 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint Cloud Classification Using Content-based Transformer via Clustering in Feature Space
Mar 08, 2023



Recently, there have been some attempts of Transformer in 3D point cloud classification. In order to reduce computations, most existing methods focus on local spatial attention, but ignore their content and fail to establish relationships between distant but relevant points. To overcome the limitation of local spatial attention, we propose a point content-based Transformer architecture, called PointConT for short. It exploits the locality of points in the feature space (content-based), which clusters the sampled points with similar features into the same class and computes the self-attention within each class, thus enabling an effective trade-off between capturing long-range dependencies and computational complexity. We further introduce an Inception feature aggregator for point cloud classification, which uses parallel structures to aggregate high-frequency and low-frequency information in each branch separately. Extensive experiments show that our PointConT model achieves a remarkable performance on point cloud shape classification. Especially, our method exhibits 90.3% Top-1 accuracy on the hardest setting of ScanObjectNN. Source code of this paper is available at https://github.com/yahuiliu99/PointConT.
Smooth image-to-image translations with latent space interpolations
Oct 03, 2022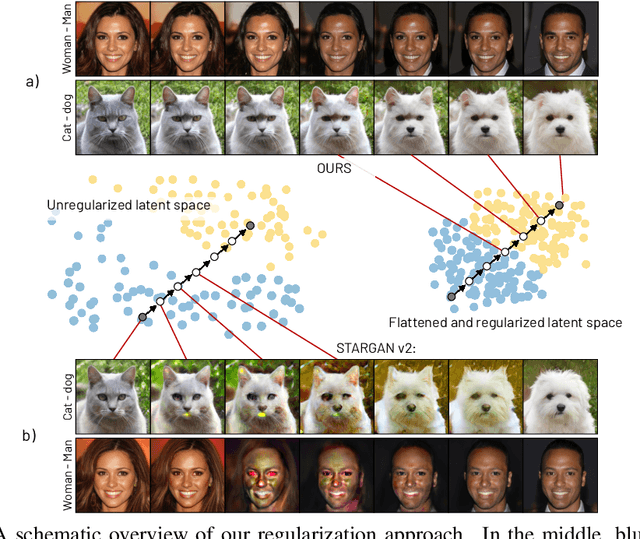
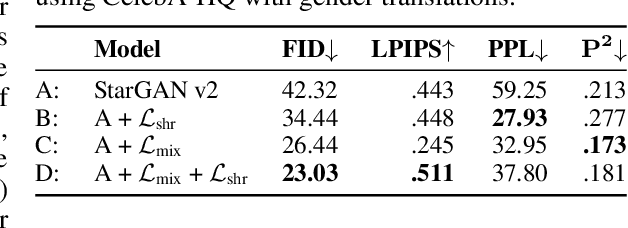
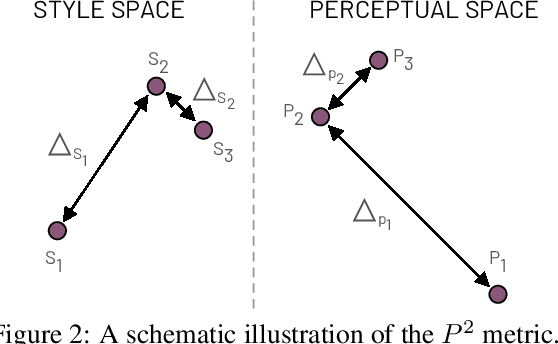
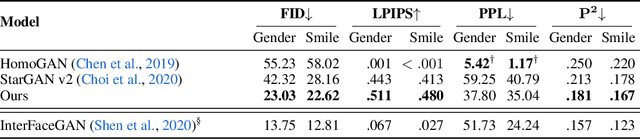
Multi-domain image-to-image (I2I) translations can transform a source image according to the style of a target domain. One important, desired characteristic of these transformations, is their graduality, which corresponds to a smooth change between the source and the target image when their respective latent-space representations are linearly interpolated. However, state-of-the-art methods usually perform poorly when evaluated using inter-domain interpolations, often producing abrupt changes in the appearance or non-realistic intermediate images. In this paper, we argue that one of the main reasons behind this problem is the lack of sufficient inter-domain training data and we propose two different regularization methods to alleviate this issue: a new shrinkage loss, which compacts the latent space, and a Mixup data-augmentation strategy, which flattens the style representations between domains. We also propose a new metric to quantitatively evaluate the degree of the interpolation smoothness, an aspect which is not sufficiently covered by the existing I2I translation metrics. Using both our proposed metric and standard evaluation protocols, we show that our regularization techniques can improve the state-of-the-art multi-domain I2I translations by a large margin. Our code will be made publicly available upon the acceptance of this article.
Training and Tuning Generative Neural Radiance Fields for Attribute-Conditional 3D-Aware Face Generation
Aug 26, 2022

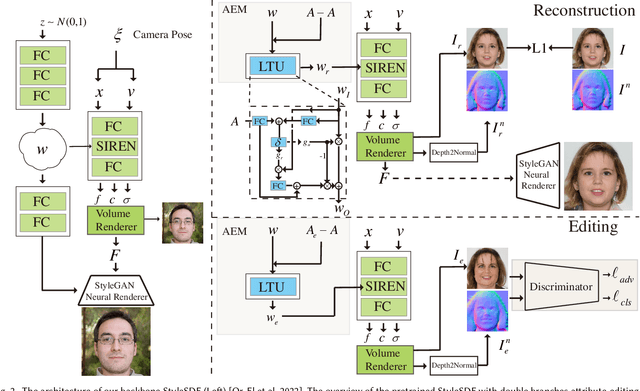
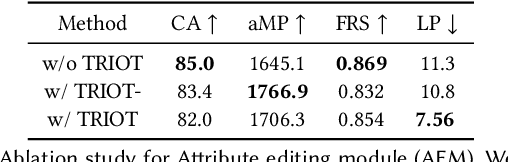
3D-aware GANs based on generative neural radiance fields (GNeRF) have achieved impressive high-quality image generation, while preserving strong 3D consistency. The most notable achievements are made in the face generation domain. However, most of these models focus on improving view consistency but neglect a disentanglement aspect, thus these models cannot provide high-quality semantic/attribute control over generation. To this end, we introduce a conditional GNeRF model that uses specific attribute labels as input in order to improve the controllabilities and disentangling abilities of 3D-aware generative models. We utilize the pre-trained 3D-aware model as the basis and integrate a dual-branches attribute-editing module (DAEM), that utilize attribute labels to provide control over generation. Moreover, we propose a TRIOT (TRaining as Init, and Optimizing for Tuning) method to optimize the latent vector to improve the precision of the attribute-editing further. Extensive experiments on the widely used FFHQ show that our model yields high-quality editing with better view consistency while preserving the non-target regions. The code is available at https://github.com/zhangqianhui/TT-GNeRF.
YOLO-FaceV2: A Scale and Occlusion Aware Face Detector
Aug 04, 2022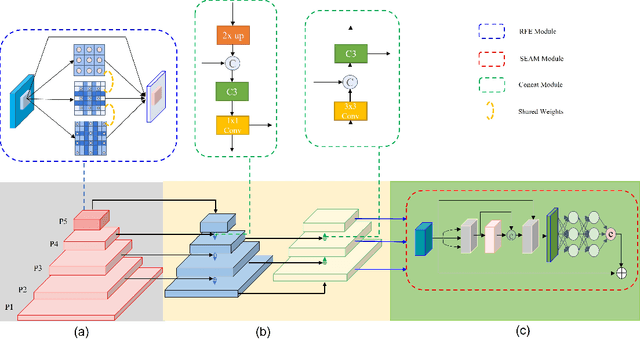
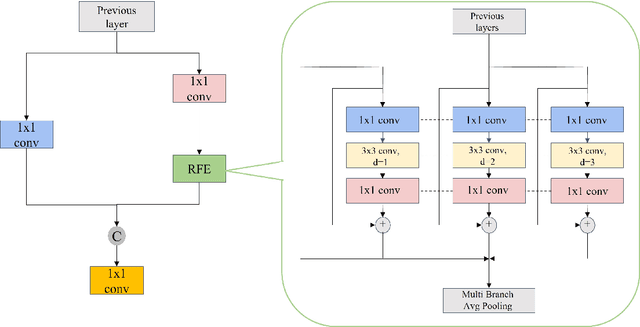
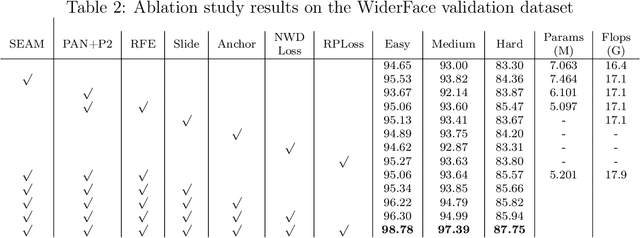
In recent years, face detection algorithms based on deep learning have made great progress. These algorithms can be generally divided into two categories, i.e. two-stage detector like Faster R-CNN and one-stage detector like YOLO. Because of the better balance between accuracy and speed, one-stage detectors have been widely used in many applications. In this paper, we propose a real-time face detector based on the one-stage detector YOLOv5, named YOLO-FaceV2. We design a Receptive Field Enhancement module called RFE to enhance receptive field of small face, and use NWD Loss to make up for the sensitivity of IoU to the location deviation of tiny objects. For face occlusion, we present an attention module named SEAM and introduce Repulsion Loss to solve it. Moreover, we use a weight function Slide to solve the imbalance between easy and hard samples and use the information of the effective receptive field to design the anchor. The experimental results on WiderFace dataset show that our face detector outperforms YOLO and its variants can be find in all easy, medium and hard subsets. Source code in https://github.com/Krasjet-Yu/YOLO-FaceV2
Jigsaw-ViT: Learning Jigsaw Puzzles in Vision Transformer
Jul 25, 2022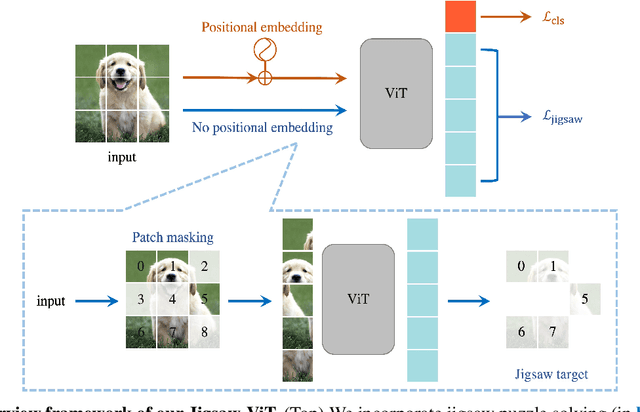



The success of Vision Transformer (ViT) in various computer vision tasks has promoted the ever-increasing prevalence of this convolution-free network. The fact that ViT works on image patches makes it potentially relevant to the problem of jigsaw puzzle solving, which is a classical self-supervised task aiming at reordering shuffled sequential image patches back to their natural form. Despite its simplicity, solving jigsaw puzzle has been demonstrated to be helpful for diverse tasks using Convolutional Neural Networks (CNNs), such as self-supervised feature representation learning, domain generalization, and fine-grained classification. In this paper, we explore solving jigsaw puzzle as a self-supervised auxiliary loss in ViT for image classification, named Jigsaw-ViT. We show two modifications that can make Jigsaw-ViT superior to standard ViT: discarding positional embeddings and masking patches randomly. Yet simple, we find that Jigsaw-ViT is able to improve both in generalization and robustness over the standard ViT, which is usually rather a trade-off. Experimentally, we show that adding the jigsaw puzzle branch provides better generalization than ViT on large-scale image classification on ImageNet. Moreover, the auxiliary task also improves robustness to noisy labels on Animal-10N, Food-101N, and Clothing1M as well as adversarial examples. Our implementation is available at https://yingyichen-cyy.github.io/Jigsaw-ViT/.
Brief Industry Paper: The Necessity of Adaptive Data Fusion in Infrastructure-Augmented Autonomous Driving System
Jul 02, 2022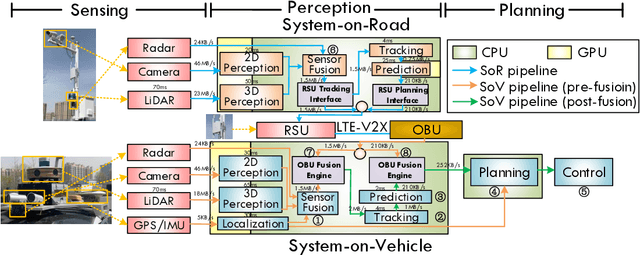
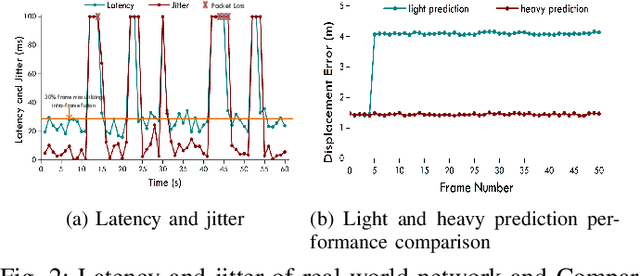
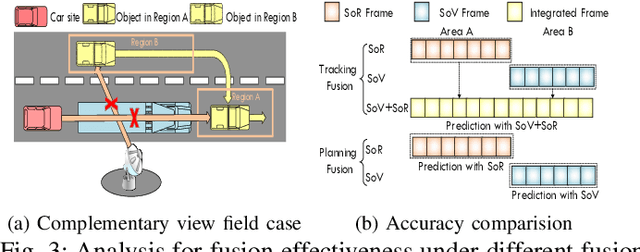

This paper is the first to provide a thorough system design overview along with the fusion methods selection criteria of a real-world cooperative autonomous driving system, named Infrastructure-Augmented Autonomous Driving or IAAD. We present an in-depth introduction of the IAAD hardware and software on both road-side and vehicle-side computing and communication platforms. We extensively characterize the IAAD system in the context of real-world deployment scenarios and observe that the network condition that fluctuates along the road is currently the main technical roadblock for cooperative autonomous driving. To address this challenge, we propose new fusion methods, dubbed "inter-frame fusion" and "planning fusion" to complement the current state-of-the-art "intra-frame fusion". We demonstrate that each fusion method has its own benefit and constraint.
Spatial Entropy Regularization for Vision Transformers
Jun 09, 2022

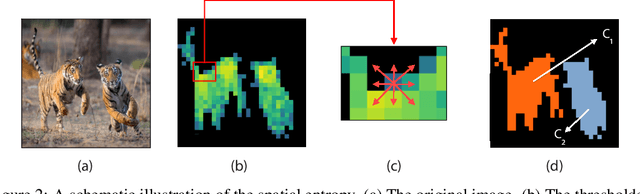
Recent work has shown that the attention maps of Vision Transformers (VTs), when trained with self-supervision, can contain a semantic segmentation structure which does not spontaneously emerge when training is supervised. In this paper, we explicitly encourage the emergence of this spatial clustering as a form of training regularization, this way including a self-supervised pretext task into the standard supervised learning. In more detail, we propose a VT regularization method based on a spatial formulation of the information entropy. By minimizing the proposed spatial entropy, we explicitly ask the VT to produce spatially ordered attention maps, this way including an object-based prior during training. Using extensive experiments, we show that the proposed regularization approach is beneficial with different training scenarios, datasets, downstream tasks and VT architectures. The code will be available upon acceptance.
Breaking the Chain of Gradient Leakage in Vision Transformers
May 25, 2022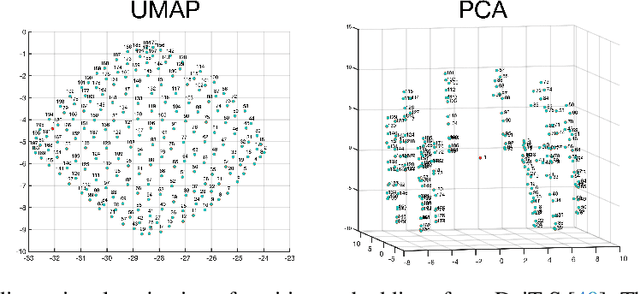
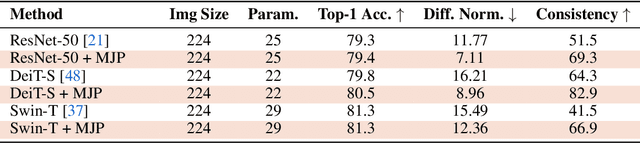
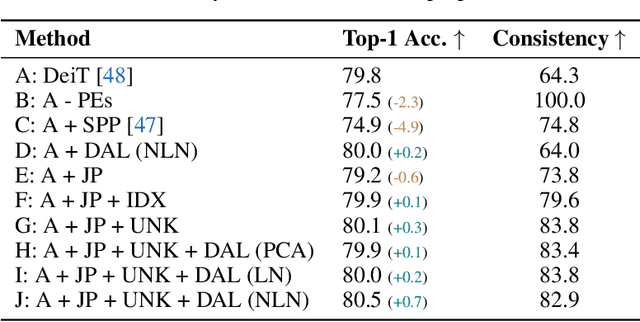
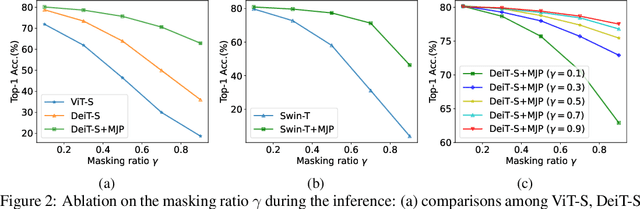
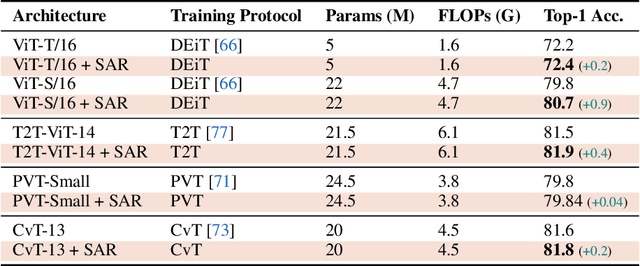
User privacy is of great concern in Federated Learning, while Vision Transformers (ViTs) have been revealed to be vulnerable to gradient-based inversion attacks. We show that the learned low-dimensional spatial prior in position embeddings (PEs) accelerates the training of ViTs. As a side effect, it makes the ViTs tend to be position sensitive and at high risk of privacy leakage. We observe that enhancing the position-insensitive property of a ViT model is a promising way to protect data privacy against these gradient attacks. However, simply removing the PEs may not only harm the convergence and accuracy of ViTs but also places the model at more severe privacy risk. To deal with the aforementioned contradiction, we propose a simple yet efficient Masked Jigsaw Puzzle (MJP) method to break the chain of gradient leakage in ViTs. MJP can be easily plugged into existing ViTs and their derived variants. Extensive experiments demonstrate that our proposed MJP method not only boosts the performance on large-scale datasets (i.e., ImageNet-1K), but can also improve the privacy preservation capacity in the typical gradient attacks by a large margin. Our code is available at: https://github.com/yhlleo/MJP.
MuCPAD: A Multi-Domain Chinese Predicate-Argument Dataset
May 13, 2022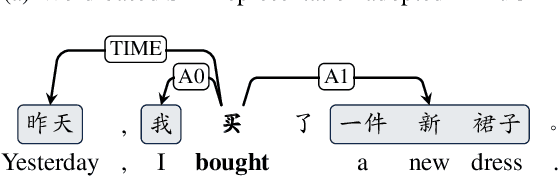
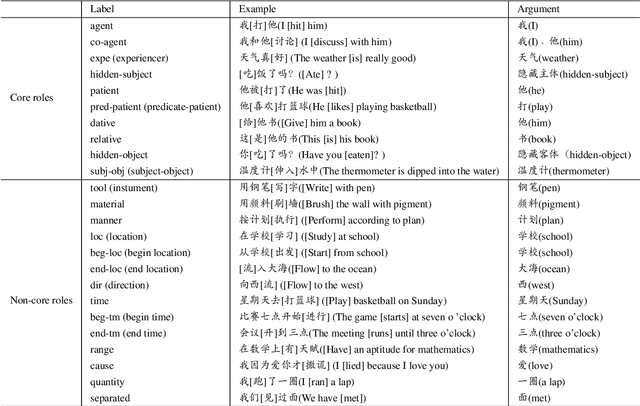

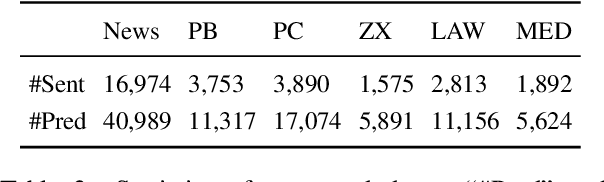
During the past decade, neural network models have made tremendous progress on in-domain semantic role labeling (SRL). However, performance drops dramatically under the out-of-domain setting. In order to facilitate research on cross-domain SRL, this paper presents MuCPAD, a multi-domain Chinese predicate-argument dataset, which consists of 30,897 sentences and 92,051 predicates from six different domains. MuCPAD exhibits three important features. 1) Based on a frame-free annotation methodology, we avoid writing complex frames for new predicates. 2) We explicitly annotate omitted core arguments to recover more complete semantic structure, considering that omission of content words is ubiquitous in multi-domain Chinese texts. 3) We compile 53 pages of annotation guidelines and adopt strict double annotation for improving data quality. This paper describes in detail the annotation methodology and annotation process of MuCPAD, and presents in-depth data analysis. We also give benchmark results on cross-domain SRL based on MuCPAD.
Language Models Can See: Plugging Visual Controls in Text Generation
May 05, 2022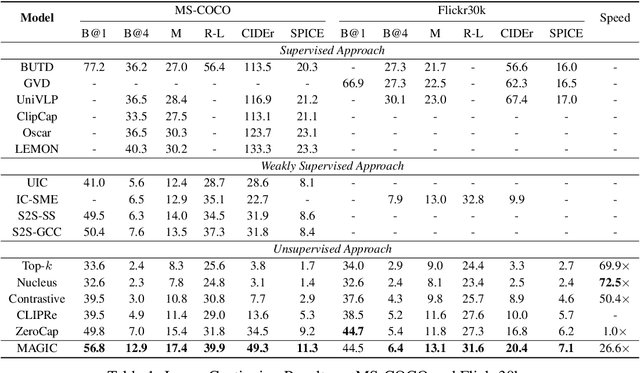

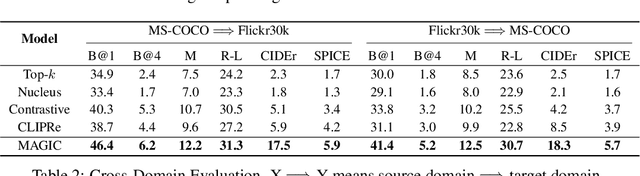

Generative language models (LMs) such as GPT-2/3 can be prompted to generate text with remarkable quality. While they are designed for text-prompted generation, it remains an open question how the generation process could be guided by modalities beyond text such as images. In this work, we propose a training-free framework, called MAGIC (iMAge-Guided text generatIon with CLIP), for plugging in visual controls in the generation process and enabling LMs to perform multimodal tasks (e.g., image captioning) in a zero-shot manner. MAGIC is a simple yet efficient plug-and-play framework, which directly combines an off-the-shelf LM (i.e., GPT-2) and an image-text matching model (i.e., CLIP) for image-grounded text generation. During decoding, MAGIC influences the generation of the LM by introducing a CLIP-induced score, called magic score, which regularizes the generated result to be semantically related to a given image while being coherent to the previously generated context. Notably, the proposed decoding scheme does not involve any gradient update operation, therefore being computationally efficient. On the challenging task of zero-shot image captioning, MAGIC outperforms the state-of-the-art method by notable margins with a nearly 27 times decoding speedup. MAGIC is a flexible framework and is theoretically compatible with any text generation tasks that incorporate image grounding. In the experiments, we showcase that it is also capable of performing visually grounded story generation given both an image and a text prompt.