 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViser: Imperative, Web-based 3D Visualization in Python
Jul 30, 2025We present Viser, a 3D visualization library for computer vision and robotics. Viser aims to bring easy and extensible 3D visualization to Python: we provide a comprehensive set of 3D scene and 2D GUI primitives, which can be used independently with minimal setup or composed to build specialized interfaces. This technical report describes Viser's features, interface, and implementation. Key design choices include an imperative-style API and a web-based viewer, which improve compatibility with modern programming patterns and workflows.
LightCom: A Generative AI-Augmented Framework for QoE-Oriented Communications
Jul 23, 2025Data-intensive and immersive applications, such as virtual reality, impose stringent quality of experience (QoE) requirements that challenge traditional quality of service (QoS)-driven communication systems. This paper presents LightCom, a lightweight encoding and generative AI (GenAI)-augmented decoding framework, designed for QoE-oriented communications under low signal-to-noise ratio (SNR) conditions. LightCom simplifies transmitter design by applying basic low-pass filtering for source coding and minimal channel coding, significantly reducing processing complexity and energy consumption. At the receiver, GenAI models reconstruct high-fidelity content from highly compressed and degraded signals by leveraging generative priors to infer semantic and structural information beyond traditional decoding capabilities. The key design principles are analyzed, along with the sufficiency and error-resilience of the source representation. We also develop importance-aware power allocation strategies to enhance QoE and extend perceived coverage. Simulation results demonstrate that LightCom achieves up to a $14$ dB improvement in robustness and a $9$ dB gain in perceived coverage, outperforming traditional QoS-driven systems relying on sophisticated source and channel coding. This paradigm shift moves communication systems towards human-centric QoE metrics rather than bit-level fidelity, paving the way for more efficient and resilient wireless networks.
Leveraging Bi-Directional Channel Reciprocity for Robust Ultra-Low-Rate Implicit CSI Feedback with Deep Learning
Jul 16, 2025



Deep learning-based implicit channel state information (CSI) feedback has been introduced to enhance spectral efficiency in massive MIMO systems. Existing methods often show performance degradation in ultra-low-rate scenarios and inadaptability across diverse environments. In this paper, we propose Dual-ImRUNet, an efficient uplink-assisted deep implicit CSI feedback framework incorporating two novel plug-in preprocessing modules to achieve ultra-low feedback rates while maintaining high environmental robustness. First, a novel bi-directional correlation enhancement module is proposed to strengthen the correlation between uplink and downlink CSI eigenvector matrices. This module projects highly correlated uplink and downlink channel matrices into their respective eigenspaces, effectively reducing redundancy for ultra-low-rate feedback. Second, an innovative input format alignment module is designed to maintain consistent data distributions at both encoder and decoder sides without extra transmission overhead, thereby enhancing robustness against environmental variations. Finally, we develop an efficient transformer-based implicit CSI feedback network to exploit angular-delay domain sparsity and bi-directional correlation for ultra-low-rate CSI compression. Simulation results demonstrate successful reduction of the feedback overhead by 85% compared with the state-of-the-art method and robustness against unseen environments.
Squeeze the Soaked Sponge: Efficient Off-policy Reinforcement Finetuning for Large Language Model
Jul 09, 2025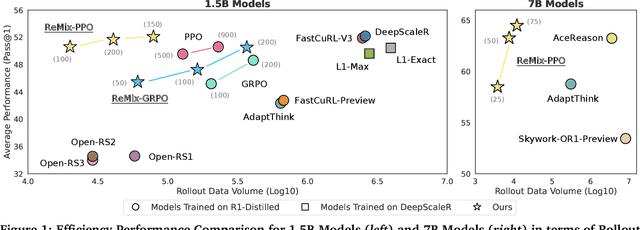
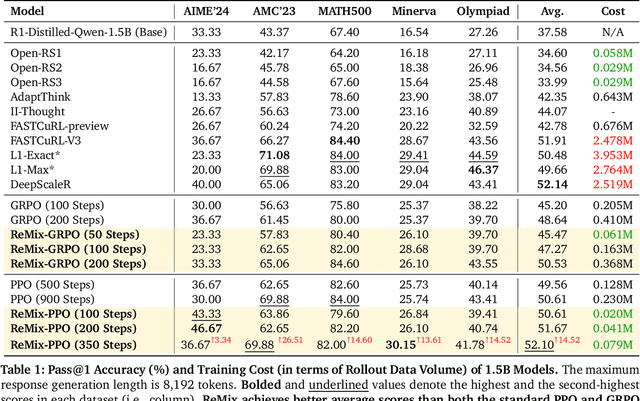
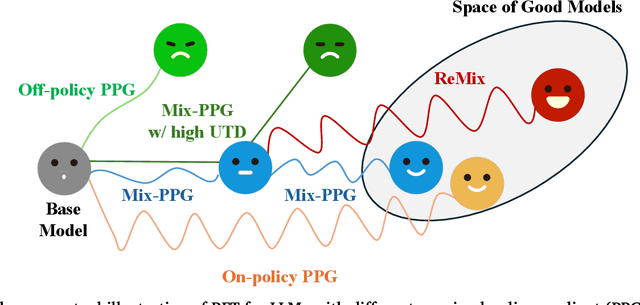

Reinforcement Learning (RL) has demonstrated its potential to improve the reasoning ability of Large Language Models (LLMs). One major limitation of most existing Reinforcement Finetuning (RFT) methods is that they are on-policy RL in nature, i.e., data generated during the past learning process is not fully utilized. This inevitably comes at a significant cost of compute and time, posing a stringent bottleneck on continuing economic and efficient scaling. To this end, we launch the renaissance of off-policy RL and propose Reincarnating Mix-policy Proximal Policy Gradient (ReMix), a general approach to enable on-policy RFT methods like PPO and GRPO to leverage off-policy data. ReMix consists of three major components: (1) Mix-policy proximal policy gradient with an increased Update-To-Data (UTD) ratio for efficient training; (2) KL-Convex policy constraint to balance the trade-off between stability and flexibility; (3) Policy reincarnation to achieve a seamless transition from efficient early-stage learning to steady asymptotic improvement. In our experiments, we train a series of ReMix models upon PPO, GRPO and 1.5B, 7B base models. ReMix shows an average Pass@1 accuracy of 52.10% (for 1.5B model) with 0.079M response rollouts, 350 training steps and achieves 63.27%/64.39% (for 7B model) with 0.007M/0.011M response rollouts, 50/75 training steps, on five math reasoning benchmarks (i.e., AIME'24, AMC'23, Minerva, OlympiadBench, and MATH500). Compared with 15 recent advanced models, ReMix shows SOTA-level performance with an over 30x to 450x reduction in training cost in terms of rollout data volume. In addition, we reveal insightful findings via multifaceted analysis, including the implicit preference for shorter responses due to the Whipping Effect of off-policy discrepancy, the collapse mode of self-reflection behavior under the presence of severe off-policyness, etc.
Cluster-Aware Two-Stage Method for Fast Iterative MIMO Detection in LEO Satellite Communications
Jun 26, 2025In this paper, a cluster-aware two-stage multiple-input multiple-output (MIMO) detection method is proposed for direct-to-cell satellite communications. The method achieves computational efficiency by exploiting a distinctive property of satellite MIMO channels: users within the same geographical cluster exhibit highly correlated channel characteristics due to their physical proximity, which typically impedes convergence in conventional iterative MIMO detectors. The proposed method implements a two-stage strategy that first eliminates intra-cluster interference using computationally efficient small matrix inversions, then utilizes these pre-computed matrices to accelerate standard iterative MIMO detectors such as Gauss-Seidel (GS) and symmetric successive over-relaxation (SSOR) for effective inter-cluster interference cancellation. Computer simulations demonstrate that the proposed method achieves more than 12 times faster convergence under perfect channel state information. Even when accounting for channel estimation errors, the method maintains 9 times faster convergence, demonstrating its robustness and effectiveness for next-generation satellite MIMO communications.
Language-Image Alignment with Fixed Text Encoders
Jun 04, 2025Currently, the most dominant approach to establishing language-image alignment is to pre-train text and image encoders jointly through contrastive learning, such as CLIP and its variants. In this work, we question whether such a costly joint training is necessary. In particular, we investigate if a pre-trained fixed large language model (LLM) offers a good enough text encoder to guide visual representation learning. That is, we propose to learn Language-Image alignment with a Fixed Text encoder (LIFT) from an LLM by training only the image encoder. Somewhat surprisingly, through comprehensive benchmarking and ablation studies, we find that this much simplified framework LIFT is highly effective and it outperforms CLIP in most scenarios that involve compositional understanding and long captions, while achieving considerable gains in computational efficiency. Our work takes a first step towards systematically exploring how text embeddings from LLMs can guide visual learning and suggests an alternative design choice for learning language-aligned visual representations.
Attention-Only Transformers via Unrolled Subspace Denoising
Jun 04, 2025Despite the popularity of transformers in practice, their architectures are empirically designed and neither mathematically justified nor interpretable. Moreover, as indicated by many empirical studies, some components of transformer architectures may be redundant. To derive a fully interpretable transformer architecture with only necessary components, we contend that the goal of representation learning is to compress a set of noisy initial token representations towards a mixture of low-dimensional subspaces. To compress these noisy token representations, an associated denoising operation naturally takes the form of a multi-head (subspace) self-attention. By unrolling such iterative denoising operations into a deep network, we arrive at a highly compact architecture that consists of \textit{only} self-attention operators with skip connections at each layer. Moreover, we show that each layer performs highly efficient denoising: it improves the signal-to-noise ratio of token representations \textit{at a linear rate} with respect to the number of layers. Despite its simplicity, extensive experiments on vision and language tasks demonstrate that such a transformer achieves performance close to that of standard transformer architectures such as GPT-2 and CRATE.
Dynamic Resource Allocation in Distributed MIMO-LEO Satellite Networks
May 27, 2025This paper characterizes the impacts of channel estimation errors and Rician factors on achievable data rate and investigates the user scheduling strategy, combining scheme, power control, and dynamic bandwidth allocation to maximize the sum data rate in the distributed multiple-input-multiple-output (MIMO)-enabled low earth orbit (LEO) satellite networks. However, due to the resource-assignment problem, it is challenging to find the optimal solution for maximizing the sum data rate. To transform this problem into a more tractable form, we first quantify the channel estimation errors based on the minimum mean square error (MMSE) estimator and rigorously derive a closed-form lower bound of the achievable data rate, offering an explicit formulation for resource allocation. Then, to solve the NP-hard problem, we decompose it into three sub-problems, namely, user scheduling strategy, joint combination and power control, and dynamic bandwidth allocation, by using alternative optimization (AO). Specifically, the user scheduling is formulated as a graph coloring problem by iteratively updating an undirected graph based on user requirements, which is then solved using the DSatur algorithm. For the combining weights and power control, the successive convex approximation (SCA) and geometrical programming (GP) are adopted to obtain the sub-optimal solution with lower complexity. Finally, the optimal bandwidth allocation can be achieved by solving the concave problem. Numerical results validate the analytical tightness of the derived bound, especially for large Rician factors, and demonstrate significant performance gains over other benchmarks.
Recollection from Pensieve: Novel View Synthesis via Learning from Uncalibrated Videos
May 19, 2025Currently almost all state-of-the-art novel view synthesis and reconstruction models rely on calibrated cameras or additional geometric priors for training. These prerequisites significantly limit their applicability to massive uncalibrated data. To alleviate this requirement and unlock the potential for self-supervised training on large-scale uncalibrated videos, we propose a novel two-stage strategy to train a view synthesis model from only raw video frames or multi-view images, without providing camera parameters or other priors. In the first stage, we learn to reconstruct the scene implicitly in a latent space without relying on any explicit 3D representation. Specifically, we predict per-frame latent camera and scene context features, and employ a view synthesis model as a proxy for explicit rendering. This pretraining stage substantially reduces the optimization complexity and encourages the network to learn the underlying 3D consistency in a self-supervised manner. The learned latent camera and implicit scene representation have a large gap compared with the real 3D world. To reduce this gap, we introduce the second stage training by explicitly predicting 3D Gaussian primitives. We additionally apply explicit Gaussian Splatting rendering loss and depth projection loss to align the learned latent representations with physically grounded 3D geometry. In this way, Stage 1 provides a strong initialization and Stage 2 enforces 3D consistency - the two stages are complementary and mutually beneficial. Extensive experiments demonstrate the effectiveness of our approach, achieving high-quality novel view synthesis and accurate camera pose estimation, compared to methods that employ supervision with calibration, pose, or depth information. The code is available at https://github.com/Dwawayu/Pensieve.
PyRoki: A Modular Toolkit for Robot Kinematic Optimization
May 06, 2025



Robot motion can have many goals. Depending on the task, we might optimize for pose error, speed, collision, or similarity to a human demonstration. Motivated by this, we present PyRoki: a modular, extensible, and cross-platform toolkit for solving kinematic optimization problems. PyRoki couples an interface for specifying kinematic variables and costs with an efficient nonlinear least squares optimizer. Unlike existing tools, it is also cross-platform: optimization runs natively on CPU, GPU, and TPU. In this paper, we present (i) the design and implementation of PyRoki, (ii) motion retargeting and planning case studies that highlight the advantages of PyRoki's modularity, and (iii) optimization benchmarking, where PyRoki can be 1.4-1.7x faster and converges to lower errors than cuRobo, an existing GPU-accelerated inverse kinematics library.