 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM3HF: Multi-agent Reinforcement Learning from Multi-phase Human Feedback of Mixed Quality
Mar 06, 2025



Designing effective reward functions in multi-agent reinforcement learning (MARL) is a significant challenge, often leading to suboptimal or misaligned behaviors in complex, coordinated environments. We introduce Multi-agent Reinforcement Learning from Multi-phase Human Feedback of Mixed Quality (M3HF), a novel framework that integrates multi-phase human feedback of mixed quality into the MARL training process. By involving humans with diverse expertise levels to provide iterative guidance, M3HF leverages both expert and non-expert feedback to continuously refine agents' policies. During training, we strategically pause agent learning for human evaluation, parse feedback using large language models to assign it appropriately and update reward functions through predefined templates and adaptive weight by using weight decay and performance-based adjustments. Our approach enables the integration of nuanced human insights across various levels of quality, enhancing the interpretability and robustness of multi-agent cooperation. Empirical results in challenging environments demonstrate that M3HF significantly outperforms state-of-the-art methods, effectively addressing the complexities of reward design in MARL and enabling broader human participation in the training process.
ATLaS: Agent Tuning via Learning Critical Steps
Mar 04, 2025



Large Language Model (LLM) agents have demonstrated remarkable generalization capabilities across multi-domain tasks. Existing agent tuning approaches typically employ supervised finetuning on entire expert trajectories. However, behavior-cloning of full trajectories can introduce expert bias and weaken generalization to states not covered by the expert data. Additionally, critical steps, such as planning, complex reasoning for intermediate subtasks, and strategic decision-making, are essential to success in agent tasks, so learning these steps is the key to improving LLM agents. For more effective and efficient agent tuning, we propose ATLaS that identifies the critical steps in expert trajectories and finetunes LLMs solely on these steps with reduced costs. By steering the training's focus to a few critical steps, our method mitigates the risk of overfitting entire trajectories and promotes generalization across different environments and tasks. In extensive experiments, an LLM finetuned on only 30% critical steps selected by ATLaS outperforms the LLM finetuned on all steps and recent open-source LLM agents. ATLaS maintains and improves base LLM skills as generalist agents interacting with diverse environments.
$\text{M}^3\text{HF}$: Multi-agent Reinforcement Learning from Multi-phase Human Feedback of Mixed Quality
Mar 03, 2025Designing effective reward functions in multi-agent reinforcement learning (MARL) is a significant challenge, often leading to suboptimal or misaligned behaviors in complex, coordinated environments. We introduce Multi-agent Reinforcement Learning from Multi-phase Human Feedback of Mixed Quality ($\text{M}^3\text{HF}$), a novel framework that integrates multi-phase human feedback of mixed quality into the MARL training process. By involving humans with diverse expertise levels to provide iterative guidance, $\text{M}^3\text{HF}$ leverages both expert and non-expert feedback to continuously refine agents' policies. During training, we strategically pause agent learning for human evaluation, parse feedback using large language models to assign it appropriately and update reward functions through predefined templates and adaptive weight by using weight decay and performance-based adjustments. Our approach enables the integration of nuanced human insights across various levels of quality, enhancing the interpretability and robustness of multi-agent cooperation. Empirical results in challenging environments demonstrate that $\text{M}^3\text{HF}$ significantly outperforms state-of-the-art methods, effectively addressing the complexities of reward design in MARL and enabling broader human participation in the training process.
CODI: Compressing Chain-of-Thought into Continuous Space via Self-Distillation
Feb 28, 2025



Chain-of-Thought (CoT) enhances Large Language Models (LLMs) by enabling step-by-step reasoning in natural language. However, the language space may be suboptimal for reasoning. While implicit CoT methods attempt to enable reasoning without explicit CoT tokens, they have consistently lagged behind explicit CoT method in task performance. We propose CODI (Continuous Chain-of-Thought via Self-Distillation), a novel framework that distills CoT into a continuous space, where a shared model acts as both teacher and student, jointly learning explicit and implicit CoT while aligning their hidden activation on the token generating the final answer. CODI is the first implicit CoT method to match explicit CoT's performance on GSM8k while achieving 3.1x compression, surpassing the previous state-of-the-art by 28.2% in accuracy. Furthermore, CODI demonstrates scalability, robustness, and generalizability to more complex CoT datasets. Additionally, CODI retains interpretability by decoding its continuous thoughts, making its reasoning process transparent. Our findings establish implicit CoT as not only a more efficient but a powerful alternative to explicit CoT.
Distill Not Only Data but Also Rewards: Can Smaller Language Models Surpass Larger Ones?
Feb 26, 2025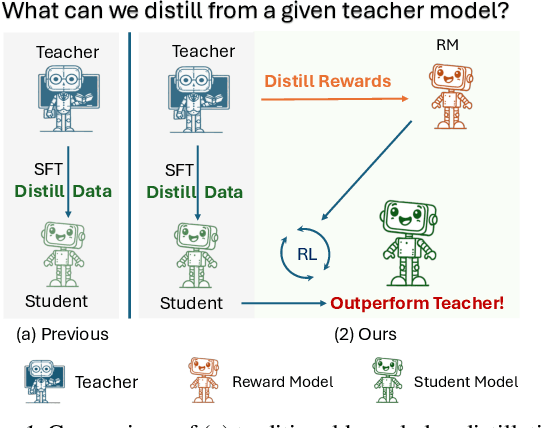

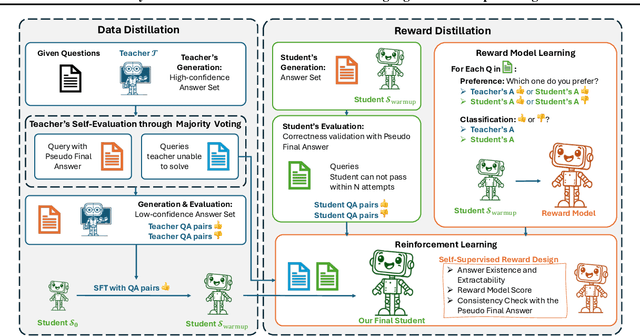
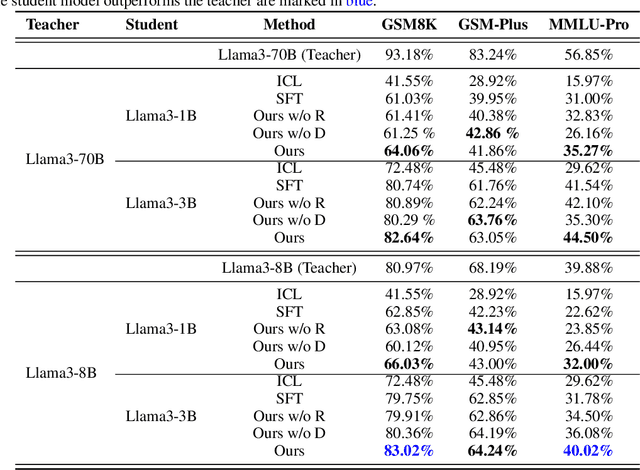
Distilling large language models (LLMs) typically involves transferring the teacher model's responses through supervised fine-tuning (SFT). However, this approach neglects the potential to distill both data (output content) and reward signals (quality evaluations). Extracting reliable reward signals directly from teacher models is challenging, as LLMs are optimized for generation rather than evaluation, often resulting in biased or inconsistent assessments. To address this limitation, we propose a novel distillation pipeline that transfers both responses and rewards. Our method generates pseudo-rewards through a self-supervised mechanism that leverages the inherent structure of both teacher and student responses, enabling reward learning without explicit external evaluation. The reward model subsequently guides reinforcement learning (RL), allowing iterative refinement of the student model after an SFT warm-up phase. Experiments on GSM8K and MMLU-PRO demonstrate that our method consistently outperforms traditional SFT-based approaches, enabling student models to surpass the performance of their teachers. This work highlights the potential for scalable, efficient distillation through structured self-supervised reward learning, reducing dependence on external reward supervision.
VLP: Vision-Language Preference Learning for Embodied Manipulation
Feb 17, 2025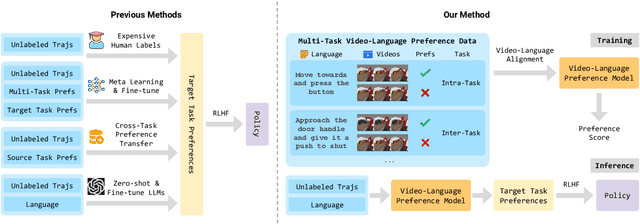

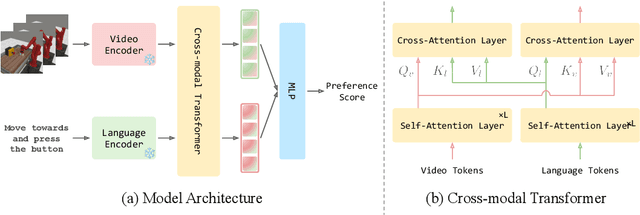
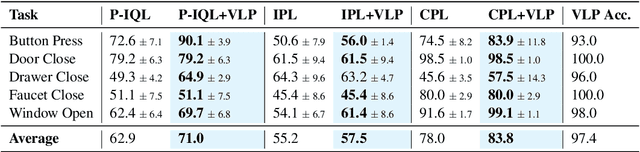
Reward engineering is one of the key challenges in Reinforcement Learning (RL). Preference-based RL effectively addresses this issue by learning from human feedback. However, it is both time-consuming and expensive to collect human preference labels. In this paper, we propose a novel \textbf{V}ision-\textbf{L}anguage \textbf{P}reference learning framework, named \textbf{VLP}, which learns a vision-language preference model to provide preference feedback for embodied manipulation tasks. To achieve this, we define three types of language-conditioned preferences and construct a vision-language preference dataset, which contains versatile implicit preference orders without human annotations. The preference model learns to extract language-related features, and then serves as a preference annotator in various downstream tasks. The policy can be learned according to the annotated preferences via reward learning or direct policy optimization. Extensive empirical results on simulated embodied manipulation tasks demonstrate that our method provides accurate preferences and generalizes to unseen tasks and unseen language instructions, outperforming the baselines by a large margin.
RAT: Adversarial Attacks on Deep Reinforcement Agents for Targeted Behaviors
Dec 14, 2024Evaluating deep reinforcement learning (DRL) agents against targeted behavior attacks is critical for assessing their robustness. These attacks aim to manipulate the victim into specific behaviors that align with the attacker's objectives, often bypassing traditional reward-based defenses. Prior methods have primarily focused on reducing cumulative rewards; however, rewards are typically too generic to capture complex safety requirements effectively. As a result, focusing solely on reward reduction can lead to suboptimal attack strategies, particularly in safety-critical scenarios where more precise behavior manipulation is needed. To address these challenges, we propose RAT, a method designed for universal, targeted behavior attacks. RAT trains an intention policy that is explicitly aligned with human preferences, serving as a precise behavioral target for the adversary. Concurrently, an adversary manipulates the victim's policy to follow this target behavior. To enhance the effectiveness of these attacks, RAT dynamically adjusts the state occupancy measure within the replay buffer, allowing for more controlled and effective behavior manipulation. Our empirical results on robotic simulation tasks demonstrate that RAT outperforms existing adversarial attack algorithms in inducing specific behaviors. Additionally, RAT shows promise in improving agent robustness, leading to more resilient policies. We further validate RAT by guiding Decision Transformer agents to adopt behaviors aligned with human preferences in various MuJoCo tasks, demonstrating its effectiveness across diverse tasks.
RuAG: Learned-rule-augmented Generation for Large Language Models
Nov 04, 2024



In-context learning (ICL) and Retrieval-Augmented Generation (RAG) have gained attention for their ability to enhance LLMs' reasoning by incorporating external knowledge but suffer from limited contextual window size, leading to insufficient information injection. To this end, we propose a novel framework, RuAG, to automatically distill large volumes of offline data into interpretable first-order logic rules, which are injected into LLMs to boost their reasoning capabilities. Our method begins by formulating the search process relying on LLMs' commonsense, where LLMs automatically define head and body predicates. Then, RuAG applies Monte Carlo Tree Search (MCTS) to address the combinational searching space and efficiently discover logic rules from data. The resulting logic rules are translated into natural language, allowing targeted knowledge injection and seamless integration into LLM prompts for LLM's downstream task reasoning. We evaluate our framework on public and private industrial tasks, including natural language processing, time-series, decision-making, and industrial tasks, demonstrating its effectiveness in enhancing LLM's capability over diverse tasks.
A Joint Learning Model with Variational Interaction for Multilingual Program Translation
Aug 25, 2024



Programs implemented in various programming languages form the foundation of software applications. To alleviate the burden of program migration and facilitate the development of software systems, automated program translation across languages has garnered significant attention. Previous approaches primarily focus on pairwise translation paradigms, learning translation between pairs of languages using bilingual parallel data. However, parallel data is difficult to collect for some language pairs, and the distribution of program semantics across languages can shift, posing challenges for pairwise program translation. In this paper, we argue that jointly learning a unified model to translate code across multiple programming languages is superior to separately learning from bilingual parallel data. We propose Variational Interaction for Multilingual Program Translation~(VIM-PT), a disentanglement-based generative approach that jointly trains a unified model for multilingual program translation across multiple languages. VIM-PT disentangles code into language-shared and language-specific features, using variational inference and interaction information with a novel lower bound, then achieves program translation through conditional generation. VIM-PT demonstrates four advantages: 1) captures language-shared information more accurately from various implementations and improves the quality of multilingual program translation, 2) mines and leverages the capability of non-parallel data, 3) addresses the distribution shift of program semantics across languages, 4) and serves as a unified model, reducing deployment complexity.
Explaining an Agent's Future Beliefs through Temporally Decomposing Future Reward Estimators
Aug 15, 2024



Future reward estimation is a core component of reinforcement learning agents; i.e., Q-value and state-value functions, predicting an agent's sum of future rewards. Their scalar output, however, obfuscates when or what individual future rewards an agent may expect to receive. We address this by modifying an agent's future reward estimator to predict their next N expected rewards, referred to as Temporal Reward Decomposition (TRD). This unlocks novel explanations of agent behaviour. Through TRD we can: estimate when an agent may expect to receive a reward, the value of the reward and the agent's confidence in receiving it; measure an input feature's temporal importance to the agent's action decisions; and predict the influence of different actions on future rewards. Furthermore, we show that DQN agents trained on Atari environments can be efficiently retrained to incorporate TRD with minimal impact on performance.
* 7 pages + 3 pages of supplementary material. Published at ECAI 2024