 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Data Variance in Evaluations of Automatic Machine Translation Metrics
Mar 29, 2022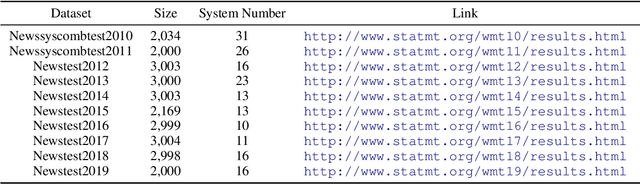
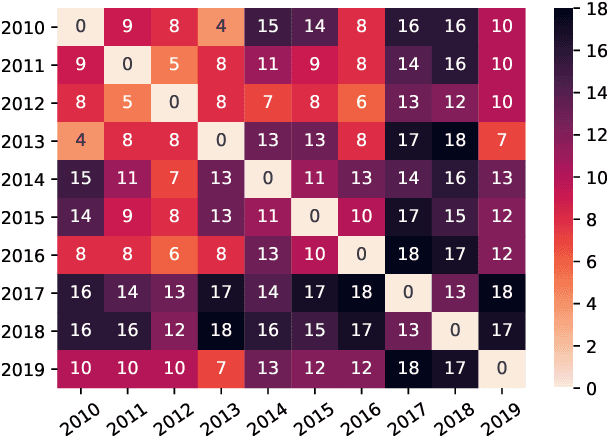
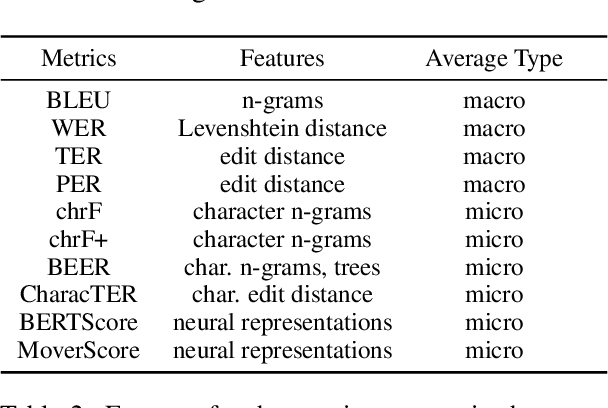
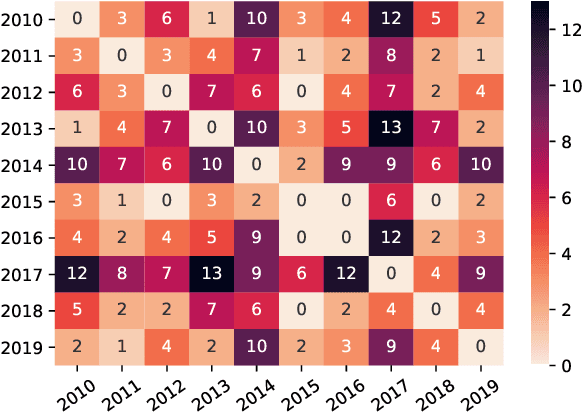
Current practices in metric evaluation focus on one single dataset, e.g., Newstest dataset in each year's WMT Metrics Shared Task. However, in this paper, we qualitatively and quantitatively show that the performances of metrics are sensitive to data. The ranking of metrics varies when the evaluation is conducted on different datasets. Then this paper further investigates two potential hypotheses, i.e., insignificant data points and the deviation of Independent and Identically Distributed (i.i.d) assumption, which may take responsibility for the issue of data variance. In conclusion, our findings suggest that when evaluating automatic translation metrics, researchers should take data variance into account and be cautious to claim the result on a single dataset, because it may leads to inconsistent results with most of other datasets.
ISF-GAN: An Implicit Style Function for High-Resolution Image-to-Image Translation
Sep 26, 2021



Recently, there has been an increasing interest in image editing methods that employ pre-trained unconditional image generators (e.g., StyleGAN). However, applying these methods to translate images to multiple visual domains remains challenging. Existing works do not often preserve the domain-invariant part of the image (e.g., the identity in human face translations), they do not usually handle multiple domains, or do not allow for multi-modal translations. This work proposes an implicit style function (ISF) to straightforwardly achieve multi-modal and multi-domain image-to-image translation from pre-trained unconditional generators. The ISF manipulates the semantics of an input latent code to make the image generated from it lying in the desired visual domain. Our results in human face and animal manipulations show significantly improved results over the baselines. Our model enables cost-effective multi-modal unsupervised image-to-image translations at high resolution using pre-trained unconditional GANs. The code and data are available at: \url{https://github.com/yhlleo/stylegan-mmuit}.
Smoothing the Disentangled Latent Style Space for Unsupervised Image-to-Image Translation
Jun 16, 2021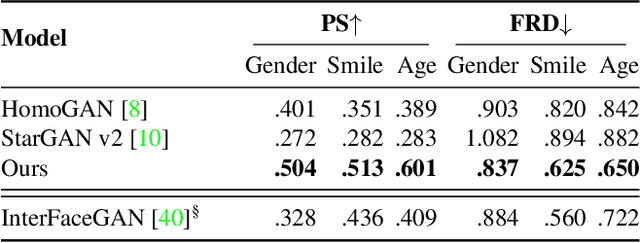
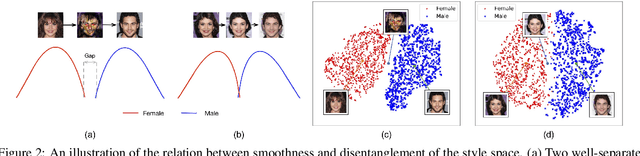
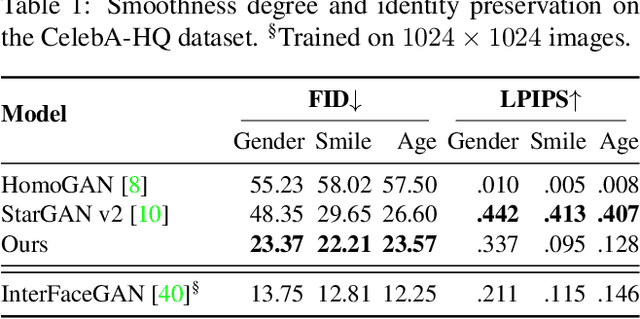

Image-to-Image (I2I) multi-domain translation models are usually evaluated also using the quality of their semantic interpolation results. However, state-of-the-art models frequently show abrupt changes in the image appearance during interpolation, and usually perform poorly in interpolations across domains. In this paper, we propose a new training protocol based on three specific losses which help a translation network to learn a smooth and disentangled latent style space in which: 1) Both intra- and inter-domain interpolations correspond to gradual changes in the generated images and 2) The content of the source image is better preserved during the translation. Moreover, we propose a novel evaluation metric to properly measure the smoothness of latent style space of I2I translation models. The proposed method can be plugged into existing translation approaches, and our extensive experiments on different datasets show that it can significantly boost the quality of the generated images and the graduality of the interpolations.
Efficient Training of Visual Transformers with Small-Size Datasets
Jun 07, 2021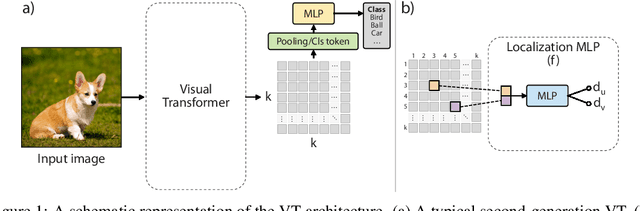
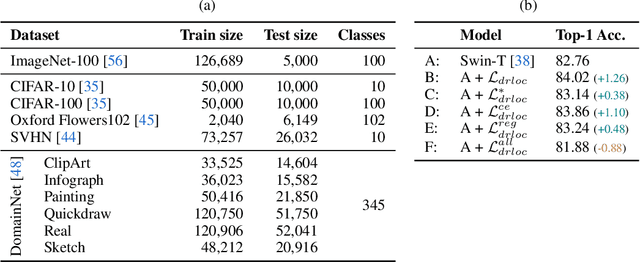
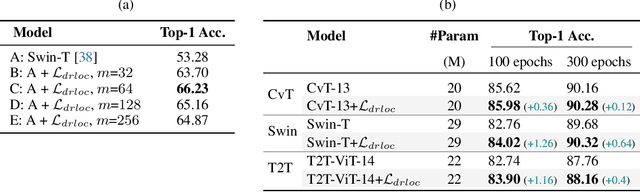

Visual Transformers (VTs) are emerging as an architectural paradigm alternative to Convolutional networks (CNNs). Differently from CNNs, VTs can capture global relations between image elements and they potentially have a larger representation capacity. However, the lack of the typical convolutional inductive bias makes these models more data-hungry than common CNNs. In fact, some local properties of the visual domain which are embedded in the CNN architectural design, in VTs should be learned from samples. In this paper, we empirically analyse different VTs, comparing their robustness in a small training-set regime, and we show that, despite having a comparable accuracy when trained on ImageNet, their performance on smaller datasets can be largely different. Moreover, we propose a self-supervised task which can extract additional information from images with only a negligible computational overhead. This task encourages the VTs to learn spatial relations within an image and makes the VT training much more robust when training data are scarce. Our task is used jointly with the standard (supervised) training and it does not depend on specific architectural choices, thus it can be easily plugged in the existing VTs. Using an extensive evaluation with different VTs and datasets, we show that our method can improve (sometimes dramatically) the final accuracy of the VTs. The code will be available upon acceptance.
Assessing Dialogue Systems with Distribution Distances
May 27, 2021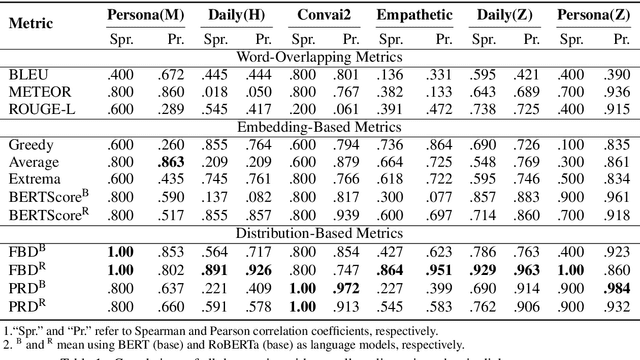
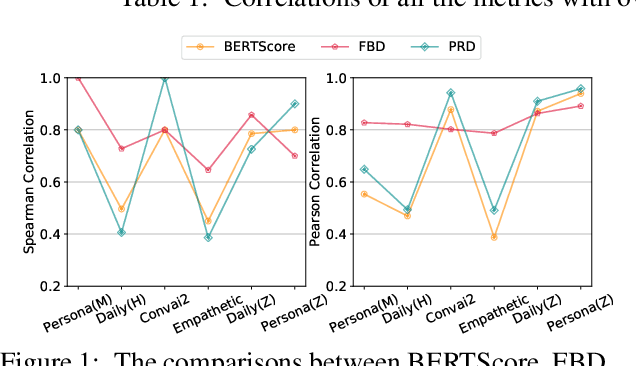
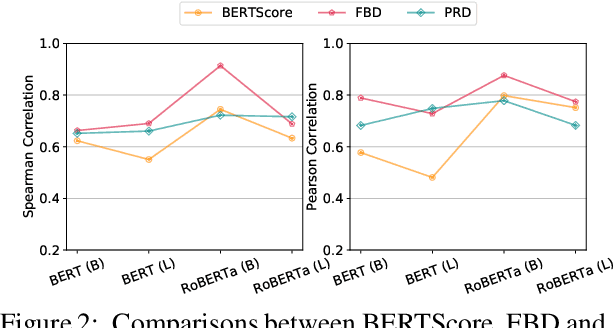
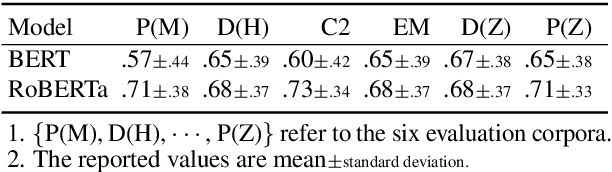
An important aspect of developing dialogue systems is how to evaluate and compare the performance of different systems. Existing automatic evaluation metrics are based on turn-level quality evaluation and use average scores for system-level comparison. In this paper, we propose to measure the performance of a dialogue system by computing the distribution-wise distance between its generated conversations and real-world conversations. Specifically, two distribution-wise metrics, FBD and PRD, are developed and evaluated. Experiments on several dialogue corpora show that our proposed metrics correlate better with human judgments than existing metrics.
* 7 pages, 2 figures
The Matter of Time -- A General and Efficient System for Precise Sensor Synchronization in Robotic Computing
Mar 30, 2021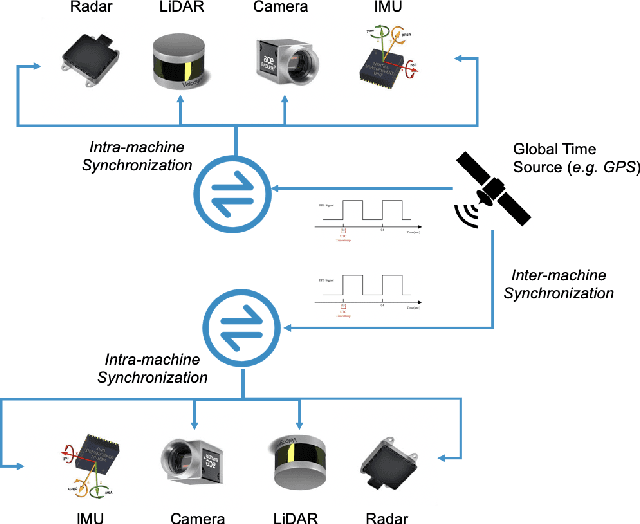
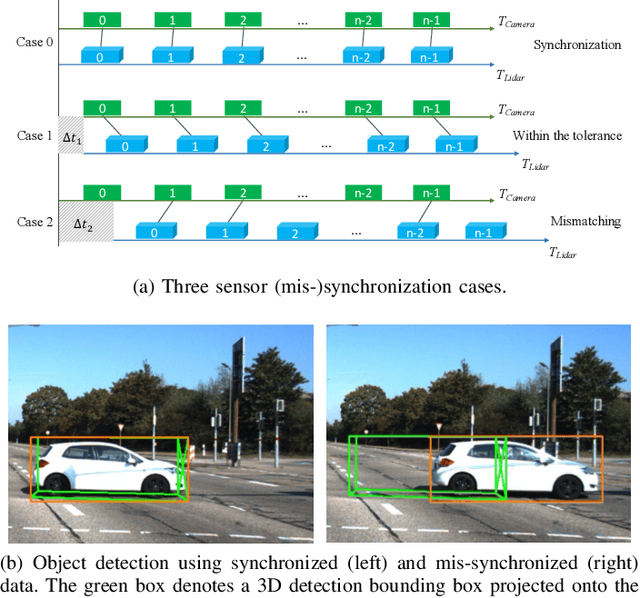
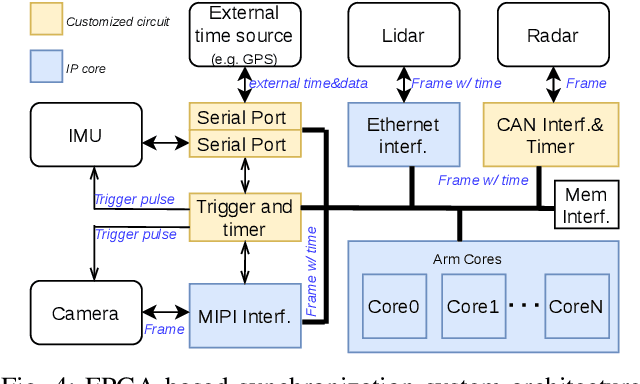
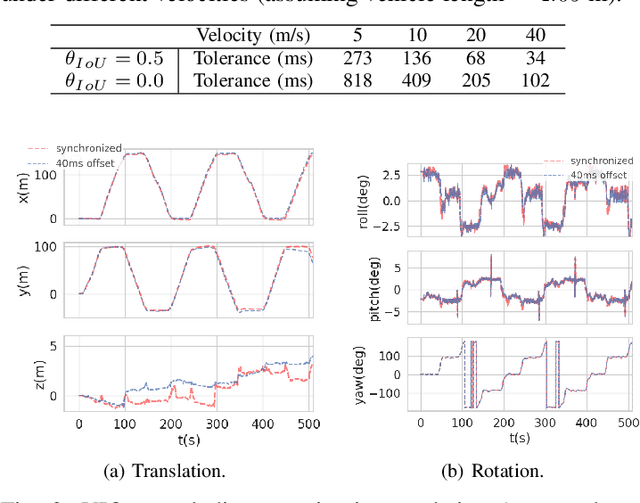
Time synchronization is a critical task in robotic computing such as autonomous driving. In the past few years, as we developed advanced robotic applications, our synchronization system has evolved as well. In this paper, we first introduce the time synchronization problem and explain the challenges of time synchronization, especially in robotic workloads. Summarizing these challenges, we then present a general hardware synchronization system for robotic computing, which delivers high synchronization accuracy while maintaining low energy and resource consumption. The proposed hardware synchronization system is a key building block in our future robotic products.
Adversarial Shape Learning for Building Extraction in VHR Remote Sensing Images
Mar 17, 2021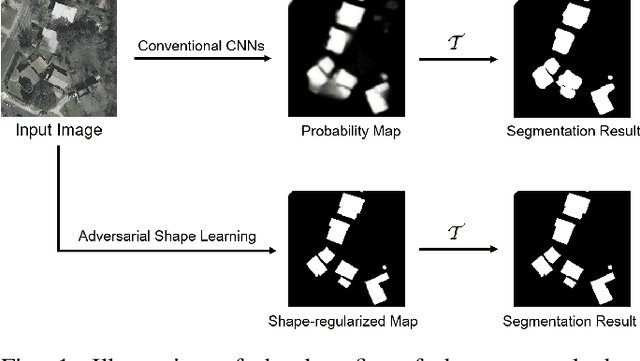
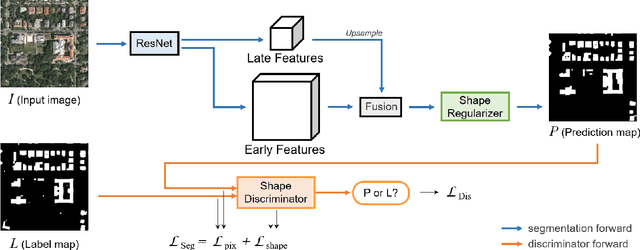
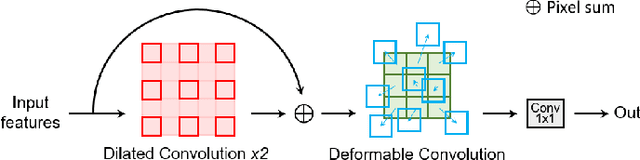
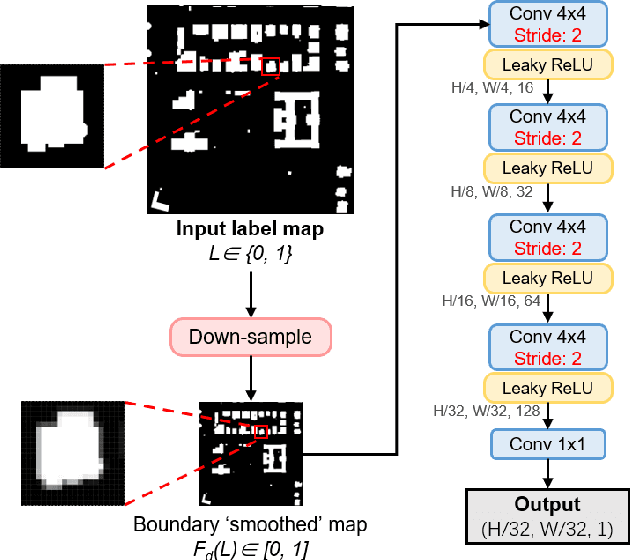
Building extraction in VHR RSIs remains to be a challenging task due to occlusion and boundary ambiguity problems. Although conventional convolutional neural networks (CNNs) based methods are capable of exploiting local texture and context information, they fail to capture the shape patterns of buildings, which is a necessary constraint in the human recognition. In this context, we propose an adversarial shape learning network (ASLNet) to model the building shape patterns, thus improving the accuracy of building segmentation. In the proposed ASLNet, we introduce the adversarial learning strategy to explicitly model the shape constraints, as well as a CNN shape regularizer to strengthen the embedding of shape features. To assess the geometric accuracy of building segmentation results, we further introduced several object-based assessment metrics. Experiments on two open benchmark datasets show that the proposed ASLNet improves both the pixel-based accuracy and the object-based measurements by a large margin. The code is available at: https://github.com/ggsDing/ASLNet
Semantic-Guided Inpainting Network for Complex Urban Scenes Manipulation
Oct 19, 2020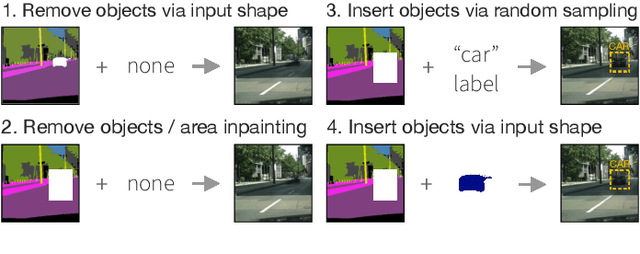



Manipulating images of complex scenes to reconstruct, insert and/or remove specific object instances is a challenging task. Complex scenes contain multiple semantics and objects, which are frequently cluttered or ambiguous, thus hampering the performance of inpainting models. Conventional techniques often rely on structural information such as object contours in multi-stage approaches that generate unreliable results and boundaries. In this work, we propose a novel deep learning model to alter a complex urban scene by removing a user-specified portion of the image and coherently inserting a new object (e.g. car or pedestrian) in that scene. Inspired by recent works on image inpainting, our proposed method leverages the semantic segmentation to model the content and structure of the image, and learn the best shape and location of the object to insert. To generate reliable results, we design a new decoder block that combines the semantic segmentation and generation task to guide better the generation of new objects and scenes, which have to be semantically consistent with the image. Our experiments, conducted on two large-scale datasets of urban scenes (Cityscapes and Indian Driving), show that our proposed approach successfully address the problem of semantically-guided inpainting of complex urban scene.
Retrieval Guided Unsupervised Multi-domain Image-to-Image Translation
Aug 11, 2020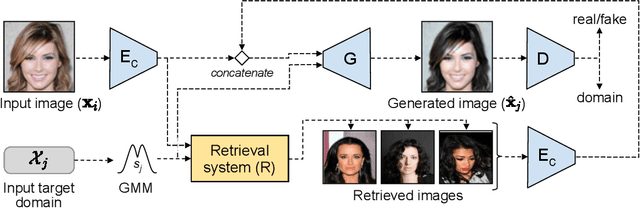
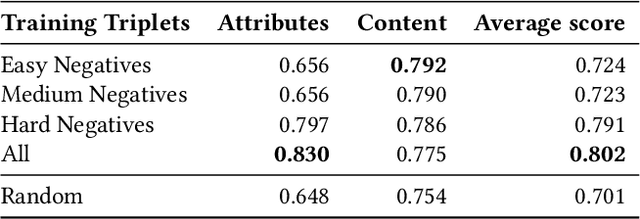
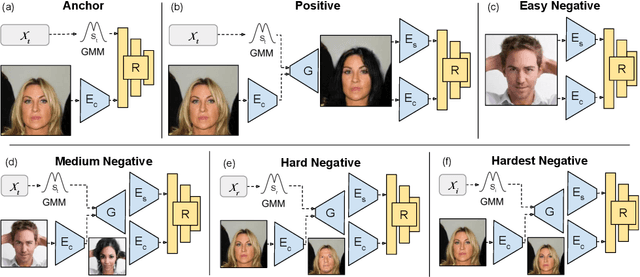
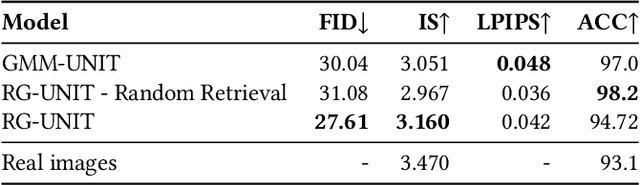
Image to image translation aims to learn a mapping that transforms an image from one visual domain to another. Recent works assume that images descriptors can be disentangled into a domain-invariant content representation and a domain-specific style representation. Thus, translation models seek to preserve the content of source images while changing the style to a target visual domain. However, synthesizing new images is extremely challenging especially in multi-domain translations, as the network has to compose content and style to generate reliable and diverse images in multiple domains. In this paper we propose the use of an image retrieval system to assist the image-to-image translation task. First, we train an image-to-image translation model to map images to multiple domains. Then, we train an image retrieval model using real and generated images to find images similar to a query one in content but in a different domain. Finally, we exploit the image retrieval system to fine-tune the image-to-image translation model and generate higher quality images. Our experiments show the effectiveness of the proposed solution and highlight the contribution of the retrieval network, which can benefit from additional unlabeled data and help image-to-image translation models in the presence of scarce data.
Describe What to Change: A Text-guided Unsupervised Image-to-Image Translation Approach
Aug 10, 2020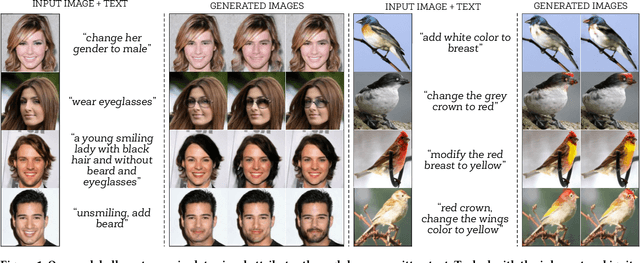
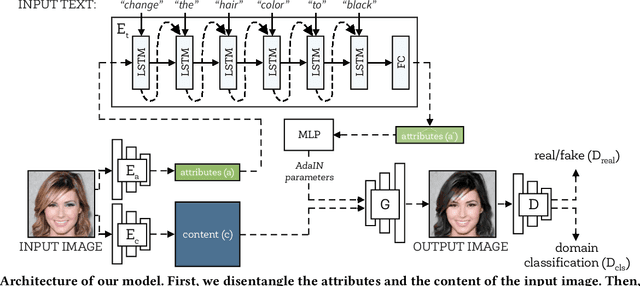

Manipulating visual attributes of images through human-written text is a very challenging task. On the one hand, models have to learn the manipulation without the ground truth of the desired output. On the other hand, models have to deal with the inherent ambiguity of natural language. Previous research usually requires either the user to describe all the characteristics of the desired image or to use richly-annotated image captioning datasets. In this work, we propose a novel unsupervised approach, based on image-to-image translation, that alters the attributes of a given image through a command-like sentence such as "change the hair color to black". Contrarily to state-of-the-art approaches, our model does not require a human-annotated dataset nor a textual description of all the attributes of the desired image, but only those that have to be modified. Our proposed model disentangles the image content from the visual attributes, and it learns to modify the latter using the textual description, before generating a new image from the content and the modified attribute representation. Because text might be inherently ambiguous (blond hair may refer to different shadows of blond, e.g. golden, icy, sandy), our method generates multiple stochastic versions of the same translation. Experiments show that the proposed model achieves promising performances on two large-scale public datasets: CelebA and CUB. We believe our approach will pave the way to new avenues of research combining textual and speech commands with visual attributes.