 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePSVMA+: Exploring Multi-granularity Semantic-visual Adaption for Generalized Zero-shot Learning
Oct 15, 2024



Generalized zero-shot learning (GZSL) endeavors to identify the unseen categories using knowledge from the seen domain, necessitating the intrinsic interactions between the visual features and attribute semantic features. However, GZSL suffers from insufficient visual-semantic correspondences due to the attribute diversity and instance diversity. Attribute diversity refers to varying semantic granularity in attribute descriptions, ranging from low-level (specific, directly observable) to high-level (abstract, highly generic) characteristics. This diversity challenges the collection of adequate visual cues for attributes under a uni-granularity. Additionally, diverse visual instances corresponding to the same sharing attributes introduce semantic ambiguity, leading to vague visual patterns. To tackle these problems, we propose a multi-granularity progressive semantic-visual mutual adaption (PSVMA+) network, where sufficient visual elements across granularity levels can be gathered to remedy the granularity inconsistency. PSVMA+ explores semantic-visual interactions at different granularity levels, enabling awareness of multi-granularity in both visual and semantic elements. At each granularity level, the dual semantic-visual transformer module (DSVTM) recasts the sharing attributes into instance-centric attributes and aggregates the semantic-related visual regions, thereby learning unambiguous visual features to accommodate various instances. Given the diverse contributions of different granularities, PSVMA+ employs selective cross-granularity learning to leverage knowledge from reliable granularities and adaptively fuses multi-granularity features for comprehensive representations. Experimental results demonstrate that PSVMA+ consistently outperforms state-of-the-art methods.
SeeClear: Semantic Distillation Enhances Pixel Condensation for Video Super-Resolution
Oct 08, 2024Diffusion-based Video Super-Resolution (VSR) is renowned for generating perceptually realistic videos, yet it grapples with maintaining detail consistency across frames due to stochastic fluctuations. The traditional approach of pixel-level alignment is ineffective for diffusion-processed frames because of iterative disruptions. To overcome this, we introduce SeeClear--a novel VSR framework leveraging conditional video generation, orchestrated by instance-centric and channel-wise semantic controls. This framework integrates a Semantic Distiller and a Pixel Condenser, which synergize to extract and upscale semantic details from low-resolution frames. The Instance-Centric Alignment Module (InCAM) utilizes video-clip-wise tokens to dynamically relate pixels within and across frames, enhancing coherency. Additionally, the Channel-wise Texture Aggregation Memory (CaTeGory) infuses extrinsic knowledge, capitalizing on long-standing semantic textures. Our method also innovates the blurring diffusion process with the ResShift mechanism, finely balancing between sharpness and diffusion effects. Comprehensive experiments confirm our framework's advantage over state-of-the-art diffusion-based VSR techniques. The code is available: https://github.com/Tang1705/SeeClear-NeurIPS24.
Collapsed Language Models Promote Fairness
Oct 06, 2024



To mitigate societal biases implicitly encoded in recent successful pretrained language models, a diverse array of approaches have been proposed to encourage model fairness, focusing on prompting, data augmentation, regularized fine-tuning, and more. Despite the development, it is nontrivial to reach a principled understanding of fairness and an effective algorithm that can consistently debias language models. In this work, by rigorous evaluations of Neural Collapse -- a learning phenomenon happen in last-layer representations and classifiers in deep networks -- on fairness-related words, we find that debiased language models exhibit collapsed alignment between token representations and word embeddings. More importantly, this observation inspires us to design a principled fine-tuning method that can effectively improve fairness in a wide range of debiasing methods, while still preserving the performance of language models on standard natural language understanding tasks. We attach our code at https://anonymous.4open.science/r/Fairness_NC-457E .
Str-L Pose: Integrating Point and Structured Line for Relative Pose Estimation in Dual-Graph
Aug 28, 2024



Relative pose estimation is crucial for various computer vision applications, including Robotic and Autonomous Driving. Current methods primarily depend on selecting and matching feature points prone to incorrect matches, leading to poor performance. Consequently, relying solely on point-matching relationships for pose estimation is a huge challenge. To overcome these limitations, we propose a Geometric Correspondence Graph neural network that integrates point features with extra structured line segments. This integration of matched points and line segments further exploits the geometry constraints and enhances model performance across different environments. We employ the Dual-Graph module and Feature Weighted Fusion Module to aggregate geometric and visual features effectively, facilitating complex scene understanding. We demonstrate our approach through extensive experiments on the DeMoN and KITTI Odometry datasets. The results show that our method is competitive with state-of-the-art techniques.
Fire-Flyer AI-HPC: A Cost-Effective Software-Hardware Co-Design for Deep Learning
Aug 26, 2024



The rapid progress in Deep Learning (DL) and Large Language Models (LLMs) has exponentially increased demands of computational power and bandwidth. This, combined with the high costs of faster computing chips and interconnects, has significantly inflated High Performance Computing (HPC) construction costs. To address these challenges, we introduce the Fire-Flyer AI-HPC architecture, a synergistic hardware-software co-design framework and its best practices. For DL training, we deployed the Fire-Flyer 2 with 10,000 PCIe A100 GPUs, achieved performance approximating the DGX-A100 while reducing costs by half and energy consumption by 40%. We specifically engineered HFReduce to accelerate allreduce communication and implemented numerous measures to keep our Computation-Storage Integrated Network congestion-free. Through our software stack, including HaiScale, 3FS, and HAI-Platform, we achieved substantial scalability by overlapping computation and communication. Our system-oriented experience from DL training provides valuable insights to drive future advancements in AI-HPC.
C2P-CLIP: Injecting Category Common Prompt in CLIP to Enhance Generalization in Deepfake Detection
Aug 19, 2024



This work focuses on AIGC detection to develop universal detectors capable of identifying various types of forgery images. Recent studies have found large pre-trained models, such as CLIP, are effective for generalizable deepfake detection along with linear classifiers. However, two critical issues remain unresolved: 1) understanding why CLIP features are effective on deepfake detection through a linear classifier; and 2) exploring the detection potential of CLIP. In this study, we delve into the underlying mechanisms of CLIP's detection capabilities by decoding its detection features into text and performing word frequency analysis. Our finding indicates that CLIP detects deepfakes by recognizing similar concepts (Fig. \ref{fig:fig1} a). Building on this insight, we introduce Category Common Prompt CLIP, called C2P-CLIP, which integrates the category common prompt into the text encoder to inject category-related concepts into the image encoder, thereby enhancing detection performance (Fig. \ref{fig:fig1} b). Our method achieves a 12.41\% improvement in detection accuracy compared to the original CLIP, without introducing additional parameters during testing. Comprehensive experiments conducted on two widely-used datasets, encompassing 20 generation models, validate the efficacy of the proposed method, demonstrating state-of-the-art performance. The code is available at \url{https://github.com/chuangchuangtan/C2P-CLIP-DeepfakeDetection}
DreamLCM: Towards High-Quality Text-to-3D Generation via Latent Consistency Model
Aug 06, 2024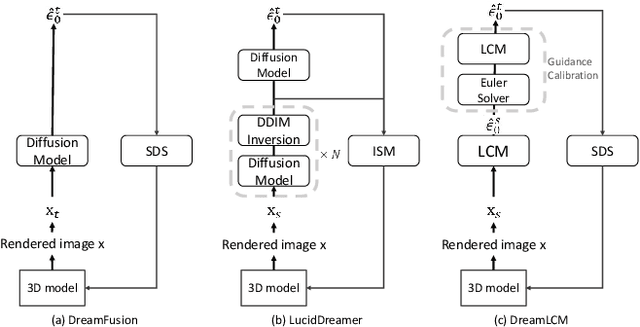
Recently, the text-to-3D task has developed rapidly due to the appearance of the SDS method. However, the SDS method always generates 3D objects with poor quality due to the over-smooth issue. This issue is attributed to two factors: 1) the DDPM single-step inference produces poor guidance gradients; 2) the randomness from the input noises and timesteps averages the details of the 3D contents.In this paper, to address the issue, we propose DreamLCM which incorporates the Latent Consistency Model (LCM). DreamLCM leverages the powerful image generation capabilities inherent in LCM, enabling generating consistent and high-quality guidance, i.e., predicted noises or images. Powered by the improved guidance, the proposed method can provide accurate and detailed gradients to optimize the target 3D models.In addition, we propose two strategies to enhance the generation quality further. Firstly, we propose a guidance calibration strategy, utilizing Euler Solver to calibrate the guidance distribution to accelerate 3D models to converge. Secondly, we propose a dual timestep strategy, increasing the consistency of guidance and optimizing 3D models from geometry to appearance in DreamLCM. Experiments show that DreamLCM achieves state-of-the-art results in both generation quality and training efficiency. The code is available at https://github.com/1YimingZhong/DreamLCM.
Collaborative Vision-Text Representation Optimizing for Open-Vocabulary Segmentation
Aug 01, 2024



Pre-trained vision-language models, e.g. CLIP, have been increasingly used to address the challenging Open-Vocabulary Segmentation (OVS) task, benefiting from their well-aligned vision-text embedding space. Typical solutions involve either freezing CLIP during training to unilaterally maintain its zero-shot capability, or fine-tuning CLIP vision encoder to achieve perceptual sensitivity to local regions. However, few of them incorporate vision-text collaborative optimization. Based on this, we propose the Content-Dependent Transfer to adaptively enhance each text embedding by interacting with the input image, which presents a parameter-efficient way to optimize the text representation. Besides, we additionally introduce a Representation Compensation strategy, reviewing the original CLIP-V representation as compensation to maintain the zero-shot capability of CLIP. In this way, the vision and text representation of CLIP are optimized collaboratively, enhancing the alignment of the vision-text feature space. To the best of our knowledge, we are the first to establish the collaborative vision-text optimizing mechanism within the OVS field. Extensive experiments demonstrate our method achieves superior performance on popular OVS benchmarks. In open-vocabulary semantic segmentation, our method outperforms the previous state-of-the-art approaches by +0.5, +2.3, +3.4, +0.4 and +1.1 mIoU, respectively on A-847, A-150, PC-459, PC-59 and PAS-20. Furthermore, in a panoptic setting on ADE20K, we achieve the performance of 27.1 PQ, 73.5 SQ, and 32.9 RQ. Code will be available at https://github.com/jiaosiyu1999/MAFT-Plus.git .
ROS-LLM: A ROS framework for embodied AI with task feedback and structured reasoning
Jun 28, 2024



We present a framework for intuitive robot programming by non-experts, leveraging natural language prompts and contextual information from the Robot Operating System (ROS). Our system integrates large language models (LLMs), enabling non-experts to articulate task requirements to the system through a chat interface. Key features of the framework include: integration of ROS with an AI agent connected to a plethora of open-source and commercial LLMs, automatic extraction of a behavior from the LLM output and execution of ROS actions/services, support for three behavior modes (sequence, behavior tree, state machine), imitation learning for adding new robot actions to the library of possible actions, and LLM reflection via human and environment feedback. Extensive experiments validate the framework, showcasing robustness, scalability, and versatility in diverse scenarios, including long-horizon tasks, tabletop rearrangements, and remote supervisory control. To facilitate the adoption of our framework and support the reproduction of our results, we have made our code open-source. You can access it at: https://github.com/huawei-noah/HEBO/tree/master/ROSLLM.
FlexCare: Leveraging Cross-Task Synergy for Flexible Multimodal Healthcare Prediction
Jun 17, 2024



Multimodal electronic health record (EHR) data can offer a holistic assessment of a patient's health status, supporting various predictive healthcare tasks. Recently, several studies have embraced the multitask learning approach in the healthcare domain, exploiting the inherent correlations among clinical tasks to predict multiple outcomes simultaneously. However, existing methods necessitate samples to possess complete labels for all tasks, which places heavy demands on the data and restricts the flexibility of the model. Meanwhile, within a multitask framework with multimodal inputs, how to comprehensively consider the information disparity among modalities and among tasks still remains a challenging problem. To tackle these issues, a unified healthcare prediction model, also named by \textbf{FlexCare}, is proposed to flexibly accommodate incomplete multimodal inputs, promoting the adaption to multiple healthcare tasks. The proposed model breaks the conventional paradigm of parallel multitask prediction by decomposing it into a series of asynchronous single-task prediction. Specifically, a task-agnostic multimodal information extraction module is presented to capture decorrelated representations of diverse intra- and inter-modality patterns. Taking full account of the information disparities between different modalities and different tasks, we present a task-guided hierarchical multimodal fusion module that integrates the refined modality-level representations into an individual patient-level representation. Experimental results on multiple tasks from MIMIC-IV/MIMIC-CXR/MIMIC-NOTE datasets demonstrate the effectiveness of the proposed method. Additionally, further analysis underscores the feasibility and potential of employing such a multitask strategy in the healthcare domain. The source code is available at https://github.com/mhxu1998/FlexCare.