 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFOCAL-Attention for Heterogeneous Multi-Label Prediction
Apr 21, 2026Heterogeneous graphs have attracted increasing attention for modeling multi-typed entities and relations in complex real-world systems. Multi-label node classification on heterogeneous graphs is challenging due to structural heterogeneity and the need to learn shared representations across multiple labels. Existing methods typically adopt either flexible attention mechanisms or meta-path constrained anchoring, but in heterogeneous multi-label prediction they often suffer from semantic dilution or coverage constraint. Both issues are further amplified under multi-label supervision. We present a theoretical analysis showing that as heterogeneous neighborhoods expand, the attention mass allocated to task-critical (primary) neighborhoods diminishes, and that meta-path constrained aggregation exhibits a dilemma: too few meta-paths intensify coverage constraint, while too many re-introduce dilution. To resolve this coverage-anchoring conflict, we propose FOCAL: Fusion Of Coverage and Anchoring Learning, with two components: coverage-oriented attention (COA) for flexible, unconstrained heterogeneous context aggregation, and anchoring-oriented attention (AOA) that restricts aggregation to meta-path-induced primary semantics. Our theoretical analysis and experimental results further indicates that FOCAL has a better performance than other state-of-the-art methods.
Beyond Paper-to-Paper: Structured Profiling and Rubric Scoring for Paper-Reviewer Matching
Apr 07, 2026As conference submission volumes continue to grow, accurately recommending suitable reviewers has become a challenge. Most existing methods follow a ``Paper-to-Paper'' matching paradigm, implicitly representing a reviewer by their publication history. However, effective reviewer matching requires capturing multi-dimensional expertise, and textual similarity to past papers alone is often insufficient. To address this gap, we propose P2R, a training-free framework that shifts from implicit paper-to-paper matching to explicit profile-based matching. P2R uses general-purpose LLMs to construct structured profiles for both submissions and reviewers, disentangling them into Topics, Methodologies, and Applications. Building on these profiles, P2R adopts a coarse-to-fine pipeline to balance efficiency and depth. It first performs hybrid retrieval that combines semantic and aspect-level signals to form a high-recall candidate pool, and then applies an LLM-based committee to evaluate candidates under strict rubrics, integrating both multi-dimensional expert views and a holistic Area Chair perspective. Experiments on NeurIPS, SIGIR, and SciRepEval show that P2R consistently outperforms state-of-the-art baselines. Ablation studies further verify the necessity of each component. Overall, P2R highlights the value of explicit, structured expertise modeling and offers practical guidance for applying LLMs to reviewer matching.
DP-CRE: Continual Relation Extraction via Decoupled Contrastive Learning and Memory Structure Preservation
Mar 05, 2024Continuous Relation Extraction (CRE) aims to incrementally learn relation knowledge from a non-stationary stream of data. Since the introduction of new relational tasks can overshadow previously learned information, catastrophic forgetting becomes a significant challenge in this domain. Current replay-based training paradigms prioritize all data uniformly and train memory samples through multiple rounds, which would result in overfitting old tasks and pronounced bias towards new tasks because of the imbalances of the replay set. To handle the problem, we introduce the DecouPled CRE (DP-CRE) framework that decouples the process of prior information preservation and new knowledge acquisition. This framework examines alterations in the embedding space as new relation classes emerge, distinctly managing the preservation and acquisition of knowledge. Extensive experiments show that DP-CRE significantly outperforms other CRE baselines across two datasets.
Handwritten Chinese Character Recognition by Convolutional Neural Network and Similarity Ranking
Aug 30, 2019

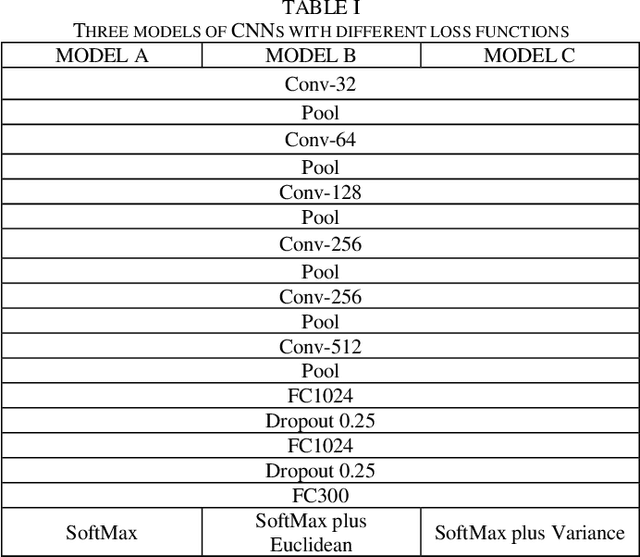
Convolution Neural Networks (CNN) have recently achieved state-of-the art performance on handwritten Chinese character recognition (HCCR). However, most of CNN models employ the SoftMax activation function and minimize cross entropy loss, which may cause loss of inter-class information. To cope with this problem, we propose to combine cross entropy with similarity ranking function and use it as loss function. The experiments results show that the combination loss functions produce higher accuracy in HCCR. This report briefly reviews cross entropy loss function, a typical similarity ranking function: Euclidean distance, and also propose a new similarity ranking function: Average variance similarity. Experiments are done to compare the performances of a CNN model with three different loss functions. In the end, SoftMax cross entropy with Average variance similarity produce the highest accuracy on handwritten Chinese characters recognition.