 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject-Centric Framework for Video Moment Retrieval
Dec 20, 2025Most existing video moment retrieval methods rely on temporal sequences of frame- or clip-level features that primarily encode global visual and semantic information. However, such representations often fail to capture fine-grained object semantics and appearance, which are crucial for localizing moments described by object-oriented queries involving specific entities and their interactions. In particular, temporal dynamics at the object level have been largely overlooked, limiting the effectiveness of existing approaches in scenarios requiring detailed object-level reasoning. To address this limitation, we propose a novel object-centric framework for moment retrieval. Our method first extracts query-relevant objects using a scene graph parser and then generates scene graphs from video frames to represent these objects and their relationships. Based on the scene graphs, we construct object-level feature sequences that encode rich visual and semantic information. These sequences are processed by a relational tracklet transformer, which models spatio-temporal correlations among objects over time. By explicitly capturing object-level state changes, our framework enables more accurate localization of moments aligned with object-oriented queries. We evaluated our method on three benchmarks: Charades-STA, QVHighlights, and TACoS. Experimental results demonstrate that our method outperforms existing state-of-the-art methods across all benchmarks.
STAR: Skeleton-aware Text-based 4D Avatar Generation with In-Network Motion Retargeting
Jun 07, 2024The creation of 4D avatars (i.e., animated 3D avatars) from text description typically uses text-to-image (T2I) diffusion models to synthesize 3D avatars in the canonical space and subsequently applies animation with target motions. However, such an optimization-by-animation paradigm has several drawbacks. (1) For pose-agnostic optimization, the rendered images in canonical pose for naive Score Distillation Sampling (SDS) exhibit domain gap and cannot preserve view-consistency using only T2I priors, and (2) For post hoc animation, simply applying the source motions to target 3D avatars yields translation artifacts and misalignment. To address these issues, we propose Skeleton-aware Text-based 4D Avatar generation with in-network motion Retargeting (STAR). STAR considers the geometry and skeleton differences between the template mesh and target avatar, and corrects the mismatched source motion by resorting to the pretrained motion retargeting techniques. With the informatively retargeted and occlusion-aware skeleton, we embrace the skeleton-conditioned T2I and text-to-video (T2V) priors, and propose a hybrid SDS module to coherently provide multi-view and frame-consistent supervision signals. Hence, STAR can progressively optimize the geometry, texture, and motion in an end-to-end manner. The quantitative and qualitative experiments demonstrate our proposed STAR can synthesize high-quality 4D avatars with vivid animations that align well with the text description. Additional ablation studies shows the contributions of each component in STAR. The source code and demos are available at: \href{https://star-avatar.github.io}{https://star-avatar.github.io}.
TOPA: Extend Large Language Models for Video Understanding via Text-Only Pre-Alignment
May 22, 2024



Recent advancements in image understanding have benefited from the extensive use of web image-text pairs. However, video understanding remains a challenge despite the availability of substantial web video-text data. This difficulty primarily arises from the inherent complexity of videos and the inefficient language supervision in recent web-collected video-text datasets. In this paper, we introduce Text-Only Pre-Alignment (TOPA), a novel approach to extend large language models (LLMs) for video understanding, without the need for pre-training on real video data. Specifically, we first employ an advanced LLM to automatically generate Textual Videos comprising continuous textual frames, along with corresponding annotations to simulate real video-text data. Then, these annotated textual videos are used to pre-align a language-only LLM with the video modality. To bridge the gap between textual and real videos, we employ the CLIP model as the feature extractor to align image and text modalities. During text-only pre-alignment, the continuous textual frames, encoded as a sequence of CLIP text features, are analogous to continuous CLIP image features, thus aligning the LLM with real video representation. Extensive experiments, including zero-shot evaluation and finetuning on various video understanding tasks, demonstrate that TOPA is an effective and efficient framework for aligning video content with LLMs. In particular, without training on any video data, the TOPA-Llama2-13B model achieves a Top-1 accuracy of 51.0% on the challenging long-form video understanding benchmark, Egoschema. This performance surpasses previous video-text pre-training approaches and proves competitive with recent GPT-3.5-based video agents.
Bridging the Intent Gap: Knowledge-Enhanced Visual Generation
May 21, 2024



For visual content generation, discrepancies between user intentions and the generated content have been a longstanding problem. This discrepancy arises from two main factors. First, user intentions are inherently complex, with subtle details not fully captured by input prompts. The absence of such details makes it challenging for generative models to accurately reflect the intended meaning, leading to a mismatch between the desired and generated output. Second, generative models trained on visual-label pairs lack the comprehensive knowledge to accurately represent all aspects of the input data in their generated outputs. To address these challenges, we propose a knowledge-enhanced iterative refinement framework for visual content generation. We begin by analyzing and identifying the key challenges faced by existing generative models. Then, we introduce various knowledge sources, including human insights, pre-trained models, logic rules, and world knowledge, which can be leveraged to address these challenges. Furthermore, we propose a novel visual generation framework that incorporates a knowledge-based feedback module to iteratively refine the generation process. This module gradually improves the alignment between the generated content and user intentions. We demonstrate the efficacy of the proposed framework through preliminary results, highlighting the potential of knowledge-enhanced generative models for intention-aligned content generation.
Finetuning Text-to-Image Diffusion Models for Fairness
Nov 11, 2023



The rapid adoption of text-to-image diffusion models in society underscores an urgent need to address their biases. Without interventions, these biases could propagate a distorted worldview and limit opportunities for minority groups. In this work, we frame fairness as a distributional alignment problem. Our solution consists of two main technical contributions: (1) a distributional alignment loss that steers specific characteristics of the generated images towards a user-defined target distribution, and (2) biased direct finetuning of diffusion model's sampling process, which leverages a biased gradient to more effectively optimize losses defined on the generated images. Empirically, our method markedly reduces gender, racial, and their intersectional biases for occupational prompts. Gender bias is significantly reduced even when finetuning just five soft tokens. Crucially, our method supports diverse perspectives of fairness beyond absolute equality, which is demonstrated by controlling age to a $75\%$ young and $25\%$ old distribution while simultaneously debiasing gender and race. Finally, our method is scalable: it can debias multiple concepts at once by simply including these prompts in the finetuning data. We hope our work facilitates the social alignment of T2I generative AI. We will share code and various debiased diffusion model adaptors.
ELIP: Efficient Language-Image Pre-training with Fewer Vision Tokens
Sep 28, 2023Learning a versatile language-image model is computationally prohibitive under a limited computing budget. This paper delves into the efficient language-image pre-training, an area that has received relatively little attention despite its importance in reducing computational cost and footprint. To that end, we propose a vision token pruning and merging method, ie ELIP, to remove less influential tokens based on the supervision of language outputs. Our method is designed with several strengths, such as being computation-efficient, memory-efficient, and trainable-parameter-free, and is distinguished from previous vision-only token pruning approaches by its alignment with task objectives. We implement this method in a progressively pruning manner using several sequential blocks. To evaluate its generalization performance, we apply ELIP to three commonly used language-image pre-training models and utilize public image-caption pairs with 4M images for pre-training. Our experiments demonstrate that with the removal of ~30$\%$ vision tokens across 12 ViT layers, ELIP maintains significantly comparable performance with baselines ($\sim$0.32 accuracy drop on average) over various downstream tasks including cross-modal retrieval, VQA, image captioning, etc. In addition, the spared GPU resources by our ELIP allow us to scale up with larger batch sizes, thereby accelerating model pre-training and even sometimes enhancing downstream model performance. Our code will be released at https://github.com/guoyang9/ELIP.
MCM: Multi-condition Motion Synthesis Framework for Multi-scenario
Sep 06, 2023



The objective of the multi-condition human motion synthesis task is to incorporate diverse conditional inputs, encompassing various forms like text, music, speech, and more. This endows the task with the capability to adapt across multiple scenarios, ranging from text-to-motion and music-to-dance, among others. While existing research has primarily focused on single conditions, the multi-condition human motion generation remains underexplored. In this paper, we address these challenges by introducing MCM, a novel paradigm for motion synthesis that spans multiple scenarios under diverse conditions. The MCM framework is able to integrate with any DDPM-like diffusion model to accommodate multi-conditional information input while preserving its generative capabilities. Specifically, MCM employs two-branch architecture consisting of a main branch and a control branch. The control branch shares the same structure as the main branch and is initialized with the parameters of the main branch, effectively maintaining the generation ability of the main branch and supporting multi-condition input. We also introduce a Transformer-based diffusion model MWNet (DDPM-like) as our main branch that can capture the spatial complexity and inter-joint correlations in motion sequences through a channel-dimension self-attention module. Quantitative comparisons demonstrate that our approach achieves SoTA results in both text-to-motion and competitive results in music-to-dance tasks, comparable to task-specific methods. Furthermore, the qualitative evaluation shows that MCM not only streamlines the adaptation of methodologies originally designed for text-to-motion tasks to domains like music-to-dance and speech-to-gesture, eliminating the need for extensive network re-configurations but also enables effective multi-condition modal control, realizing "once trained is motion need".
A Study on Differentiable Logic and LLMs for EPIC-KITCHENS-100 Unsupervised Domain Adaptation Challenge for Action Recognition 2023
Jul 13, 2023



In this technical report, we present our findings from a study conducted on the EPIC-KITCHENS-100 Unsupervised Domain Adaptation task for Action Recognition. Our research focuses on the innovative application of a differentiable logic loss in the training to leverage the co-occurrence relations between verb and noun, as well as the pre-trained Large Language Models (LLMs) to generate the logic rules for the adaptation to unseen action labels. Specifically, the model's predictions are treated as the truth assignment of a co-occurrence logic formula to compute the logic loss, which measures the consistency between the predictions and the logic constraints. By using the verb-noun co-occurrence matrix generated from the dataset, we observe a moderate improvement in model performance compared to our baseline framework. To further enhance the model's adaptability to novel action labels, we experiment with rules generated using GPT-3.5, which leads to a slight decrease in performance. These findings shed light on the potential and challenges of incorporating differentiable logic and LLMs for knowledge extraction in unsupervised domain adaptation for action recognition. Our final submission (entitled `NS-LLM') achieved the first place in terms of top-1 action recognition accuracy.
Chairs Can be Stood on: Overcoming Object Bias in Human-Object Interaction Detection
Jul 06, 2022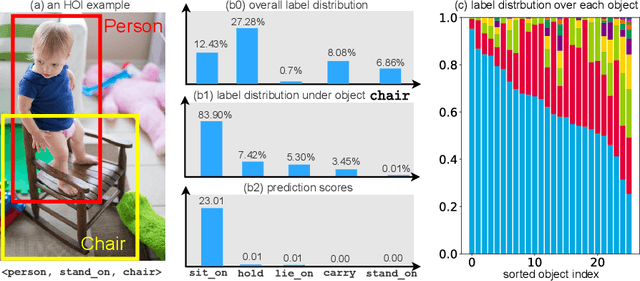
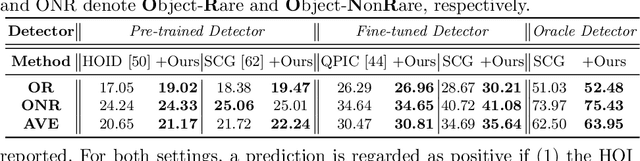
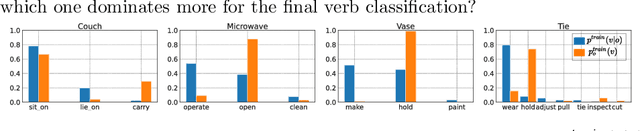
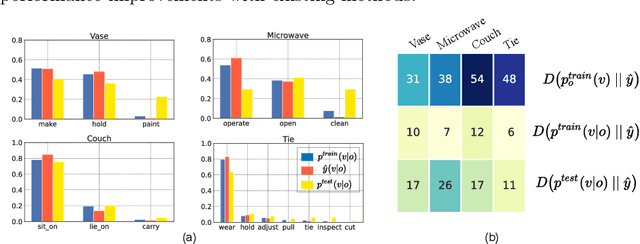
Detecting Human-Object Interaction (HOI) in images is an important step towards high-level visual comprehension. Existing work often shed light on improving either human and object detection, or interaction recognition. However, due to the limitation of datasets, these methods tend to fit well on frequent interactions conditioned on the detected objects, yet largely ignoring the rare ones, which is referred to as the object bias problem in this paper. In this work, we for the first time, uncover the problem from two aspects: unbalanced interaction distribution and biased model learning. To overcome the object bias problem, we propose a novel plug-and-play Object-wise Debiasing Memory (ODM) method for re-balancing the distribution of interactions under detected objects. Equipped with carefully designed read and write strategies, the proposed ODM allows rare interaction instances to be more frequently sampled for training, thereby alleviating the object bias induced by the unbalanced interaction distribution. We apply this method to three advanced baselines and conduct experiments on the HICO-DET and HOI-COCO datasets. To quantitatively study the object bias problem, we advocate a new protocol for evaluating model performance. As demonstrated in the experimental results, our method brings consistent and significant improvements over baselines, especially on rare interactions under each object. In addition, when evaluating under the conventional standard setting, our method achieves new state-of-the-art on the two benchmarks.
Distance Matters in Human-Object Interaction Detection
Jul 05, 2022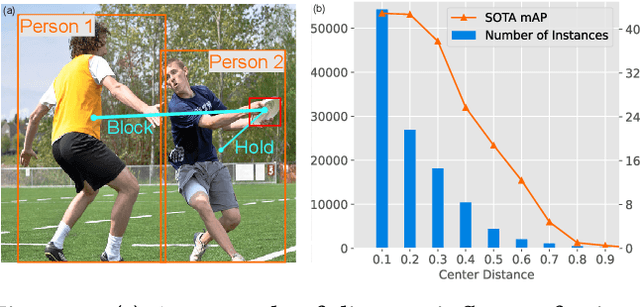
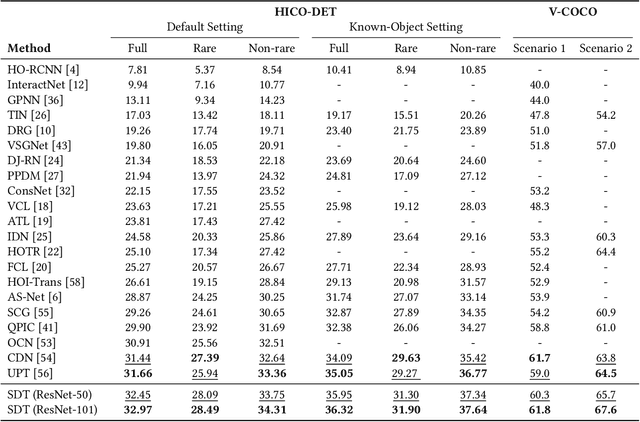
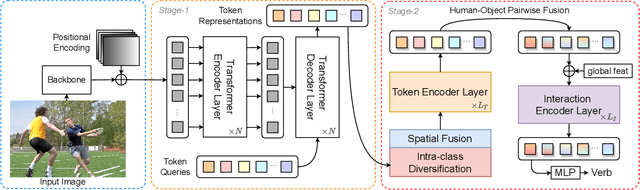
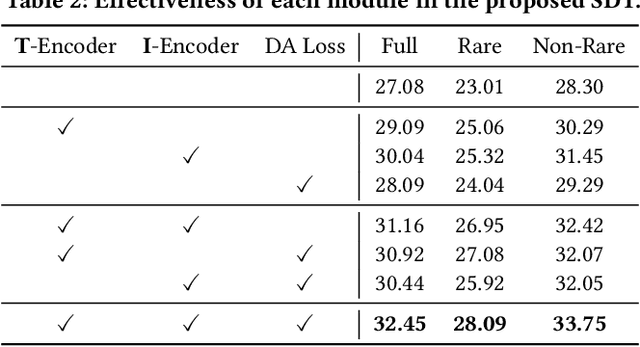
Human-Object Interaction (HOI) detection has received considerable attention in the context of scene understanding. Despite the growing progress on benchmarks, we realize that existing methods often perform unsatisfactorily on distant interactions, where the leading causes are two-fold: 1) Distant interactions are by nature more difficult to recognize than close ones. A natural scene often involves multiple humans and objects with intricate spatial relations, making the interaction recognition for distant human-object largely affected by complex visual context. 2) Insufficient number of distant interactions in benchmark datasets results in under-fitting on these instances. To address these problems, in this paper, we propose a novel two-stage method for better handling distant interactions in HOI detection. One essential component in our method is a novel Far Near Distance Attention module. It enables information propagation between humans and objects, whereby the spatial distance is skillfully taken into consideration. Besides, we devise a novel Distance-Aware loss function which leads the model to focus more on distant yet rare interactions. We conduct extensive experiments on two challenging datasets - HICO-DET and V-COCO. The results demonstrate that the proposed method can surpass existing approaches by a large margin, resulting in new state-of-the-art performance.