 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAEQ-Bench: Measuring Empathy of Omni-Modal Large Models
Jan 15, 2026While the automatic evaluation of omni-modal large models (OLMs) is essential, assessing empathy remains a significant challenge due to its inherent affectivity. To investigate this challenge, we introduce AEQ-Bench (Audio Empathy Quotient Benchmark), a novel benchmark to systematically assess two core empathetic capabilities of OLMs: (i) generating empathetic responses by comprehending affective cues from multi-modal inputs (audio + text), and (ii) judging the empathy of audio responses without relying on text transcription. Compared to existing benchmarks, AEQ-Bench incorporates two novel settings that vary in context specificity and speech tone. Comprehensive assessment across linguistic and paralinguistic metrics reveals that (1) OLMs trained with audio output capabilities generally outperformed models with text-only outputs, and (2) while OLMs align with human judgments for coarse-grained quality assessment, they remain unreliable for evaluating fine-grained paralinguistic expressiveness.
Learning When Not to Attend Globally
Dec 27, 2025When reading books, humans focus primarily on the current page, flipping back to recap prior context only when necessary. Similarly, we demonstrate that Large Language Models (LLMs) can learn to dynamically determine when to attend to global context. We propose All-or-Here Attention (AHA), which utilizes a binary router per attention head to dynamically toggle between full attention and local sliding window attention for each token. Our results indicate that with a window size of 256 tokens, up to 93\% of the original full attention operations can be replaced by sliding window attention without performance loss. Furthermore, by evaluating AHA across various window sizes, we identify a long-tail distribution in context dependency, where the necessity for full attention decays rapidly as the local window expands. By decoupling local processing from global access, AHA reveals that full attention is largely redundant, and that efficient inference requires only on-demand access to the global context.
Scaling Transformer-Based Novel View Synthesis Models with Token Disentanglement and Synthetic Data
Sep 08, 2025Large transformer-based models have made significant progress in generalizable novel view synthesis (NVS) from sparse input views, generating novel viewpoints without the need for test-time optimization. However, these models are constrained by the limited diversity of publicly available scene datasets, making most real-world (in-the-wild) scenes out-of-distribution. To overcome this, we incorporate synthetic training data generated from diffusion models, which improves generalization across unseen domains. While synthetic data offers scalability, we identify artifacts introduced during data generation as a key bottleneck affecting reconstruction quality. To address this, we propose a token disentanglement process within the transformer architecture, enhancing feature separation and ensuring more effective learning. This refinement not only improves reconstruction quality over standard transformers but also enables scalable training with synthetic data. As a result, our method outperforms existing models on both in-dataset and cross-dataset evaluations, achieving state-of-the-art results across multiple benchmarks while significantly reducing computational costs. Project page: https://scaling3dnvs.github.io/
Adaptive Layer-skipping in Pre-trained LLMs
Mar 31, 2025
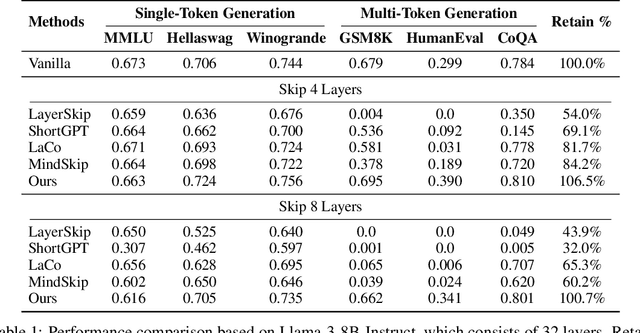
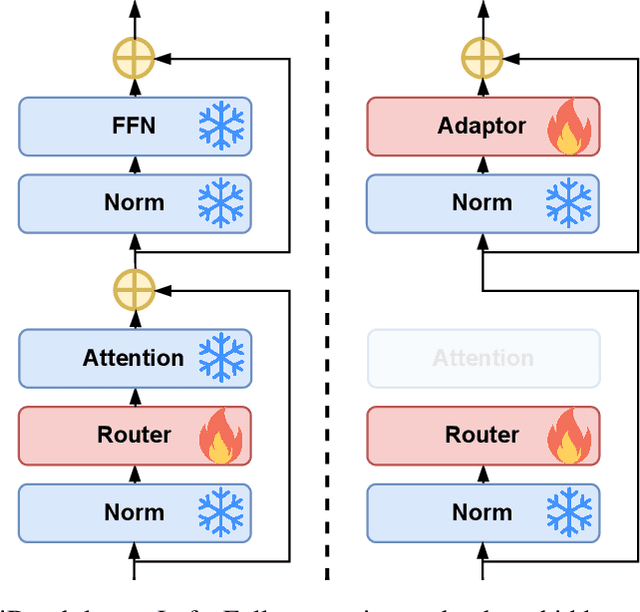
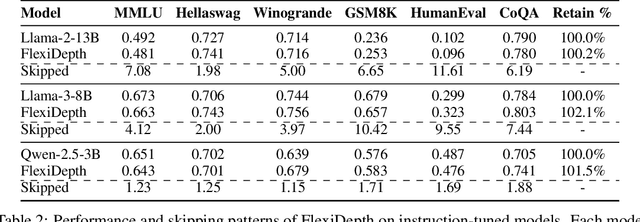
Various layer-skipping methods have been proposed to accelerate token generation in large language models (LLMs). However, they have overlooked a fundamental question: How do computational demands vary across the generation of different tokens? In this work, we introduce FlexiDepth, a method that dynamically adjusts the number of Transformer layers used in text generation. By incorporating a plug-in router and adapter, FlexiDepth enables adaptive layer-skipping in LLMs without modifying their original parameters. Introducing FlexiDepth to Llama-3-8B model achieves layer skipping of 8 layers out of 32, and meanwhile maintains the full 100\% benchmark performance. Experimental results with FlexiDepth demonstrate that computational demands in LLMs significantly vary based on token type. Specifically, generating repetitive tokens or fixed phrases requires fewer layers, whereas producing tokens involving computation or high uncertainty requires more layers. Interestingly, this adaptive allocation pattern aligns with human intuition. To advance research in this area, we open sourced FlexiDepth and a dataset documenting FlexiDepth's layer allocation patterns for future exploration.
FastCuRL: Curriculum Reinforcement Learning with Progressive Context Extension for Efficient Training R1-like Reasoning Models
Mar 21, 2025In this paper, we propose \textbf{\textsc{FastCuRL}}, a simple yet efficient \textbf{Cu}rriculum \textbf{R}einforcement \textbf{L}earning approach with context window extending strategy to accelerate the reinforcement learning training efficiency for R1-like reasoning models while enhancing their performance in tackling complex reasoning tasks with long chain-of-thought rationales, particularly with a 1.5B parameter language model. \textbf{\textsc{FastCuRL}} consists of two main procedures: length-aware training data segmentation and context window extension training. Specifically, the former first splits the original training data into three different levels by the input prompt length, and then the latter leverages segmented training datasets with a progressively increasing context window length to train the reasoning model. Experimental results demonstrate that \textbf{\textsc{FastCuRL}}-1.5B-Preview surpasses DeepScaleR-1.5B-Preview across all five datasets (including MATH 500, AIME 2024, AMC 2023, Minerva Math, and OlympiadBench) while only utilizing 50\% of training steps. Furthermore, all training stages for FastCuRL-1.5B-Preview are completed using just a single node with 8 GPUs.
SplatVoxel: History-Aware Novel View Streaming without Temporal Training
Mar 18, 2025We study the problem of novel view streaming from sparse-view videos, which aims to generate a continuous sequence of high-quality, temporally consistent novel views as new input frames arrive. However, existing novel view synthesis methods struggle with temporal coherence and visual fidelity, leading to flickering and inconsistency. To address these challenges, we introduce history-awareness, leveraging previous frames to reconstruct the scene and improve quality and stability. We propose a hybrid splat-voxel feed-forward scene reconstruction approach that combines Gaussian Splatting to propagate information over time, with a hierarchical voxel grid for temporal fusion. Gaussian primitives are efficiently warped over time using a motion graph that extends 2D tracking models to 3D motion, while a sparse voxel transformer integrates new temporal observations in an error-aware manner. Crucially, our method does not require training on multi-view video datasets, which are currently limited in size and diversity, and can be directly applied to sparse-view video streams in a history-aware manner at inference time. Our approach achieves state-of-the-art performance in both static and streaming scene reconstruction, effectively reducing temporal artifacts and visual artifacts while running at interactive rates (15 fps with 350ms delay) on a single H100 GPU. Project Page: https://19reborn.github.io/SplatVoxel/
GRP: Goal-Reversed Prompting for Zero-Shot Evaluation with LLMs
Mar 08, 2025Using Large Language Models (LLMs) to evaluate and compare two answers from different models typically involves having LLM-based judges select the better answer. However, humans often approach problem-solving from a reverse perspective, for instance, by choosing the worse option instead of the better one in a pairwise comparison. Generally, this kind of reverse thinking plays a crucial role in human reasoning and decision-making and can further test the difference between original and reverse thought processes simultaneously. To address the above issue, in this paper, we propose a Goal-Reversed Prompting (GRP) approach for pairwise evaluation that shifts the original task from selecting the better answer to choosing the worse one. We encourage LLMs to think in reverse by prompting LLMs to identify the worse response. Experiments on closed-source models demonstrate that GRP significantly enhances evaluation capabilities, outperforming the prompt template with the original goal.
Quark: Real-time, High-resolution, and General Neural View Synthesis
Nov 25, 2024We present a novel neural algorithm for performing high-quality, high-resolution, real-time novel view synthesis. From a sparse set of input RGB images or videos streams, our network both reconstructs the 3D scene and renders novel views at 1080p resolution at 30fps on an NVIDIA A100. Our feed-forward network generalizes across a wide variety of datasets and scenes and produces state-of-the-art quality for a real-time method. Our quality approaches, and in some cases surpasses, the quality of some of the top offline methods. In order to achieve these results we use a novel combination of several key concepts, and tie them together into a cohesive and effective algorithm. We build on previous works that represent the scene using semi-transparent layers and use an iterative learned render-and-refine approach to improve those layers. Instead of flat layers, our method reconstructs layered depth maps (LDMs) that efficiently represent scenes with complex depth and occlusions. The iterative update steps are embedded in a multi-scale, UNet-style architecture to perform as much compute as possible at reduced resolution. Within each update step, to better aggregate the information from multiple input views, we use a specialized Transformer-based network component. This allows the majority of the per-input image processing to be performed in the input image space, as opposed to layer space, further increasing efficiency. Finally, due to the real-time nature of our reconstruction and rendering, we dynamically create and discard the internal 3D geometry for each frame, generating the LDM for each view. Taken together, this produces a novel and effective algorithm for view synthesis. Through extensive evaluation, we demonstrate that we achieve state-of-the-art quality at real-time rates. Project page: https://quark-3d.github.io/
Can Many-Shot In-Context Learning Help Long-Context LLM Judges? See More, Judge Better!
Jun 17, 2024



Leveraging Large Language Models (LLMs) as judges for evaluating the performance of LLMs has recently garnered attention. Nonetheless, this type of approach concurrently introduces potential biases from LLMs, raising concerns about the reliability of the evaluation results. To mitigate this issue, we propose and study two versions of many-shot in-context prompts, Reinforced and Unsupervised ICL, for helping GPT-4o-as-a-Judge in single answer grading. Based on the designed prompts, we investigate the impact of scaling the number of in-context examples on the agreement and quality of the evaluation. Furthermore, we first reveal the symbol bias in GPT-4o-as-a-Judge for pairwise comparison and then propose a simple yet effective approach to mitigate it. Experimental results show that advanced long-context LLMs, such as GPT-4o, perform better in the many-shot regime than in the zero-shot regime. Meanwhile, the experimental results further verify the effectiveness of the symbol bias mitigation approach.
Learning 1D Causal Visual Representation with De-focus Attention Networks
Jun 06, 2024Modality differences have led to the development of heterogeneous architectures for vision and language models. While images typically require 2D non-causal modeling, texts utilize 1D causal modeling. This distinction poses significant challenges in constructing unified multi-modal models. This paper explores the feasibility of representing images using 1D causal modeling. We identify an "over-focus" issue in existing 1D causal vision models, where attention overly concentrates on a small proportion of visual tokens. The issue of "over-focus" hinders the model's ability to extract diverse visual features and to receive effective gradients for optimization. To address this, we propose De-focus Attention Networks, which employ learnable bandpass filters to create varied attention patterns. During training, large and scheduled drop path rates, and an auxiliary loss on globally pooled features for global understanding tasks are introduced. These two strategies encourage the model to attend to a broader range of tokens and enhance network optimization. Extensive experiments validate the efficacy of our approach, demonstrating that 1D causal visual representation can perform comparably to 2D non-causal representation in tasks such as global perception, dense prediction, and multi-modal understanding. Code is released at https://github.com/OpenGVLab/De-focus-Attention-Networks.