 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePFA: Privacy-preserving Federated Adaptation for Effective Model Personalization
Mar 08, 2021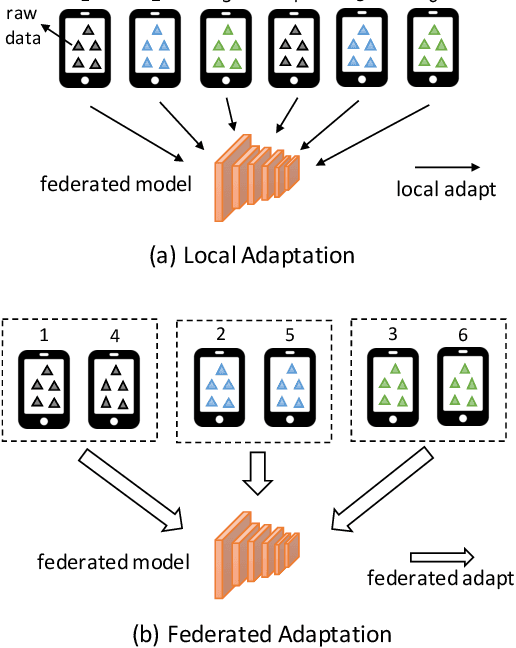

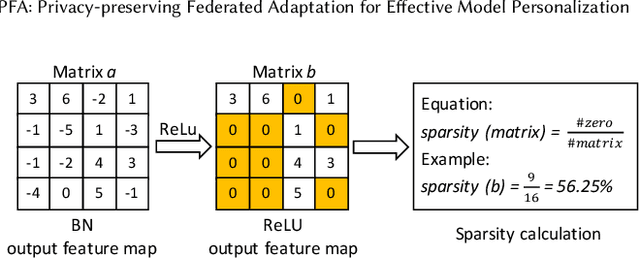
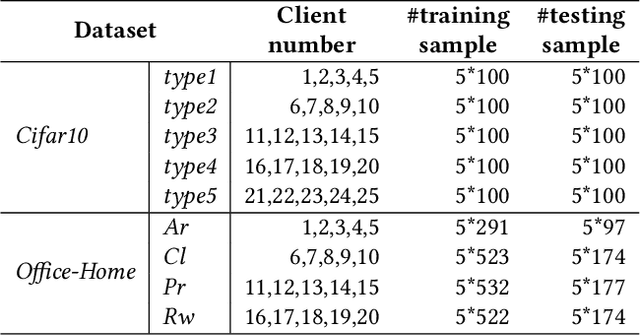
Federated learning (FL) has become a prevalent distributed machine learning paradigm with improved privacy. After learning, the resulting federated model should be further personalized to each different client. While several methods have been proposed to achieve personalization, they are typically limited to a single local device, which may incur bias or overfitting since data in a single device is extremely limited. In this paper, we attempt to realize personalization beyond a single client. The motivation is that during FL, there may exist many clients with similar data distribution, and thus the personalization performance could be significantly boosted if these similar clients can cooperate with each other. Inspired by this, this paper introduces a new concept called federated adaptation, targeting at adapting the trained model in a federated manner to achieve better personalization results. However, the key challenge for federated adaptation is that we could not outsource any raw data from the client during adaptation, due to privacy concerns. In this paper, we propose PFA, a framework to accomplish Privacy-preserving Federated Adaptation. PFA leverages the sparsity property of neural networks to generate privacy-preserving representations and uses them to efficiently identify clients with similar data distributions. Based on the grouping results, PFA conducts an FL process in a group-wise way on the federated model to accomplish the adaptation. For evaluation, we manually construct several practical FL datasets based on public datasets in order to simulate both the class-imbalance and background-difference conditions. Extensive experiments on these datasets and popular model architectures demonstrate the effectiveness of PFA, outperforming other state-of-the-art methods by a large margin while ensuring user privacy. We will release our code at: https://github.com/lebyni/PFA.
TransTailor: Pruning the Pre-trained Model for Improved Transfer Learning
Mar 02, 2021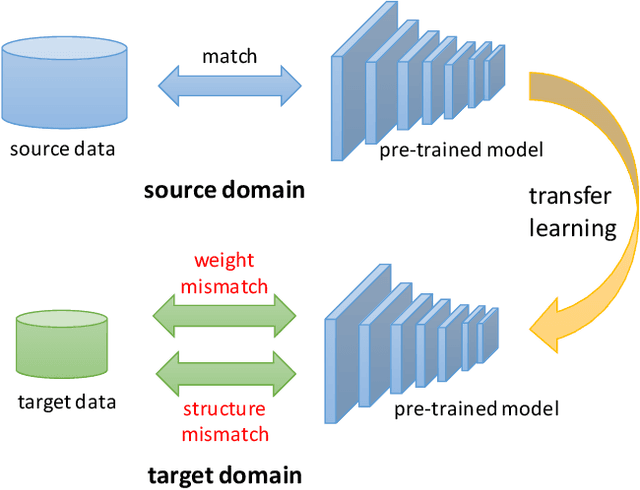
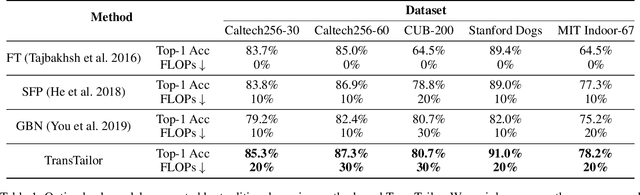
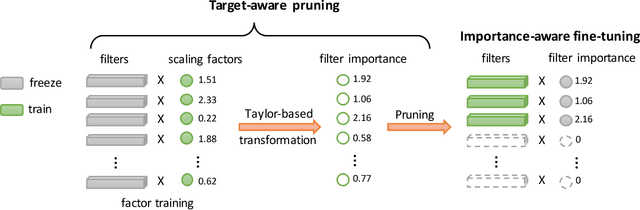
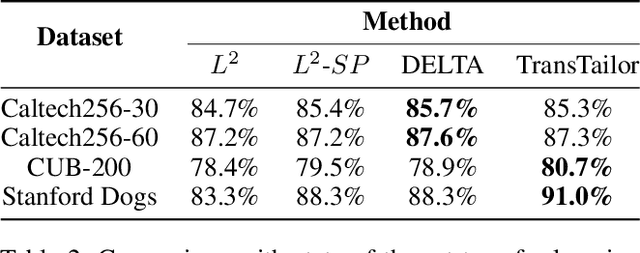
The increasing of pre-trained models has significantly facilitated the performance on limited data tasks with transfer learning. However, progress on transfer learning mainly focuses on optimizing the weights of pre-trained models, which ignores the structure mismatch between the model and the target task. This paper aims to improve the transfer performance from another angle - in addition to tuning the weights, we tune the structure of pre-trained models, in order to better match the target task. To this end, we propose TransTailor, targeting at pruning the pre-trained model for improved transfer learning. Different from traditional pruning pipelines, we prune and fine-tune the pre-trained model according to the target-aware weight importance, generating an optimal sub-model tailored for a specific target task. In this way, we transfer a more suitable sub-structure that can be applied during fine-tuning to benefit the final performance. Extensive experiments on multiple pre-trained models and datasets demonstrate that TransTailor outperforms the traditional pruning methods and achieves competitive or even better performance than other state-of-the-art transfer learning methods while using a smaller model. Notably, on the Stanford Dogs dataset, TransTailor can achieve 2.7% accuracy improvement over other transfer methods with 20% fewer FLOPs.
Neural Delay Differential Equations
Feb 22, 2021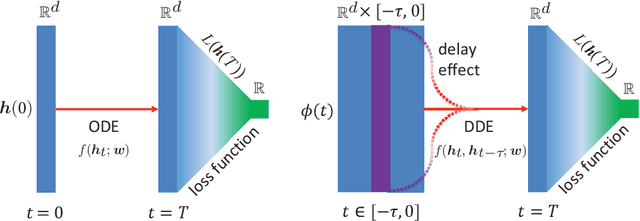
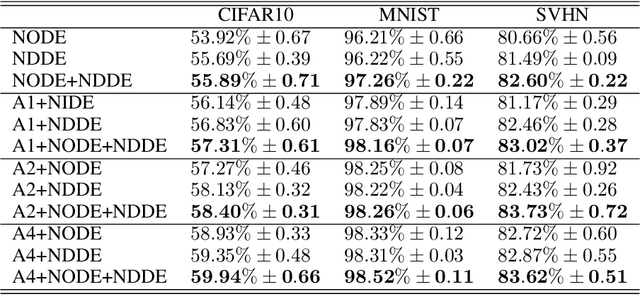
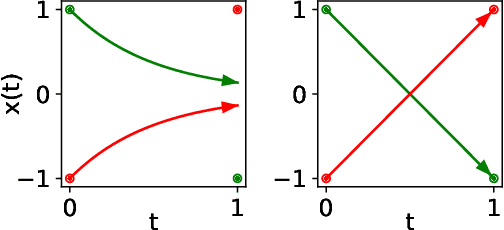
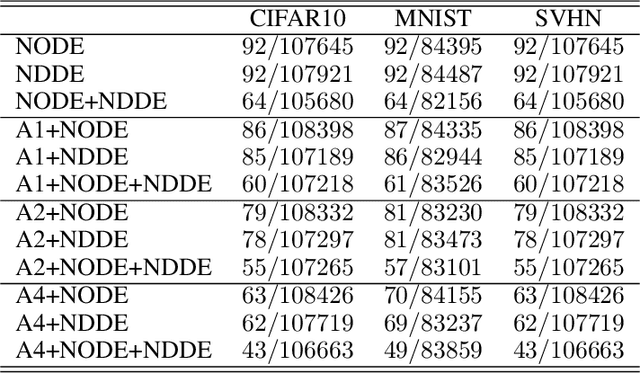
Neural Ordinary Differential Equations (NODEs), a framework of continuous-depth neural networks, have been widely applied, showing exceptional efficacy in coping with some representative datasets. Recently, an augmented framework has been successfully developed for conquering some limitations emergent in application of the original framework. Here we propose a new class of continuous-depth neural networks with delay, named as Neural Delay Differential Equations (NDDEs), and, for computing the corresponding gradients, we use the adjoint sensitivity method to obtain the delayed dynamics of the adjoint. Since the differential equations with delays are usually seen as dynamical systems of infinite dimension possessing more fruitful dynamics, the NDDEs, compared to the NODEs, own a stronger capacity of nonlinear representations. Indeed, we analytically validate that the NDDEs are of universal approximators, and further articulate an extension of the NDDEs, where the initial function of the NDDEs is supposed to satisfy ODEs. More importantly, we use several illustrative examples to demonstrate the outstanding capacities of the NDDEs and the NDDEs with ODEs' initial value. Specifically, (1) we successfully model the delayed dynamics where the trajectories in the lower-dimensional phase space could be mutually intersected, while the traditional NODEs without any argumentation are not directly applicable for such modeling, and (2) we achieve lower loss and higher accuracy not only for the data produced synthetically by complex models but also for the real-world image datasets, i.e., CIFAR10, MNIST, and SVHN. Our results on the NDDEs reveal that appropriately articulating the elements of dynamical systems into the network design is truly beneficial to promoting the network performance.
End-to-End Real-time Catheter Segmentation with Optical Flow-Guided Warping during Endovascular Intervention
Jun 16, 2020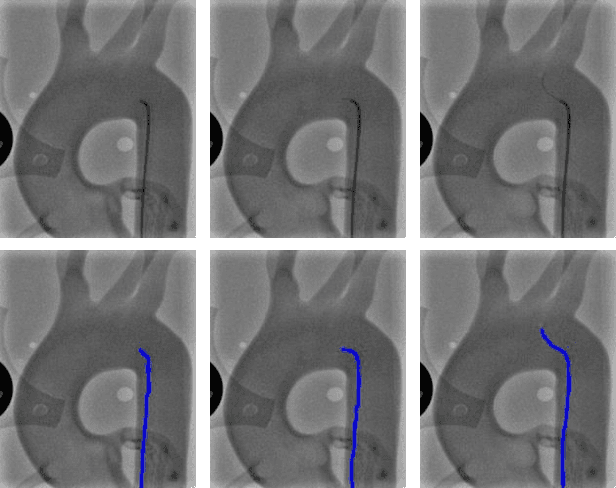

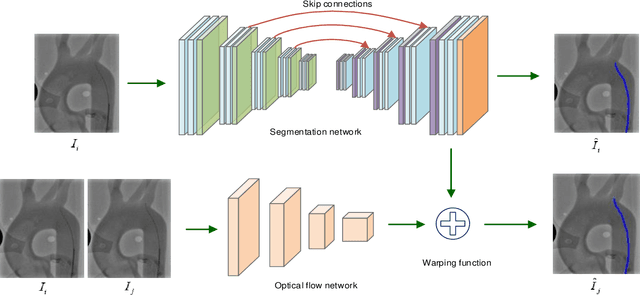
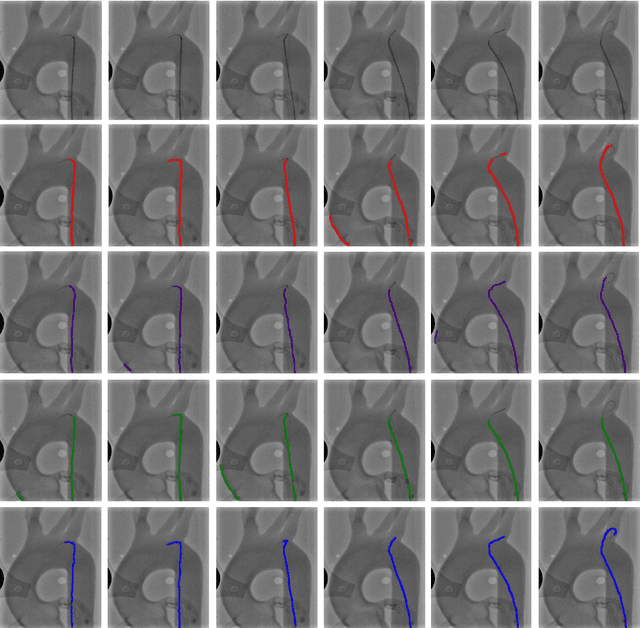
Accurate real-time catheter segmentation is an important pre-requisite for robot-assisted endovascular intervention. Most of the existing learning-based methods for catheter segmentation and tracking are only trained on small-scale datasets or synthetic data due to the difficulties of ground-truth annotation. Furthermore, the temporal continuity in intraoperative imaging sequences is not fully utilised. In this paper, we present FW-Net, an end-to-end and real-time deep learning framework for endovascular intervention. The proposed FW-Net has three modules: a segmentation network with encoder-decoder architecture, a flow network to extract optical flow information, and a novel flow-guided warping function to learn the frame-to-frame temporal continuity. We show that by effectively learning temporal continuity, the network can successfully segment and track the catheters in real-time sequences using only raw ground-truth for training. Detailed validation results confirm that our FW-Net outperforms state-of-the-art techniques while achieving real-time performance.
Adversarial Attacks on Monocular Depth Estimation
Mar 23, 2020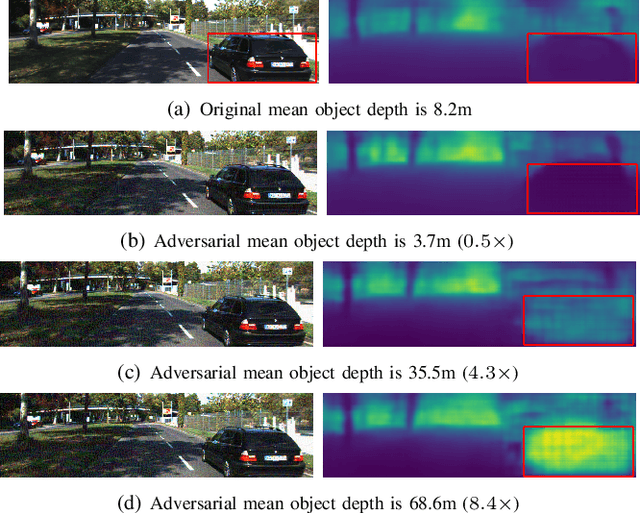

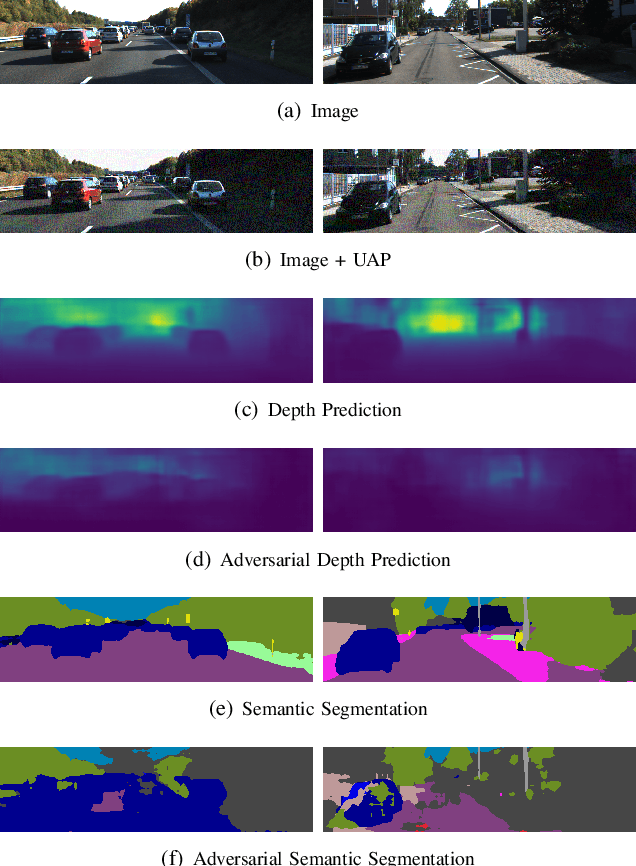
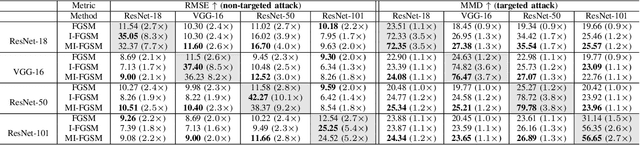
Recent advances of deep learning have brought exceptional performance on many computer vision tasks such as semantic segmentation and depth estimation. However, the vulnerability of deep neural networks towards adversarial examples have caused grave concerns for real-world deployment. In this paper, we present to the best of our knowledge the first systematic study of adversarial attacks on monocular depth estimation, an important task of 3D scene understanding in scenarios such as autonomous driving and robot navigation. In order to understand the impact of adversarial attacks on depth estimation, we first define a taxonomy of different attack scenarios for depth estimation, including non-targeted attacks, targeted attacks and universal attacks. We then adapt several state-of-the-art attack methods for classification on the field of depth estimation. Besides, multi-task attacks are introduced to further improve the attack performance for universal attacks. Experimental results show that it is possible to generate significant errors on depth estimation. In particular, we demonstrate that our methods can conduct targeted attacks on given objects (such as a car), resulting in depth estimation 3-4x away from the ground truth (e.g., from 20m to 80m).
Artificial Intelligence in Surgery
Dec 23, 2019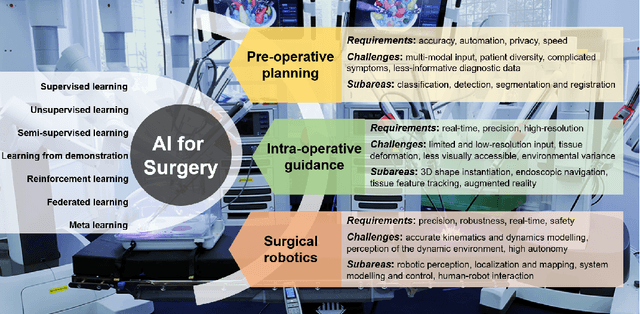
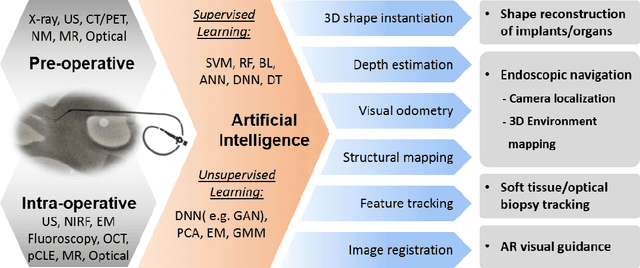
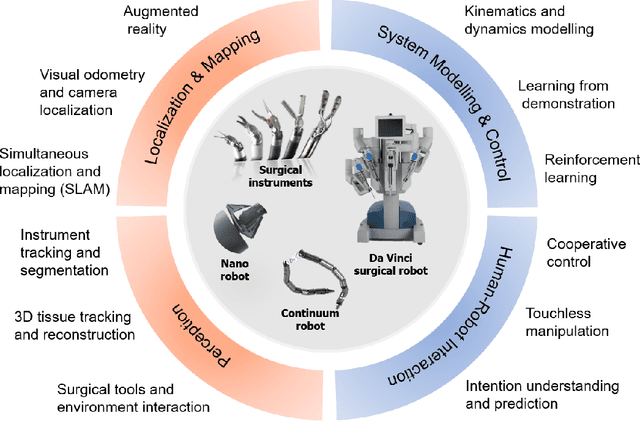
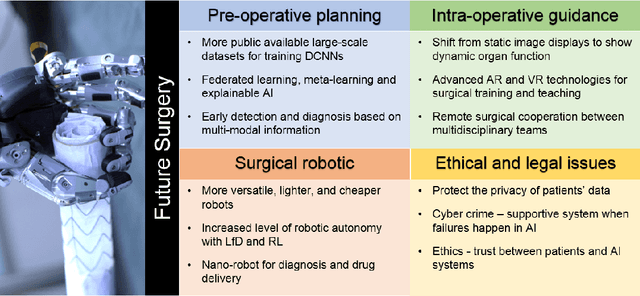
Artificial Intelligence (AI) is gradually changing the practice of surgery with the advanced technological development of imaging, navigation and robotic intervention. In this article, the recent successful and influential applications of AI in surgery are reviewed from pre-operative planning and intra-operative guidance to the integration of surgical robots. We end with summarizing the current state, emerging trends and major challenges in the future development of AI in surgery.
OpenLORIS-Object: A Dataset and Benchmark towards Lifelong Object Recognition
Nov 15, 2019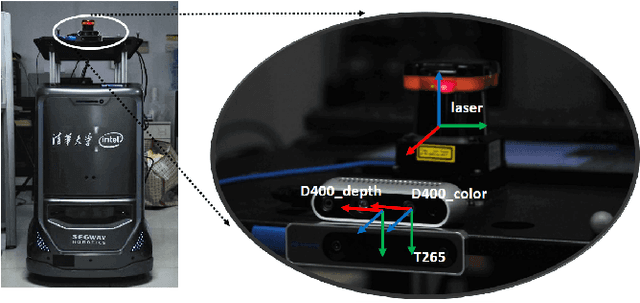


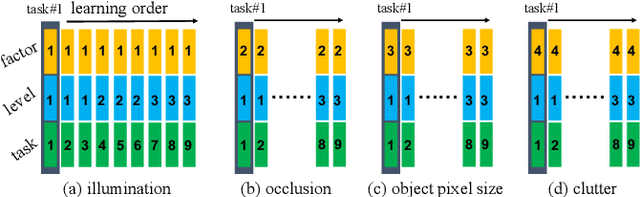
The recent breakthroughs in computer vision have benefited from the availability of large representative datasets (e.g. ImageNet and COCO) for training. Yet, robotic vision poses unique challenges for applying visual algorithms developed from these standard computer vision datasets due to their implicit assumption over non-varying distributions for a fixed set of tasks. Fully retraining models each time a new task becomes available is infeasible due to computational, storage and sometimes privacy issues, while na\"{i}ve incremental strategies have been shown to suffer from catastrophic forgetting. It is crucial for the robots to operate continuously under open-set and detrimental conditions with adaptive visual perceptual systems, where lifelong learning is a fundamental capability. However, very few datasets and benchmarks are available to evaluate and compare emerging techniques. To fill this gap, we provide a new lifelong robotic vision dataset ("OpenLORIS-Object") collected via RGB-D cameras mounted on mobile robots. The dataset embeds the challenges faced by a robot in the real-life application and provides new benchmarks for validating lifelong object recognition algorithms. Moreover, we have provided a testbed of $9$ state-of-the-art lifelong learning algorithms. Each of them involves $48$ tasks with $4$ evaluation metrics over the OpenLORIS-Object dataset. The results demonstrate that the object recognition task in the ever-changing difficulty environments is far from being solved and the bottlenecks are at the forward/backward transfer designs. Our dataset and benchmark are publicly available at \href{https://lifelong-robotic-vision.github.io/dataset/Data_Object-Recognition.html}{\underline{this url}}.
High-speed Railway Fastener Detection and Localization Method based on convolutional neural network
Jul 31, 2019


Railway transportation is the artery of China's national economy and plays an important role in the development of today's society. Due to the late start of China's railway security inspection technology, the current railway security inspection tasks mainly rely on manual inspection, but the manual inspection efficiency is low, and a lot of manpower and material resources are needed. In this paper, we establish a steel rail fastener detection image dataset, which contains 4,000 rail fastener pictures about 4 types. We use the regional suggestion network to generate the region of interest, extracts the features using the convolutional neural network, and fuses the classifier into the detection network. With online hard sample mining to improve the accuracy of the model, we optimize the Faster RCNN detection framework by reducing the number of regions of interest. Finally, the model accuracy reaches 99% and the speed reaches 35FPS in the deployment environment of TITAN X GPU.
Highly Efficient Follicular Segmentation in Thyroid Cytopathological Whole Slide Image
Feb 13, 2019
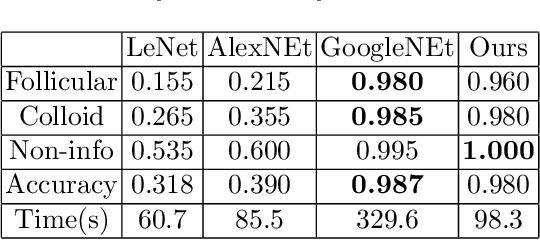
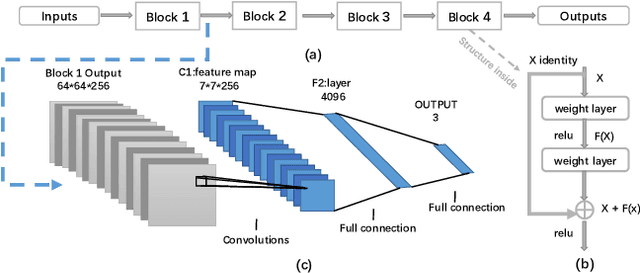
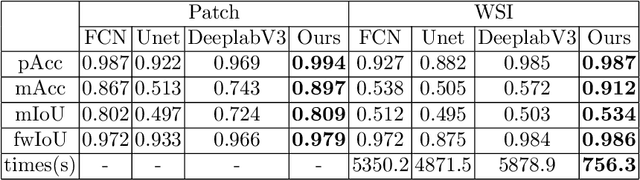
In this paper, we propose a novel method for highly efficient follicular segmentation of thyroid cytopathological WSIs. Firstly, we propose a hybrid segmentation architecture, which integrates a classifier into Deeplab V3 by adding a branch. A large amount of the WSI segmentation time is saved by skipping the irrelevant areas using the classification branch. Secondly, we merge the low scale fine features into the original atrous spatial pyramid pooling (ASPP) in Deeplab V3 to accurately represent the details in cytopathological images. Thirdly, our hybrid model is trained by a criterion-oriented adaptive loss function, which leads the model converging much faster. Experimental results on a collection of thyroid patches demonstrate that the proposed model reaches 80.9% on the segmentation accuracy. Besides, 93% time is reduced for the WSI segmentation by using our proposed method, and the WSI-level accuracy achieves 53.4%.
RRV: A Spatiotemporal Descriptor for Rigid Body Motion Recognition
Jun 04, 2017
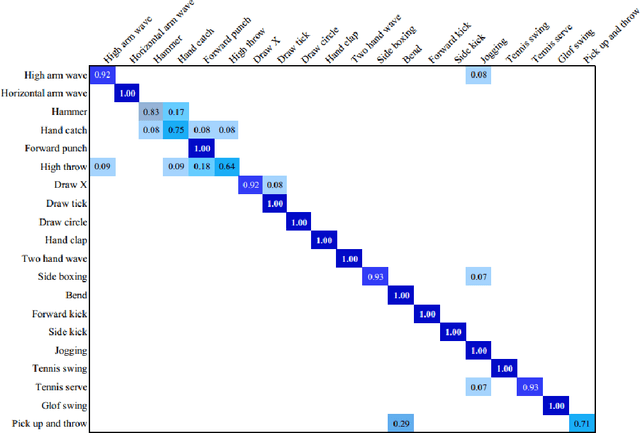


Motion behaviors of a rigid body can be characterized by a 6-dimensional motion trajectory, which contains position vectors of a reference point on the rigid body and rotations of this rigid body over time. This paper devises a Rotation and Relative Velocity (RRV) descriptor by exploring the local translational and rotational invariants of motion trajectories of rigid bodies, which is insensitive to noise, invariant to rigid transformation and scaling. A flexible metric is also introduced to measure the distance between two RRV descriptors. The RRV descriptor is then applied to characterize motions of a human body skeleton modeled as articulated interconnections of multiple rigid bodies. To illustrate the descriptive ability of the RRV descriptor, we explore it for different rigid body motion recognition tasks. The experimental results on benchmark datasets demonstrate that this simple RRV descriptor outperforms the previous ones regarding recognition accuracy without increasing computational cost.