 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImperative Learning: A Self-supervised Neural-Symbolic Learning Framework for Robot Autonomy
Jun 23, 2024



Data-driven methods such as reinforcement and imitation learning have achieved remarkable success in robot autonomy. However, their data-centric nature still hinders them from generalizing well to ever-changing environments. Moreover, collecting large datasets for robotic tasks is often impractical and expensive. To overcome these challenges, we introduce a new self-supervised neural-symbolic (NeSy) computational framework, imperative learning (IL), for robot autonomy, leveraging the generalization abilities of symbolic reasoning. The framework of IL consists of three primary components: a neural module, a reasoning engine, and a memory system. We formulate IL as a special bilevel optimization (BLO), which enables reciprocal learning over the three modules. This overcomes the label-intensive obstacles associated with data-driven approaches and takes advantage of symbolic reasoning concerning logical reasoning, physical principles, geometric analysis, etc. We discuss several optimization techniques for IL and verify their effectiveness in five distinct robot autonomy tasks including path planning, rule induction, optimal control, visual odometry, and multi-robot routing. Through various experiments, we show that IL can significantly enhance robot autonomy capabilities and we anticipate that it will catalyze further research across diverse domains.
M3GIA: A Cognition Inspired Multilingual and Multimodal General Intelligence Ability Benchmark
Jun 08, 2024As recent multi-modality large language models (MLLMs) have shown formidable proficiency on various complex tasks, there has been increasing attention on debating whether these models could eventually mirror human intelligence. However, existing benchmarks mainly focus on evaluating solely on task performance, such as the accuracy of identifying the attribute of an object. Combining well-developed cognitive science to understand the intelligence of MLLMs beyond superficial achievements remains largely unexplored. To this end, we introduce the first cognitive-driven multi-lingual and multi-modal benchmark to evaluate the general intelligence ability of MLLMs, dubbed M3GIA. Specifically, we identify five key cognitive factors based on the well-recognized Cattell-Horn-Carrol (CHC) model of intelligence and propose a novel evaluation metric. In addition, since most MLLMs are trained to perform in different languages, a natural question arises: is language a key factor influencing the cognitive ability of MLLMs? As such, we go beyond English to encompass other languages based on their popularity, including Chinese, French, Spanish, Portuguese and Korean, to construct our M3GIA. We make sure all the data relevant to the cultural backgrounds are collected from their native context to avoid English-centric bias. We collected a significant corpus of data from human participants, revealing that the most advanced MLLM reaches the lower boundary of human intelligence in English. Yet, there remains a pronounced disparity in the other five languages assessed. We also reveals an interesting winner takes all phenomenon that are aligned with the discovery in cognitive studies. Our benchmark will be open-sourced, with the aspiration of facilitating the enhancement of cognitive capabilities in MLLMs.
PhysORD: A Neuro-Symbolic Approach for Physics-infused Motion Prediction in Off-road Driving
Apr 02, 2024Motion prediction is critical for autonomous off-road driving, however, it presents significantly more challenges than on-road driving because of the complex interaction between the vehicle and the terrain. Traditional physics-based approaches encounter difficulties in accurately modeling dynamic systems and external disturbance. In contrast, data-driven neural networks require extensive datasets and struggle with explicitly capturing the fundamental physical laws, which can easily lead to poor generalization. By merging the advantages of both methods, neuro-symbolic approaches present a promising direction. These methods embed physical laws into neural models, potentially significantly improving generalization capabilities. However, no prior works were evaluated in real-world settings for off-road driving. To bridge this gap, we present PhysORD, a neural-symbolic approach integrating the conservation law, i.e., the Euler-Lagrange equation, into data-driven neural models for motion prediction in off-road driving. Our experiments showed that PhysORD can accurately predict vehicle motion and tolerate external disturbance by modeling uncertainties. It outperforms existing methods both in accuracy and efficiency and demonstrates data-efficient learning and generalization ability in long-term prediction.
DP-CRE: Continual Relation Extraction via Decoupled Contrastive Learning and Memory Structure Preservation
Mar 05, 2024Continuous Relation Extraction (CRE) aims to incrementally learn relation knowledge from a non-stationary stream of data. Since the introduction of new relational tasks can overshadow previously learned information, catastrophic forgetting becomes a significant challenge in this domain. Current replay-based training paradigms prioritize all data uniformly and train memory samples through multiple rounds, which would result in overfitting old tasks and pronounced bias towards new tasks because of the imbalances of the replay set. To handle the problem, we introduce the DecouPled CRE (DP-CRE) framework that decouples the process of prior information preservation and new knowledge acquisition. This framework examines alterations in the embedding space as new relation classes emerge, distinctly managing the preservation and acquisition of knowledge. Extensive experiments show that DP-CRE significantly outperforms other CRE baselines across two datasets.
PyPose v0.6: The Imperative Programming Interface for Robotics
Sep 22, 2023



PyPose is an open-source library for robot learning. It combines a learning-based approach with physics-based optimization, which enables seamless end-to-end robot learning. It has been used in many tasks due to its meticulously designed application programming interface (API) and efficient implementation. From its initial launch in early 2022, PyPose has experienced significant enhancements, incorporating a wide variety of new features into its platform. To satisfy the growing demand for understanding and utilizing the library and reduce the learning curve of new users, we present the fundamental design principle of the imperative programming interface, and showcase the flexible usage of diverse functionalities and modules using an extremely simple Dubins car example. We also demonstrate that the PyPose can be easily used to navigate a real quadruped robot with a few lines of code.
Interdisciplinary Fairness in Imbalanced Research Proposal Topic Inference: A Hierarchical Transformer-based Method with Selective Interpolation
Sep 11, 2023



The objective of topic inference in research proposals aims to obtain the most suitable disciplinary division from the discipline system defined by a funding agency. The agency will subsequently find appropriate peer review experts from their database based on this division. Automated topic inference can reduce human errors caused by manual topic filling, bridge the knowledge gap between funding agencies and project applicants, and improve system efficiency. Existing methods focus on modeling this as a hierarchical multi-label classification problem, using generative models to iteratively infer the most appropriate topic information. However, these methods overlook the gap in scale between interdisciplinary research proposals and non-interdisciplinary ones, leading to an unjust phenomenon where the automated inference system categorizes interdisciplinary proposals as non-interdisciplinary, causing unfairness during the expert assignment. How can we address this data imbalance issue under a complex discipline system and hence resolve this unfairness? In this paper, we implement a topic label inference system based on a Transformer encoder-decoder architecture. Furthermore, we utilize interpolation techniques to create a series of pseudo-interdisciplinary proposals from non-interdisciplinary ones during training based on non-parametric indicators such as cross-topic probabilities and topic occurrence probabilities. This approach aims to reduce the bias of the system during model training. Finally, we conduct extensive experiments on a real-world dataset to verify the effectiveness of the proposed method. The experimental results demonstrate that our training strategy can significantly mitigate the unfairness generated in the topic inference task.
NEEDED: Introducing Hierarchical Transformer to Eye Diseases Diagnosis
Dec 31, 2022With the development of natural language processing techniques(NLP), automatic diagnosis of eye diseases using ophthalmology electronic medical records (OEMR) has become possible. It aims to evaluate the condition of both eyes of a patient respectively, and we formulate it as a particular multi-label classification task in this paper. Although there are a few related studies in other diseases, automatic diagnosis of eye diseases exhibits unique characteristics. First, descriptions of both eyes are mixed up in OEMR documents, with both free text and templated asymptomatic descriptions, resulting in sparsity and clutter of information. Second, OEMR documents contain multiple parts of descriptions and have long document lengths. Third, it is critical to provide explainability to the disease diagnosis model. To overcome those challenges, we present an effective automatic eye disease diagnosis framework, NEEDED. In this framework, a preprocessing module is integrated to improve the density and quality of information. Then, we design a hierarchical transformer structure for learning the contextualized representations of each sentence in the OEMR document. For the diagnosis part, we propose an attention-based predictor that enables traceable diagnosis by obtaining disease-specific information. Experiments on the real dataset and comparison with several baseline models show the advantage and explainability of our framework.
Graph Soft-Contrastive Learning via Neighborhood Ranking
Sep 28, 2022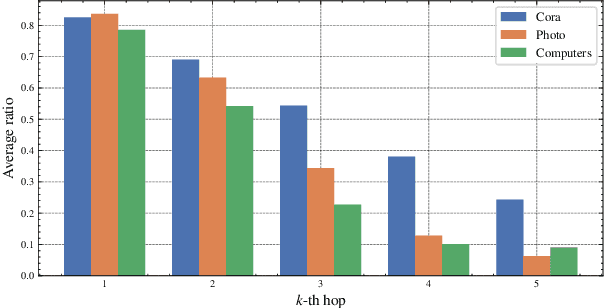
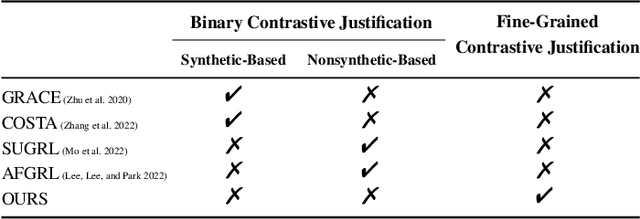
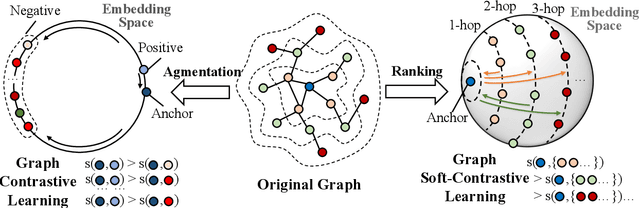
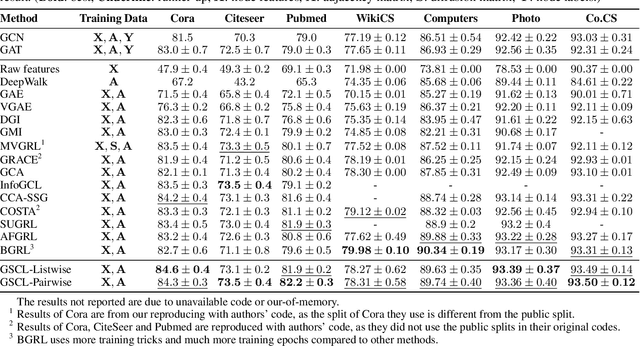
Graph contrastive learning (GCL) has been an emerging solution for graph self-supervised learning. The core principle of GCL is to reduce the distance between samples in the positive view, but increase the distance between samples in the negative view. While achieving promising performances, current GCL methods still suffer from two limitations: (1) uncontrollable validity of augmentation, that graph perturbation may produce invalid views against semantics and feature-topology correspondence of graph data; and (2) unreliable binary contrastive justification, that the positiveness and negativeness of the constructed views are difficult to be determined for non-euclidean graph data. To tackle the above limitations, we propose a new contrastive learning paradigm for graphs, namely Graph Soft-Contrastive Learning (GSCL), that conducts contrastive learning in a finer-granularity via ranking neighborhoods without any augmentations and binary contrastive justification. GSCL is built upon the fundamental assumption of graph proximity that connected neighbors are more similar than far-distant nodes. Specifically, we develop pair-wise and list-wise Gated Ranking infoNCE Loss functions to preserve the relative ranking relationship in the neighborhood. Moreover, as the neighborhood size exponentially expands with more hops considered, we propose neighborhood sampling strategies to improve learning efficiency. The extensive experimental results show that our proposed GSCL can consistently achieve state-of-the-art performances on various public datasets with comparable practical complexity to GCL.
Hierarchical MixUp Multi-label Classification with Imbalanced Interdisciplinary Research Proposals
Sep 28, 2022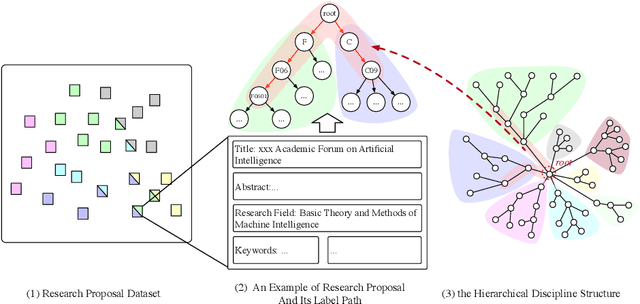
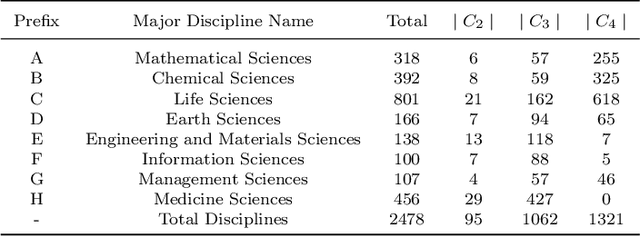
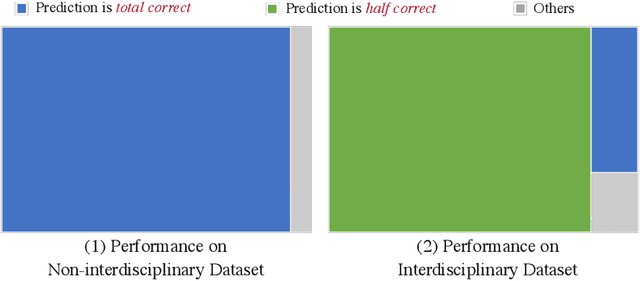
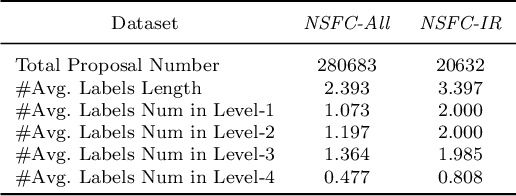
Funding agencies are largely relied on a topic matching between domain experts and research proposals to assign proposal reviewers. As proposals are increasingly interdisciplinary, it is challenging to profile the interdisciplinary nature of a proposal, and, thereafter, find expert reviewers with an appropriate set of expertise. An essential step in solving this challenge is to accurately model and classify the interdisciplinary labels of a proposal. Existing methodological and application-related literature, such as textual classification and proposal classification, are insufficient in jointly addressing the three key unique issues introduced by interdisciplinary proposal data: 1) the hierarchical structure of discipline labels of a proposal from coarse-grain to fine-grain, e.g., from information science to AI to fundamentals of AI. 2) the heterogeneous semantics of various main textual parts that play different roles in a proposal; 3) the number of proposals is imbalanced between non-interdisciplinary and interdisciplinary research. Can we simultaneously address the three issues in understanding the proposal's interdisciplinary nature? In response to this question, we propose a hierarchical mixup multiple-label classification framework, which we called H-MixUp. H-MixUp leverages a transformer-based semantic information extractor and a GCN-based interdisciplinary knowledge extractor for the first and second issues. H-MixUp develops a fused training method of Wold-level MixUp, Word-level CutMix, Manifold MixUp, and Document-level MixUp to address the third issue.
Hierarchical Interdisciplinary Topic Detection Model for Research Proposal Classification
Sep 16, 2022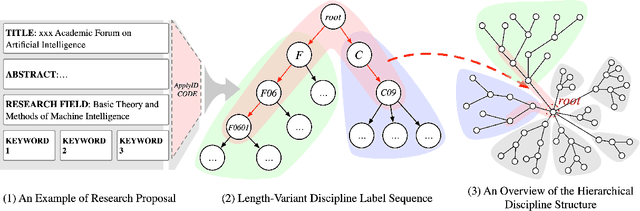
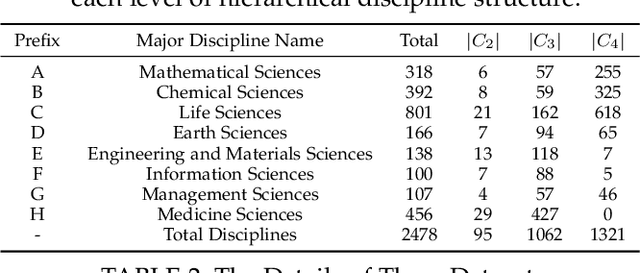
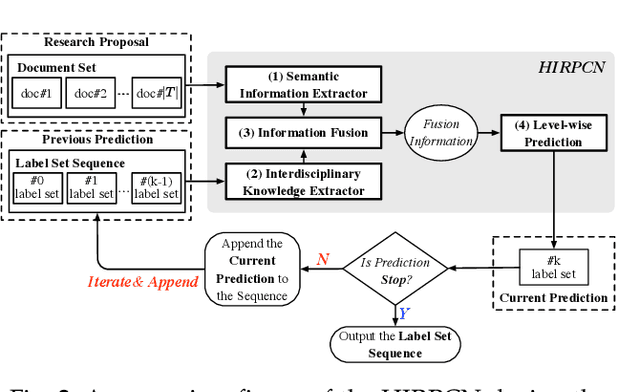
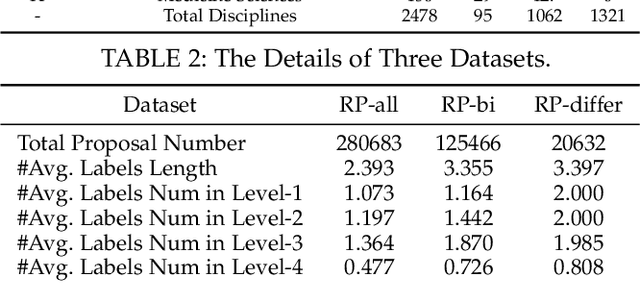
The peer merit review of research proposals has been the major mechanism for deciding grant awards. However, research proposals have become increasingly interdisciplinary. It has been a longstanding challenge to assign interdisciplinary proposals to appropriate reviewers, so proposals are fairly evaluated. One of the critical steps in reviewer assignment is to generate accurate interdisciplinary topic labels for proposal-reviewer matching. Existing systems mainly collect topic labels manually generated by principal investigators. However, such human-reported labels can be non-accurate, incomplete, labor intensive, and time costly. What role can AI play in developing a fair and precise proposal reviewer assignment system? In this study, we collaborate with the National Science Foundation of China to address the task of automated interdisciplinary topic path detection. For this purpose, we develop a deep Hierarchical Interdisciplinary Research Proposal Classification Network (HIRPCN). Specifically, we first propose a hierarchical transformer to extract the textual semantic information of proposals. We then design an interdisciplinary graph and leverage GNNs for learning representations of each discipline in order to extract interdisciplinary knowledge. After extracting the semantic and interdisciplinary knowledge, we design a level-wise prediction component to fuse the two types of knowledge representations and detect interdisciplinary topic paths for each proposal. We conduct extensive experiments and expert evaluations on three real-world datasets to demonstrate the effectiveness of our proposed model.