 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fixed-Point Neural Operator for Size- and Functional-Transferable Hamiltonian Prediction
Jun 12, 2026Predicting the Kohn-Sham Hamiltonian with machine learning can accelerate density functional theory while retaining access to molecular orbitals, energy levels, and electronic-structure observables that energy-only surrogates cannot resolve. Yet element-wise agreement with the converged Hamiltonian, an implicit fixed point of the self-consistent field iteration, does not determine the occupied subspace that governs orbital energies and densities. Here we present HamEvo, a neural operator that learns the single-step self-consistent update and returns the converged Hamiltonian as its fixed point. HamEvo is pre-trained on intermediate self-consistent trajectories and calibrated at equilibrium with density-matrix supervision. Across benchmarks from MD17 to drug-like QMugs, HamEvo lowers Hamiltonian errors by 35-49% over direct-regression and deep-equilibrium baselines, and predicts QMugs HOMO and LUMO energies with mean absolute errors of 0.036 and 0.053 eV, near the 1 kcal/mol chemical-accuracy scale. Few-shot fine-tuning with only 20 reference conformations extends HamEvo to molecules of up to 122 atoms, well beyond the size range covered by pre-training. With thermal molecular-dynamics sampling, HamEvo captures temperature-dependent HOMO-LUMO gap renormalization beyond the harmonic approximation. Inference is up to 242 times faster than conventional DFT.
PDEAgent-Bench: A Multi-Metric, Multi-Library Benchmark for PDE Solver Generation
May 10, 2026PDE-to-solver code generation aims to automatically synthesize executable numerical solvers from partial differential equation (PDE) specifications. This task requires not only understanding the mathematical structure of PDEs, but also selecting appropriate discretization schemes and solver configurations, and correctly implementing the resulting formulations in finite-element method (FEM) libraries. Existing code generation benchmarks mainly evaluate syntactic correctness, or success on predefined test cases. To our knowledge, there is currently no publicly available benchmark specifically for PDE-to-solver code generation, and general-purpose code benchmarks do not fully capture the unique challenges of numerical PDE solution, such as ensuring solver accuracy, efficiency, and compatibility with professional FEM libraries. We introduce PDEAgent-Bench, to the best of our knowledge, the first multi-metric, multi-library benchmark for PDE-to-solver code generation. PDEAgent-Bench contains 645 instances across 6 mathematical categories and 11 PDE families, with common FEM libraries for DOLFINx, Firedrake, and deal.II. Each instance provides an agent-facing problem specification, a reference solution on a prescribed evaluation grid, and case-specific accuracy and runtime targets. PDEAgent-Bench adopts a staged evaluation framework in which generated solvers must sequentially pass executability, numerical accuracy, and computational efficiency checks. Experiments with representative LLMs and code agents show that models can often produce runnable code, but their pass rate drops substantially once accuracy and efficiency requirements are enforced. These results indicate that current agents remain limited in producing numerically reliable and efficient PDE solvers, and that PDEAgent-Bench provides a reproducible testbed grounded in the practical requirements of numerical PDE solving.
Point-Calibrated Spectral Neural Operators
Oct 15, 2024Two typical neural models have been extensively studied for operator learning, learning in spatial space via attention mechanism or learning in spectral space via spectral analysis technique such as Fourier Transform. Spatial learning enables point-level flexibility but lacks global continuity constraint, while spectral learning enforces spectral continuity prior but lacks point-wise adaptivity. This work innovatively combines the continuity prior and the point-level flexibility, with the introduced Point-Calibrated Spectral Transform. It achieves this by calibrating the preset spectral eigenfunctions with the predicted point-wise frequency preference via neural gate mechanism. Beyond this, we introduce Point-Calibrated Spectral Neural Operators, which learn operator mappings by approximating functions with the point-level adaptive spectral basis, thereby not only preserving the benefits of spectral prior but also boasting the superior adaptability comparable to the attention mechanism. Comprehensive experiments demonstrate its consistent performance enhancement in extensive PDE solving scenarios.
DeltaPhi: Learning Physical Trajectory Residual for PDE Solving
Jun 14, 2024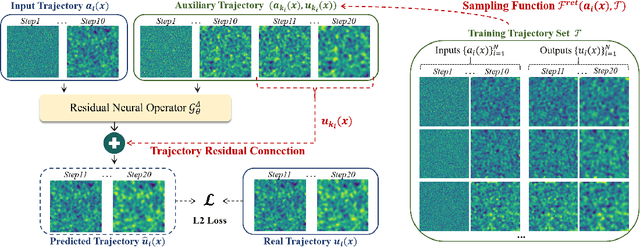
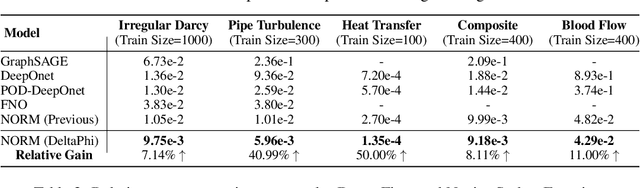
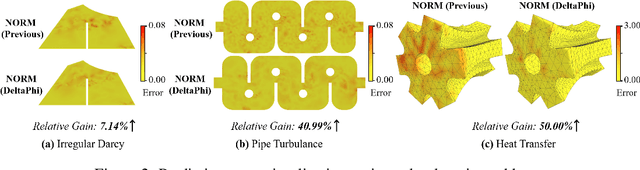
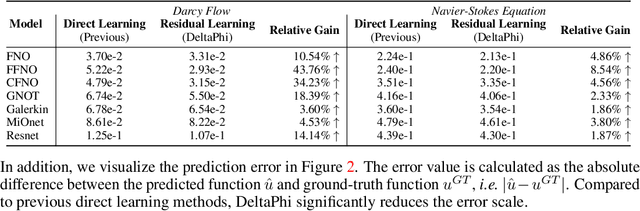
Although neural operator networks theoretically approximate any operator mapping, the limited generalization capability prevents them from learning correct physical dynamics when potential data biases exist, particularly in the practical PDE solving scenario where the available data amount is restricted or the resolution is extremely low. To address this issue, we propose and formulate the Physical Trajectory Residual Learning (DeltaPhi), which learns to predict the physical residuals between the pending solved trajectory and a known similar auxiliary trajectory. First, we transform the direct operator mapping between input-output function fields in original training data to residual operator mapping between input function pairs and output function residuals. Next, we learn the surrogate model for the residual operator mapping based on existing neural operator networks. Additionally, we design helpful customized auxiliary inputs for efficient optimization. Through extensive experiments, we conclude that, compared to direct learning, physical residual learning is preferred for PDE solving.
FragRel: Exploiting Fragment-level Relations in the External Memory of Large Language Models
Jun 05, 2024



To process contexts with unlimited length using Large Language Models (LLMs), recent studies explore hierarchically managing the long text. Only several text fragments are taken from the external memory and passed into the temporary working memory, i.e., LLM's context window. However, existing approaches isolatedly handle the text fragments without considering their structural connections, thereby suffering limited capability on texts with intensive inter-relations, e.g., coherent stories and code repositories. This work attempts to resolve this by exploiting the fragment-level relations in external memory. First, we formulate the fragment-level relations and present several instantiations for different text types. Next, we introduce a relation-aware fragment assessment criteria upon previous independent fragment assessment. Finally, we present the fragment-connected Hierarchical Memory based LLM. We validate the benefits of involving these relations on long story understanding, repository-level code generation, and long-term chatting.
Efficient Emotional Adaptation for Audio-Driven Talking-Head Generation
Sep 10, 2023



Audio-driven talking-head synthesis is a popular research topic for virtual human-related applications. However, the inflexibility and inefficiency of existing methods, which necessitate expensive end-to-end training to transfer emotions from guidance videos to talking-head predictions, are significant limitations. In this work, we propose the Emotional Adaptation for Audio-driven Talking-head (EAT) method, which transforms emotion-agnostic talking-head models into emotion-controllable ones in a cost-effective and efficient manner through parameter-efficient adaptations. Our approach utilizes a pretrained emotion-agnostic talking-head transformer and introduces three lightweight adaptations (the Deep Emotional Prompts, Emotional Deformation Network, and Emotional Adaptation Module) from different perspectives to enable precise and realistic emotion controls. Our experiments demonstrate that our approach achieves state-of-the-art performance on widely-used benchmarks, including LRW and MEAD. Additionally, our parameter-efficient adaptations exhibit remarkable generalization ability, even in scenarios where emotional training videos are scarce or nonexistent. Project website: https://yuangan.github.io/eat/