 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-preserving Online AutoML for Domain-Specific Face Detection
Mar 16, 2022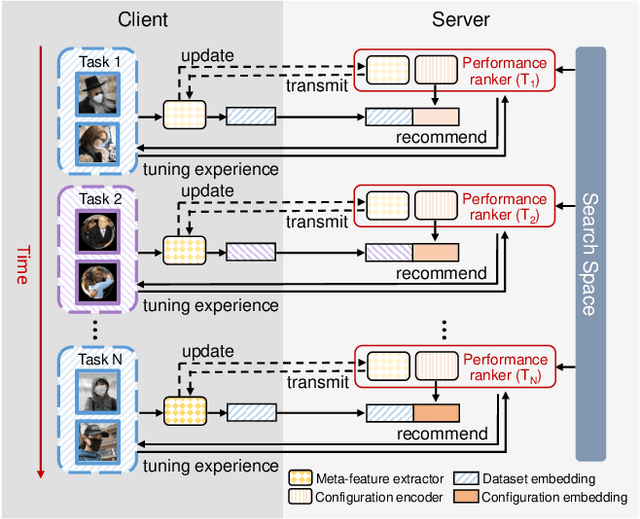
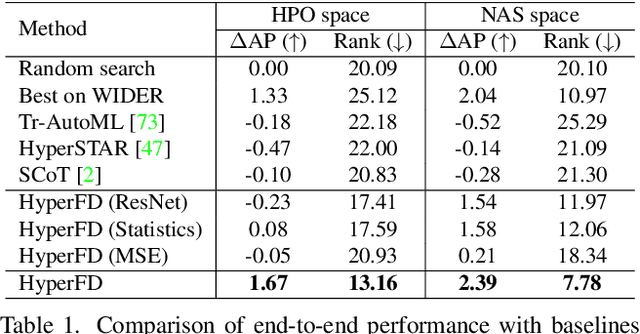
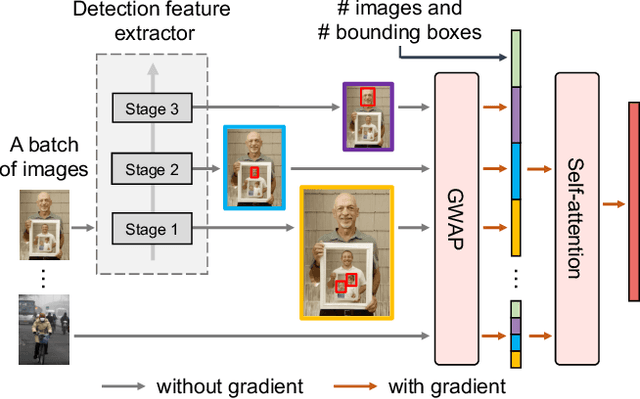
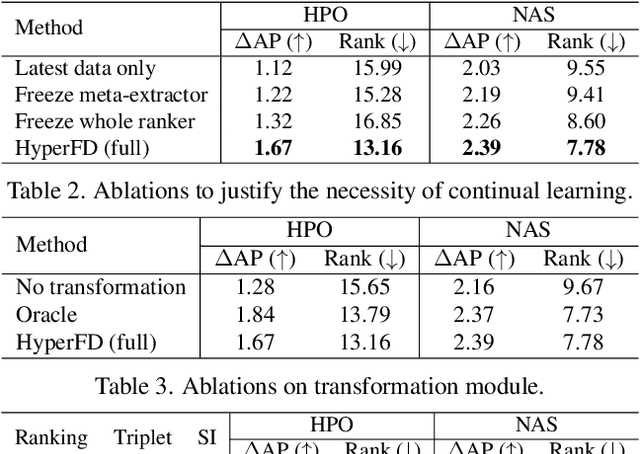
Despite the impressive progress of general face detection, the tuning of hyper-parameters and architectures is still critical for the performance of a domain-specific face detector. Though existing AutoML works can speedup such process, they either require tuning from scratch for a new scenario or do not consider data privacy. To scale up, we derive a new AutoML setting from a platform perspective. In such setting, new datasets sequentially arrive at the platform, where an architecture and hyper-parameter configuration is recommended to train the optimal face detector for each dataset. This, however, brings two major challenges: (1) how to predict the best configuration for any given dataset without touching their raw images due to the privacy concern? and (2) how to continuously improve the AutoML algorithm from previous tasks and offer a better warm-up for future ones? We introduce "HyperFD", a new privacy-preserving online AutoML framework for face detection. At its core part, a novel meta-feature representation of a dataset as well as its learning paradigm is proposed. Thanks to HyperFD, each local task (client) is able to effectively leverage the learning "experience" of previous tasks without uploading raw images to the platform; meanwhile, the meta-feature extractor is continuously learned to better trade off the bias and variance. Extensive experiments demonstrate the effectiveness and efficiency of our design.
Learning Multi-granularity User Intent Unit for Session-based Recommendation
Jan 10, 2022
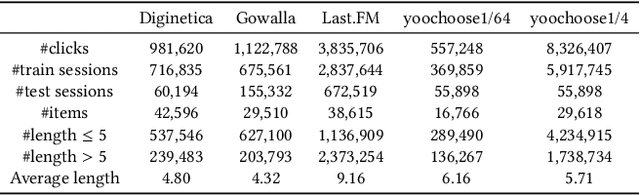
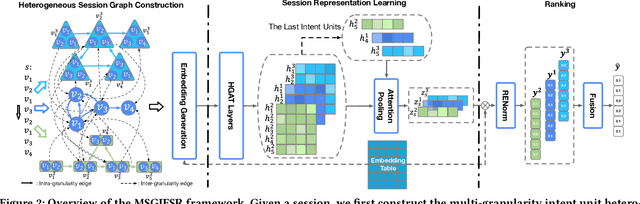
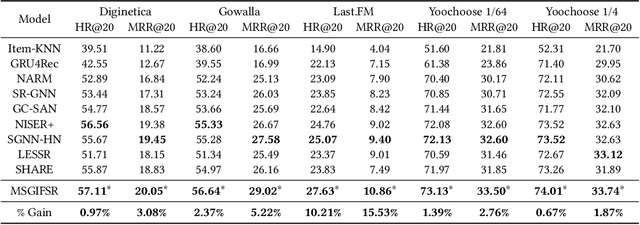
Session-based recommendation aims to predict a user's next action based on previous actions in the current session. The major challenge is to capture authentic and complete user preferences in the entire session. Recent work utilizes graph structure to represent the entire session and adopts Graph Neural Network to encode session information. This modeling choice has been proved to be effective and achieved remarkable results. However, most of the existing studies only consider each item within the session independently and do not capture session semantics from a high-level perspective. Such limitation often leads to severe information loss and increases the difficulty of capturing long-range dependencies within a session. Intuitively, compared with individual items, a session snippet, i.e., a group of locally consecutive items, is able to provide supplemental user intents which are hardly captured by existing methods. In this work, we propose to learn multi-granularity consecutive user intent unit to improve the recommendation performance. Specifically, we creatively propose Multi-granularity Intent Heterogeneous Session Graph which captures the interactions between different granularity intent units and relieves the burden of long-dependency. Moreover, we propose the Intent Fusion Ranking module to compose the recommendation results from various granularity user intents. Compared with current methods that only leverage intents from individual items, IFR benefits from different granularity user intents to generate more accurate and comprehensive session representation, thus eventually boosting recommendation performance. We conduct extensive experiments on five session-based recommendation datasets and the results demonstrate the effectiveness of our method.
SkipNode: On Alleviating Over-smoothing for Deep Graph Convolutional Networks
Dec 22, 2021
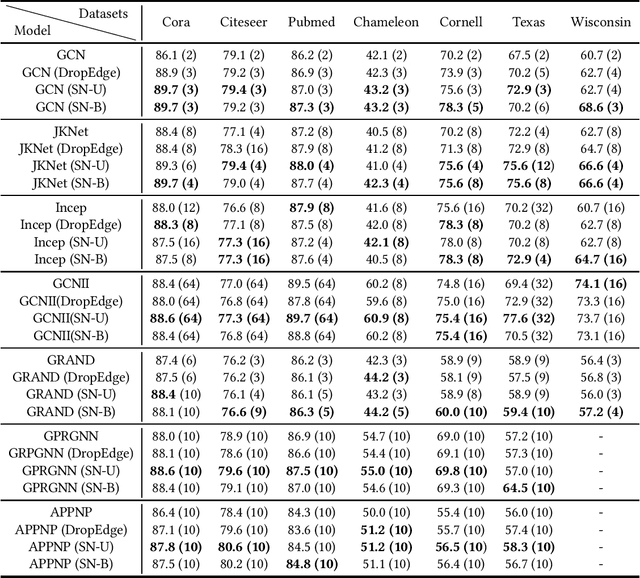

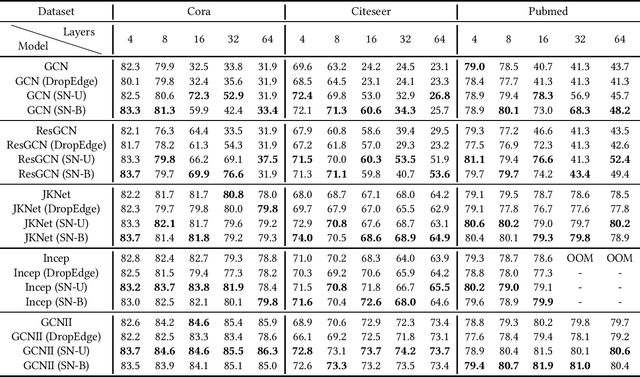
Over-smoothing is a challenging problem, which degrades the performance of deep graph convolutional networks (GCNs). However, existing studies for alleviating the over-smoothing problem lack either generality or effectiveness. In this paper, we analyze the underlying issues behind the over-smoothing problem, i.e., feature-diversity degeneration, gradient vanishing, and model weights over-decaying. Inspired by this, we propose a simple yet effective plug-and-play module, SkipNode, to alleviate over-smoothing. Specifically, for each middle layer of a GCN model, SkipNode randomly (or based on node degree) selects nodes to skip the convolutional operation by directly feeding their input features to the nonlinear function. Analytically, 1) skipping the convolutional operation prevents the features from losing diversity; and 2) the "skipped" nodes enable gradients to be directly passed back, thus mitigating the gradient vanishing and model weights over-decaying issues. To demonstrate the superiority of SkipNode, we conduct extensive experiments on nine popular datasets, including both homophilic and heterophilic graphs, with different graph sizes on two typical tasks: node classification and link prediction. Specifically, 1) SkipNode has strong generalizability of being applied to various GCN-based models on different datasets and tasks; and 2) SkipNode outperforms recent state-of-the-art anti-over-smoothing plug-and-play modules, i.e., DropEdge and DropNode, in different settings. Code will be made publicly available on GitHub.
Multimodal Dialogue Response Generation
Oct 16, 2021
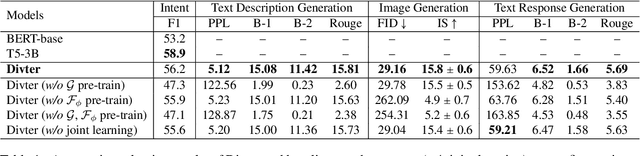
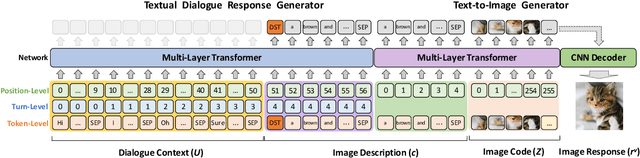
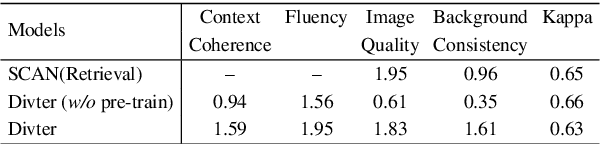
Responsing with image has been recognized as an important capability for an intelligent conversational agent. Yet existing works only focus on exploring the multimodal dialogue models which depend on retrieval-based methods, but neglecting generation methods. To fill in the gaps, we first present a multimodal dialogue generation model, which takes the dialogue history as input, then generates a textual sequence or an image as response. Learning such a model often requires multimodal dialogues containing both texts and images which are difficult to obtain. Motivated by the challenge in practice, we consider multimodal dialogue generation under a natural assumption that only limited training examples are available. In such a low-resource setting, we devise a novel conversational agent, Divter, in order to isolate parameters that depend on multimodal dialogues from the entire generation model. By this means, the major part of the model can be learned from a large number of text-only dialogues and text-image pairs respectively, then the whole parameters can be well fitted using the limited training examples. Extensive experiments demonstrate our method achieves state-of-the-art results in both automatic and human evaluation, and can generate informative text and high-resolution image responses.
WRENCH: A Comprehensive Benchmark for Weak Supervision
Oct 11, 2021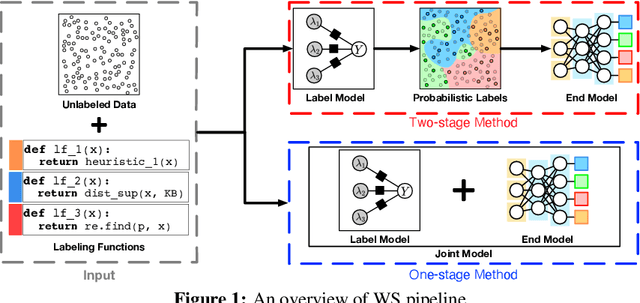
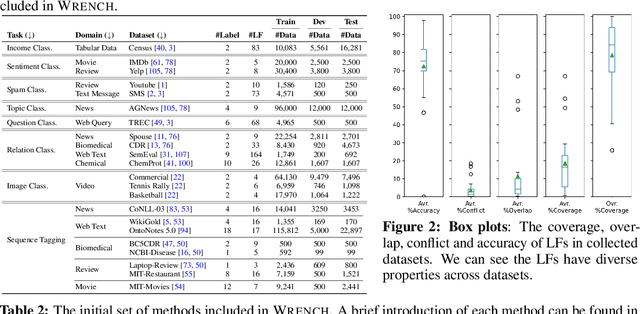
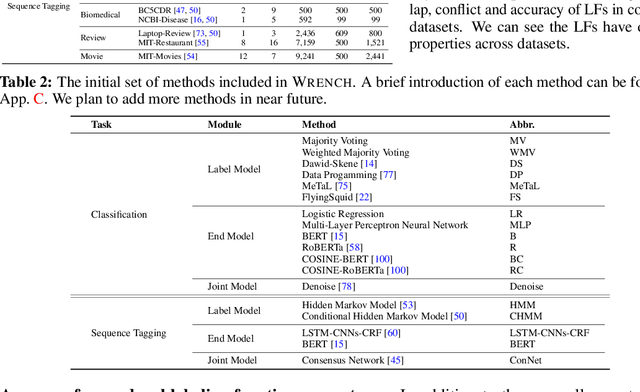
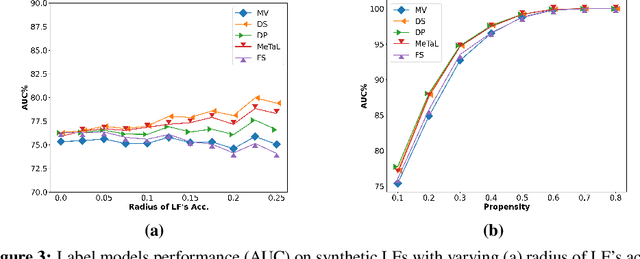
Recent Weak Supervision (WS) approaches have had widespread success in easing the bottleneck of labeling training data for machine learning by synthesizing labels from multiple potentially noisy supervision sources. However, proper measurement and analysis of these approaches remain a challenge. First, datasets used in existing works are often private and/or custom, limiting standardization. Second, WS datasets with the same name and base data often vary in terms of the labels and weak supervision sources used, a significant "hidden" source of evaluation variance. Finally, WS studies often diverge in terms of the evaluation protocol and ablations used. To address these problems, we introduce a benchmark platform, WRENCH, for thorough and standardized evaluation of WS approaches. It consists of 22 varied real-world datasets for classification and sequence tagging; a range of real, synthetic, and procedurally-generated weak supervision sources; and a modular, extensible framework for WS evaluation, including implementations for popular WS methods. We use WRENCH to conduct extensive comparisons over more than 120 method variants to demonstrate its efficacy as a benchmark platform. The code is available at https://github.com/JieyuZ2/wrench.
Creating Training Sets via Weak Indirect Supervision
Oct 07, 2021
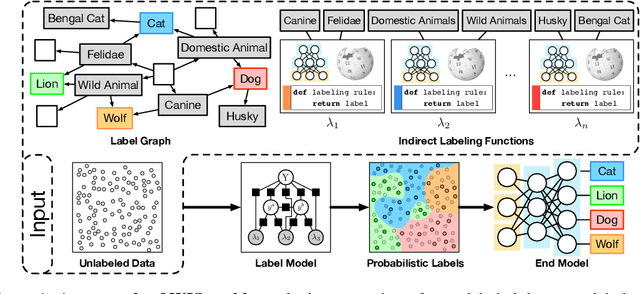
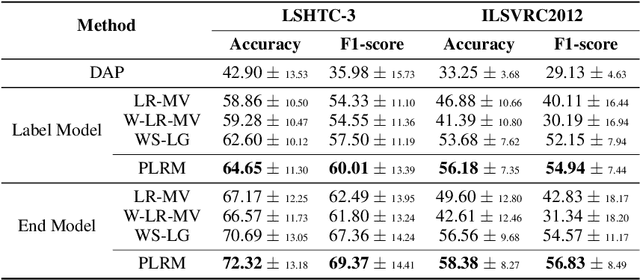
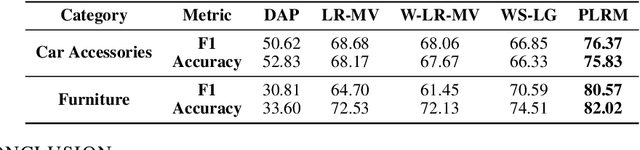
Creating labeled training sets has become one of the major roadblocks in machine learning. To address this, recent Weak Supervision (WS) frameworks synthesize training labels from multiple potentially noisy supervision sources. However, existing frameworks are restricted to supervision sources that share the same output space as the target task. To extend the scope of usable sources, we formulate Weak Indirect Supervision (WIS), a new research problem for automatically synthesizing training labels based on indirect supervision sources that have different output label spaces. To overcome the challenge of mismatched output spaces, we develop a probabilistic modeling approach, PLRM, which uses user-provided label relations to model and leverage indirect supervision sources. Moreover, we provide a theoretically-principled test of the distinguishability of PLRM for unseen labels, along with an generalization bound. On both image and text classification tasks as well as an industrial advertising application, we demonstrate the advantages of PLRM by outperforming baselines by a margin of 2%-9%.
Graph Pointer Neural Networks
Oct 03, 2021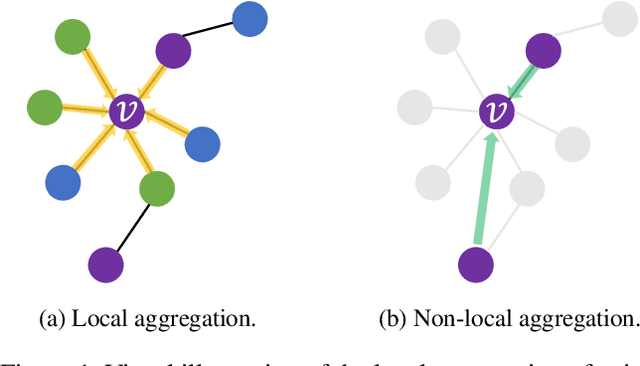
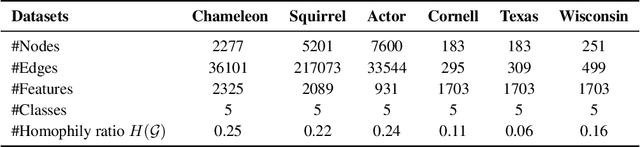
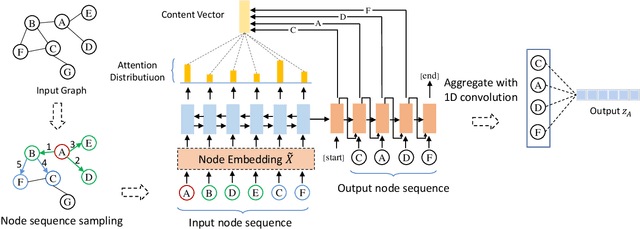
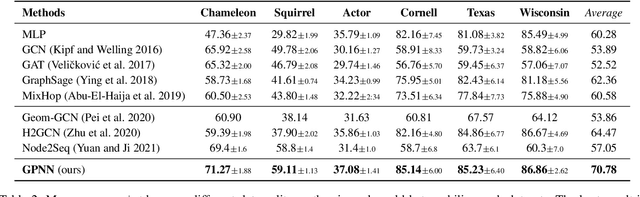
Graph Neural Networks (GNNs) have shown advantages in various graph-based applications. Most existing GNNs assume strong homophily of graph structure and apply permutation-invariant local aggregation of neighbors to learn a representation for each node. However, they fail to generalize to heterophilic graphs, where most neighboring nodes have different labels or features, and the relevant nodes are distant. Few recent studies attempt to address this problem by combining multiple hops of hidden representations of central nodes (i.e., multi-hop-based approaches) or sorting the neighboring nodes based on attention scores (i.e., ranking-based approaches). As a result, these approaches have some apparent limitations. On the one hand, multi-hop-based approaches do not explicitly distinguish relevant nodes from a large number of multi-hop neighborhoods, leading to a severe over-smoothing problem. On the other hand, ranking-based models do not joint-optimize node ranking with end tasks and result in sub-optimal solutions. In this work, we present Graph Pointer Neural Networks (GPNN) to tackle the challenges mentioned above. We leverage a pointer network to select the most relevant nodes from a large amount of multi-hop neighborhoods, which constructs an ordered sequence according to the relationship with the central node. 1D convolution is then applied to extract high-level features from the node sequence. The pointer-network-based ranker in GPNN is joint-optimized with other parts in an end-to-end manner. Extensive experiments are conducted on six public node classification datasets with heterophilic graphs. The results show that GPNN significantly improves the classification performance of state-of-the-art methods. In addition, analyses also reveal the privilege of the proposed GPNN in filtering out irrelevant neighbors and reducing over-smoothing.
Attentive Knowledge-aware Graph Convolutional Networks with Collaborative Guidance for Recommendation
Sep 05, 2021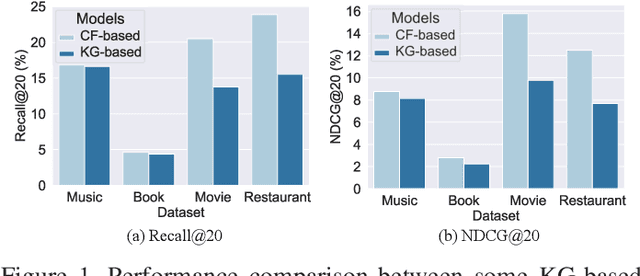
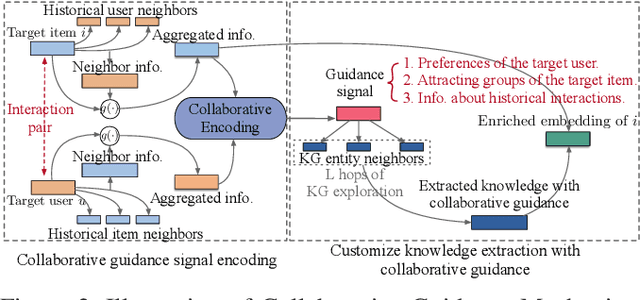
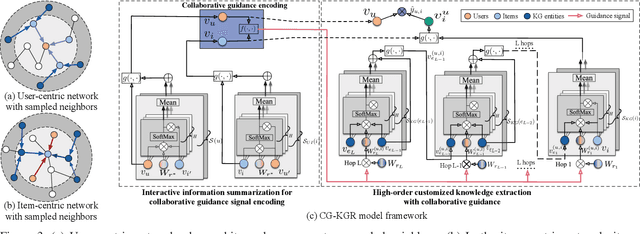
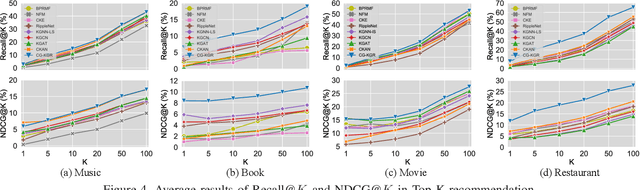
To alleviate data sparsity and cold-start problems of traditional recommender systems (RSs), incorporating knowledge graphs (KGs) to supplement auxiliary information has attracted considerable attention recently. However, simply integrating KGs in current KG-based RS models is not necessarily a guarantee to improve the recommendation performance, which may even weaken the holistic model capability. This is because the construction of these KGs is independent of the collection of historical user-item interactions; hence, information in these KGs may not always be helpful for recommendation to all users. In this paper, we propose attentive Knowledge-aware Graph convolutional networks with Collaborative Guidance for personalized Recommendation (CG-KGR). CG-KGR is a novel knowledge-aware recommendation model that enables ample and coherent learning of KGs and user-item interactions, via our proposed Collaborative Guidance Mechanism. Specifically, CG-KGR first encapsulates historical interactions to interactive information summarization. Then CG-KGR utilizes it as guidance to extract information out of KGs, which eventually provides more precise personalized recommendation. We conduct extensive experiments on four real-world datasets over two recommendation tasks, i.e., Top-K recommendation and Click-Through rate (CTR) prediction. The experimental results show that the CG-KGR model significantly outperforms recent state-of-the-art models by 4.0-53.2% and 0.4-3.2%, in terms of Recall metric on Top-K recommendation and AUC on CTR prediction, respectively.
AceNAS: Learning to Rank Ace Neural Architectures with Weak Supervision of Weight Sharing
Aug 06, 2021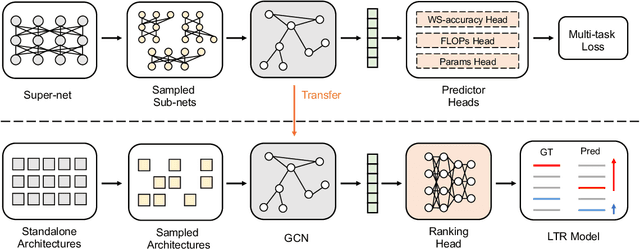
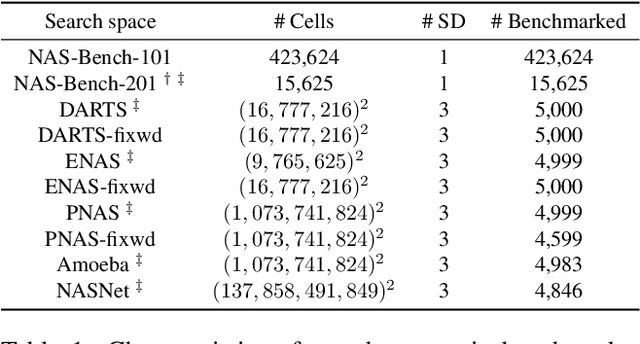
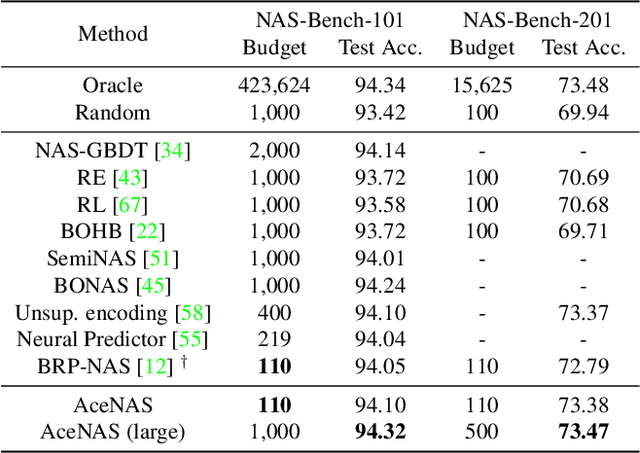
Architecture performance predictors have been widely used in neural architecture search (NAS). Although they are shown to be simple and effective, the optimization objectives in previous arts (e.g., precise accuracy estimation or perfect ranking of all architectures in the space) did not capture the ranking nature of NAS. In addition, a large number of ground-truth architecture-accuracy pairs are usually required to build a reliable predictor, making the process too computationally expensive. To overcome these, in this paper, we look at NAS from a novel point of view and introduce Learning to Rank (LTR) methods to select the best (ace) architectures from a space. Specifically, we propose to use Normalized Discounted Cumulative Gain (NDCG) as the target metric and LambdaRank as the training algorithm. We also propose to leverage weak supervision from weight sharing by pretraining architecture representation on weak labels obtained from the super-net and then finetuning the ranking model using a small number of architectures trained from scratch. Extensive experiments on NAS benchmarks and large-scale search spaces demonstrate that our approach outperforms SOTA with a significantly reduced search cost.
Syntax-BERT: Improving Pre-trained Transformers with Syntax Trees
Mar 07, 2021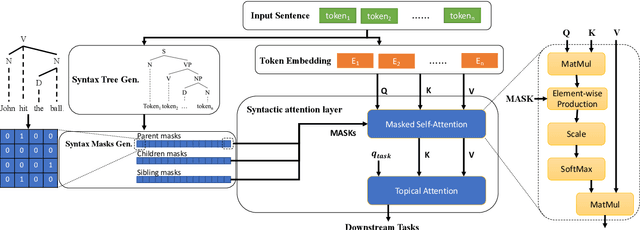

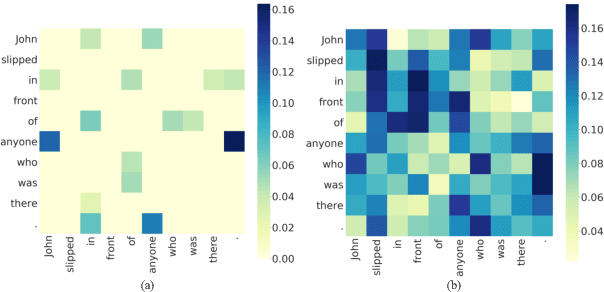
Pre-trained language models like BERT achieve superior performances in various NLP tasks without explicit consideration of syntactic information. Meanwhile, syntactic information has been proved to be crucial for the success of NLP applications. However, how to incorporate the syntax trees effectively and efficiently into pre-trained Transformers is still unsettled. In this paper, we address this problem by proposing a novel framework named Syntax-BERT. This framework works in a plug-and-play mode and is applicable to an arbitrary pre-trained checkpoint based on Transformer architecture. Experiments on various datasets of natural language understanding verify the effectiveness of syntax trees and achieve consistent improvement over multiple pre-trained models, including BERT, RoBERTa, and T5.