 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaseous Object Detection
Feb 18, 2025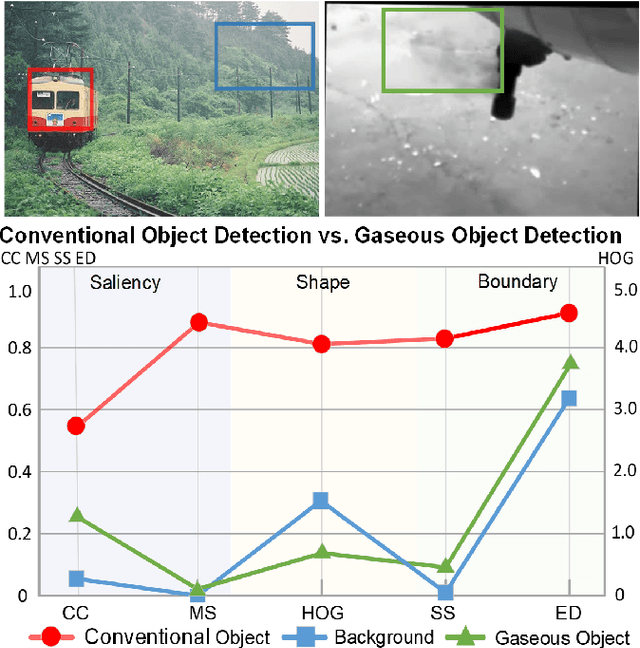



Object detection, a fundamental and challenging problem in computer vision, has experienced rapid development due to the effectiveness of deep learning. The current objects to be detected are mostly rigid solid substances with apparent and distinct visual characteristics. In this paper, we endeavor on a scarcely explored task named Gaseous Object Detection (GOD), which is undertaken to explore whether the object detection techniques can be extended from solid substances to gaseous substances. Nevertheless, the gas exhibits significantly different visual characteristics: 1) saliency deficiency, 2) arbitrary and ever-changing shapes, 3) lack of distinct boundaries. To facilitate the study on this challenging task, we construct a GOD-Video dataset comprising 600 videos (141,017 frames) that cover various attributes with multiple types of gases. A comprehensive benchmark is established based on this dataset, allowing for a rigorous evaluation of frame-level and video-level detectors. Deduced from the Gaussian dispersion model, the physics-inspired Voxel Shift Field (VSF) is designed to model geometric irregularities and ever-changing shapes in potential 3D space. By integrating VSF into Faster RCNN, the VSF RCNN serves as a simple but strong baseline for gaseous object detection. Our work aims to attract further research into this valuable albeit challenging area.
Flow Distillation Sampling: Regularizing 3D Gaussians with Pre-trained Matching Priors
Feb 11, 20253D Gaussian Splatting (3DGS) has achieved excellent rendering quality with fast training and rendering speed. However, its optimization process lacks explicit geometric constraints, leading to suboptimal geometric reconstruction in regions with sparse or no observational input views. In this work, we try to mitigate the issue by incorporating a pre-trained matching prior to the 3DGS optimization process. We introduce Flow Distillation Sampling (FDS), a technique that leverages pre-trained geometric knowledge to bolster the accuracy of the Gaussian radiance field. Our method employs a strategic sampling technique to target unobserved views adjacent to the input views, utilizing the optical flow calculated from the matching model (Prior Flow) to guide the flow analytically calculated from the 3DGS geometry (Radiance Flow). Comprehensive experiments in depth rendering, mesh reconstruction, and novel view synthesis showcase the significant advantages of FDS over state-of-the-art methods. Additionally, our interpretive experiments and analysis aim to shed light on the effects of FDS on geometric accuracy and rendering quality, potentially providing readers with insights into its performance. Project page: https://nju-3dv.github.io/projects/fds
Matrix3D: Large Photogrammetry Model All-in-One
Feb 11, 2025We present Matrix3D, a unified model that performs several photogrammetry subtasks, including pose estimation, depth prediction, and novel view synthesis using just the same model. Matrix3D utilizes a multi-modal diffusion transformer (DiT) to integrate transformations across several modalities, such as images, camera parameters, and depth maps. The key to Matrix3D's large-scale multi-modal training lies in the incorporation of a mask learning strategy. This enables full-modality model training even with partially complete data, such as bi-modality data of image-pose and image-depth pairs, thus significantly increases the pool of available training data. Matrix3D demonstrates state-of-the-art performance in pose estimation and novel view synthesis tasks. Additionally, it offers fine-grained control through multi-round interactions, making it an innovative tool for 3D content creation. Project page: https://nju-3dv.github.io/projects/matrix3d.
Joint Learning of Depth and Appearance for Portrait Image Animation
Jan 15, 20252D portrait animation has experienced significant advancements in recent years. Much research has utilized the prior knowledge embedded in large generative diffusion models to enhance high-quality image manipulation. However, most methods only focus on generating RGB images as output, and the co-generation of consistent visual plus 3D output remains largely under-explored. In our work, we propose to jointly learn the visual appearance and depth simultaneously in a diffusion-based portrait image generator. Our method embraces the end-to-end diffusion paradigm and introduces a new architecture suitable for learning this conditional joint distribution, consisting of a reference network and a channel-expanded diffusion backbone. Once trained, our framework can be efficiently adapted to various downstream applications, such as facial depth-to-image and image-to-depth generation, portrait relighting, and audio-driven talking head animation with consistent 3D output.
A Value Mapping Virtual Staining Framework for Large-scale Histological Imaging
Jan 07, 2025



The emergence of virtual staining technology provides a rapid and efficient alternative for researchers in tissue pathology. It enables the utilization of unlabeled microscopic samples to generate virtual replicas of chemically stained histological slices, or facilitate the transformation of one staining type into another. The remarkable performance of generative networks, such as CycleGAN, offers an unsupervised learning approach for virtual coloring, overcoming the limitations of high-quality paired data required in supervised learning. Nevertheless, large-scale color transformation necessitates processing large field-of-view images in patches, often resulting in significant boundary inconsistency and artifacts. Additionally, the transformation between different colorized modalities typically needs further efforts to modify loss functions and tune hyperparameters for independent training of networks. In this study, we introduce a general virtual staining framework that is adaptable to various conditions. We propose a loss function based on the value mapping constraint to ensure the accuracy of virtual coloring between different pathological modalities, termed the Value Mapping Generative Adversarial Network (VM-GAN). Meanwhile, we present a confidence-based tiling method to address the challenge of boundary inconsistency arising from patch-wise processing. Experimental results on diverse data with varying staining protocols demonstrate that our method achieves superior quantitative indicators and improved visual perception.
IDOL: Instant Photorealistic 3D Human Creation from a Single Image
Dec 19, 2024



Creating a high-fidelity, animatable 3D full-body avatar from a single image is a challenging task due to the diverse appearance and poses of humans and the limited availability of high-quality training data. To achieve fast and high-quality human reconstruction, this work rethinks the task from the perspectives of dataset, model, and representation. First, we introduce a large-scale HUman-centric GEnerated dataset, HuGe100K, consisting of 100K diverse, photorealistic sets of human images. Each set contains 24-view frames in specific human poses, generated using a pose-controllable image-to-multi-view model. Next, leveraging the diversity in views, poses, and appearances within HuGe100K, we develop a scalable feed-forward transformer model to predict a 3D human Gaussian representation in a uniform space from a given human image. This model is trained to disentangle human pose, body shape, clothing geometry, and texture. The estimated Gaussians can be animated without post-processing. We conduct comprehensive experiments to validate the effectiveness of the proposed dataset and method. Our model demonstrates the ability to efficiently reconstruct photorealistic humans at 1K resolution from a single input image using a single GPU instantly. Additionally, it seamlessly supports various applications, as well as shape and texture editing tasks.
MCMat: Multiview-Consistent and Physically Accurate PBR Material Generation
Dec 18, 2024



Existing 2D methods utilize UNet-based diffusion models to generate multi-view physically-based rendering (PBR) maps but struggle with multi-view inconsistency, while some 3D methods directly generate UV maps, encountering generalization issues due to the limited 3D data. To address these problems, we propose a two-stage approach, including multi-view generation and UV materials refinement. In the generation stage, we adopt a Diffusion Transformer (DiT) model to generate PBR materials, where both the specially designed multi-branch DiT and reference-based DiT blocks adopt a global attention mechanism to promote feature interaction and fusion between different views, thereby improving multi-view consistency. In addition, we adopt a PBR-based diffusion loss to ensure that the generated materials align with realistic physical principles. In the refinement stage, we propose a material-refined DiT that performs inpainting in empty areas and enhances details in UV space. Except for the normal condition, this refinement also takes the material map from the generation stage as an additional condition to reduce the learning difficulty and improve generalization. Extensive experiments show that our method achieves state-of-the-art performance in texturing 3D objects with PBR materials and provides significant advantages for graphics relighting applications. Project Page: https://lingtengqiu.github.io/2024/MCMat/
FATE: Full-head Gaussian Avatar with Textural Editing from Monocular Video
Nov 23, 2024



Reconstructing high-fidelity, animatable 3D head avatars from effortlessly captured monocular videos is a pivotal yet formidable challenge. Although significant progress has been made in rendering performance and manipulation capabilities, notable challenges remain, including incomplete reconstruction and inefficient Gaussian representation. To address these challenges, we introduce FATE, a novel method for reconstructing an editable full-head avatar from a single monocular video. FATE integrates a sampling-based densification strategy to ensure optimal positional distribution of points, improving rendering efficiency. A neural baking technique is introduced to convert discrete Gaussian representations into continuous attribute maps, facilitating intuitive appearance editing. Furthermore, we propose a universal completion framework to recover non-frontal appearance, culminating in a 360$^\circ$-renderable 3D head avatar. FATE outperforms previous approaches in both qualitative and quantitative evaluations, achieving state-of-the-art performance. To the best of our knowledge, FATE is the first animatable and 360$^\circ$ full-head monocular reconstruction method for a 3D head avatar. The code will be publicly released upon publication.
Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent
Nov 05, 2024



In this paper, we introduce Hunyuan-Large, which is currently the largest open-source Transformer-based mixture of experts model, with a total of 389 billion parameters and 52 billion activation parameters, capable of handling up to 256K tokens. We conduct a thorough evaluation of Hunyuan-Large's superior performance across various benchmarks including language understanding and generation, logical reasoning, mathematical problem-solving, coding, long-context, and aggregated tasks, where it outperforms LLama3.1-70B and exhibits comparable performance when compared to the significantly larger LLama3.1-405B model. Key practice of Hunyuan-Large include large-scale synthetic data that is orders larger than in previous literature, a mixed expert routing strategy, a key-value cache compression technique, and an expert-specific learning rate strategy. Additionally, we also investigate the scaling laws and learning rate schedule of mixture of experts models, providing valuable insights and guidances for future model development and optimization. The code and checkpoints of Hunyuan-Large are released to facilitate future innovations and applications. Codes: https://github.com/Tencent/Hunyuan-Large Models: https://huggingface.co/tencent/Tencent-Hunyuan-Large
Towards Native Generative Model for 3D Head Avatar
Oct 02, 2024



Creating 3D head avatars is a significant yet challenging task for many applicated scenarios. Previous studies have set out to learn 3D human head generative models using massive 2D image data. Although these models are highly generalizable for human appearance, their result models are not 360$^\circ$-renderable, and the predicted 3D geometry is unreliable. Therefore, such results cannot be used in VR, game modeling, and other scenarios that require 360$^\circ$-renderable 3D head models. An intuitive idea is that 3D head models with limited amount but high 3D accuracy are more reliable training data for a high-quality 3D generative model. In this vein, we delve into how to learn a native generative model for 360$^\circ$ full head from a limited 3D head dataset. Specifically, three major problems are studied: 1) how to effectively utilize various representations for generating the 360$^\circ$-renderable human head; 2) how to disentangle the appearance, shape, and motion of human faces to generate a 3D head model that can be edited by appearance and driven by motion; 3) and how to extend the generalization capability of the generative model to support downstream tasks. Comprehensive experiments are conducted to verify the effectiveness of the proposed model. We hope the proposed models and artist-designed dataset can inspire future research on learning native generative 3D head models from limited 3D datasets.