary Differential Equations (ODE). By learning latent initial values and neural ODE functions from irregular time series, BrainODE effectively reconstructs brain signals at any time point, mitigating the aforementioned three data challenges of brain signals altogether. Comprehensive experimental results on real-world neuroimaging datasets demonstrate the superior performance of BrainODE and its capability of addressing the three data challenges.
AnyPattern: Towards In-context Image Copy Detection
Apr 28, 2024
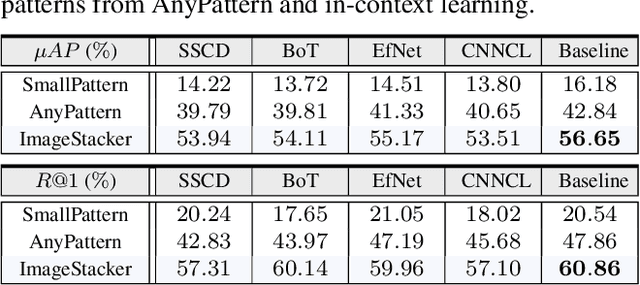
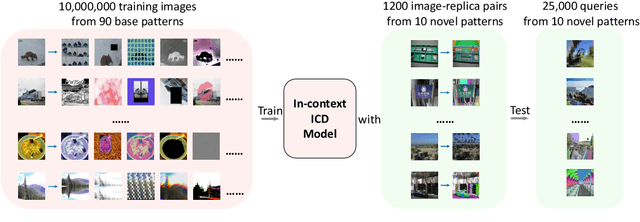
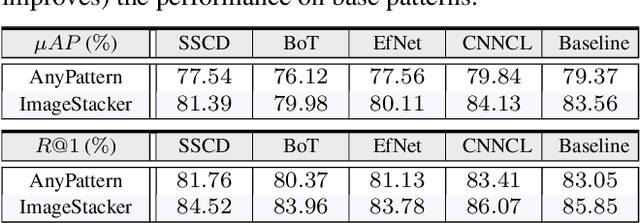
This paper explores in-context learning for image copy detection (ICD), i.e., prompting an ICD model to identify replicated images with new tampering patterns without the need for additional training. The prompts (or the contexts) are from a small set of image-replica pairs that reflect the new patterns and are used at inference time. Such in-context ICD has good realistic value, because it requires no fine-tuning and thus facilitates fast reaction against the emergence of unseen patterns. To accommodate the "seen $\rightarrow$ unseen" generalization scenario, we construct the first large-scale pattern dataset named AnyPattern, which has the largest number of tamper patterns ($90$ for training and $10$ for testing) among all the existing ones. We benchmark AnyPattern with popular ICD methods and reveal that existing methods barely generalize to novel patterns. We further propose a simple in-context ICD method named ImageStacker. ImageStacker learns to select the most representative image-replica pairs and employs them as the pattern prompts in a stacking manner (rather than the popular concatenation manner). Experimental results show (1) training with our large-scale dataset substantially benefits pattern generalization ($+26.66 \%$ $\mu AP$), (2) the proposed ImageStacker facilitates effective in-context ICD (another round of $+16.75 \%$ $\mu AP$), and (3) AnyPattern enables in-context ICD, i.e., without such a large-scale dataset, in-context learning does not emerge even with our ImageStacker. Beyond the ICD task, we also demonstrate how AnyPattern can benefit artists, i.e., the pattern retrieval method trained on AnyPattern can be generalized to identify style mimicry by text-to-image models. The project is publicly available at https://anypattern.github.io.
Revealing the Two Sides of Data Augmentation: An Asymmetric Distillation-based Win-Win Solution for Open-Set Recognition
Apr 28, 2024



In this paper, we reveal the two sides of data augmentation: enhancements in closed-set recognition correlate with a significant decrease in open-set recognition. Through empirical investigation, we find that multi-sample-based augmentations would contribute to reducing feature discrimination, thereby diminishing the open-set criteria. Although knowledge distillation could impair the feature via imitation, the mixed feature with ambiguous semantics hinders the distillation. To this end, we propose an asymmetric distillation framework by feeding teacher model extra raw data to enlarge the benefit of teacher. Moreover, a joint mutual information loss and a selective relabel strategy are utilized to alleviate the influence of hard mixed samples. Our method successfully mitigates the decline in open-set and outperforms SOTAs by 2%~3% AUROC on the Tiny-ImageNet dataset and experiments on large-scale dataset ImageNet-21K demonstrate the generalization of our method.
Understanding Privacy Risks of Embeddings Induced by Large Language Models
Apr 25, 2024



Large language models (LLMs) show early signs of artificial general intelligence but struggle with hallucinations. One promising solution to mitigate these hallucinations is to store external knowledge as embeddings, aiding LLMs in retrieval-augmented generation. However, such a solution risks compromising privacy, as recent studies experimentally showed that the original text can be partially reconstructed from text embeddings by pre-trained language models. The significant advantage of LLMs over traditional pre-trained models may exacerbate these concerns. To this end, we investigate the effectiveness of reconstructing original knowledge and predicting entity attributes from these embeddings when LLMs are employed. Empirical findings indicate that LLMs significantly improve the accuracy of two evaluated tasks over those from pre-trained models, regardless of whether the texts are in-distribution or out-of-distribution. This underscores a heightened potential for LLMs to jeopardize user privacy, highlighting the negative consequences of their widespread use. We further discuss preliminary strategies to mitigate this risk.