 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVidTwin: Video VAE with Decoupled Structure and Dynamics
Dec 23, 2024Recent advancements in video autoencoders (Video AEs) have significantly improved the quality and efficiency of video generation. In this paper, we propose a novel and compact video autoencoder, VidTwin, that decouples video into two distinct latent spaces: Structure latent vectors, which capture overall content and global movement, and Dynamics latent vectors, which represent fine-grained details and rapid movements. Specifically, our approach leverages an Encoder-Decoder backbone, augmented with two submodules for extracting these latent spaces, respectively. The first submodule employs a Q-Former to extract low-frequency motion trends, followed by downsampling blocks to remove redundant content details. The second averages the latent vectors along the spatial dimension to capture rapid motion. Extensive experiments show that VidTwin achieves a high compression rate of 0.20% with high reconstruction quality (PSNR of 28.14 on the MCL-JCV dataset), and performs efficiently and effectively in downstream generative tasks. Moreover, our model demonstrates explainability and scalability, paving the way for future research in video latent representation and generation. Our code has been released at https://github.com/microsoft/VidTok/tree/main/vidtwin.
PunchBench: Benchmarking MLLMs in Multimodal Punchline Comprehension
Dec 16, 2024



Multimodal punchlines, which involve humor or sarcasm conveyed in image-caption pairs, are a popular way of communication on online multimedia platforms. With the rapid development of multimodal large language models (MLLMs), it is essential to assess their ability to effectively comprehend these punchlines. However, existing benchmarks on punchline comprehension suffer from three major limitations: 1) language shortcuts that allow models to solely rely on text, 2) lack of question diversity, and 3) narrow focus on a specific domain of multimodal content (e.g., cartoon). To address these limitations, we introduce a multimodal \textbf{Punch}line comprehension \textbf{Bench}mark, named \textbf{PunchBench}, which is tailored for accurate and comprehensive evaluation of punchline comprehension. To enhance the evaluation accuracy, we generate synonymous and antonymous captions by modifying original captions, which mitigates the impact of shortcuts in the captions. To provide a comprehensive evaluation, PunchBench incorporates diverse question formats and image-captions from various domains. On this basis, we conduct extensive evaluations and reveal a significant gap between state-of-the-art MLLMs and humans in punchline comprehension. To improve punchline comprehension, we propose Simple-to-Complex Chain-of-Question (SC-CoQ) strategy, enabling the models to incrementally address complicated questions by first mastering simple ones. SC-CoQ effectively enhances the performance of various MLLMs on PunchBench, surpassing in-context learning and chain-of-thought.
Hyperspectral Image Cross-Domain Object Detection Method based on Spectral-Spatial Feature Alignment
Nov 25, 2024



With consecutive bands in a wide range of wavelengths, hyperspectral images (HSI) have provided a unique tool for object detection task. However, existing HSI object detection methods have not been fully utilized in real applications, which is mainly resulted by the difference of spatial and spectral resolution between the unlabeled target domain and a labeled source domain, i.e. the domain shift of HSI. In this work, we aim to explore the unsupervised cross-domain object detection of HSI. Our key observation is that the local spatial-spectral characteristics remain invariant across different domains. For solving the problem of domain-shift, we propose a HSI cross-domain object detection method based on spectral-spatial feature alignment, which is the first attempt in the object detection community to the best of our knowledge. Firstly, we develop a spectral-spatial alignment module to extract domain-invariant local spatial-spectral features. Secondly, the spectral autocorrelation module has been designed to solve the domain shift in the spectral domain specifically, which can effectively align HSIs with different spectral resolutions. Besides, we have collected and annotated an HSI dataset for the cross-domain object detection. Our experimental results have proved the effectiveness of HSI cross-domain object detection, which has firstly demonstrated a significant and promising step towards HSI cross-domain object detection in the object detection community.
Unveiling Molecular Secrets: An LLM-Augmented Linear Model for Explainable and Calibratable Molecular Property Prediction
Oct 11, 2024



Explainable molecular property prediction is essential for various scientific fields, such as drug discovery and material science. Despite delivering intrinsic explainability, linear models struggle with capturing complex, non-linear patterns. Large language models (LLMs), on the other hand, yield accurate predictions through powerful inference capabilities yet fail to provide chemically meaningful explanations for their predictions. This work proposes a novel framework, called MoleX, which leverages LLM knowledge to build a simple yet powerful linear model for accurate molecular property prediction with faithful explanations. The core of MoleX is to model complicated molecular structure-property relationships using a simple linear model, augmented by LLM knowledge and a crafted calibration strategy. Specifically, to extract the maximum amount of task-relevant knowledge from LLM embeddings, we employ information bottleneck-inspired fine-tuning and sparsity-inducing dimensionality reduction. These informative embeddings are then used to fit a linear model for explainable inference. Moreover, we introduce residual calibration to address prediction errors stemming from linear models' insufficient expressiveness of complex LLM embeddings, thus recovering the LLM's predictive power and boosting overall accuracy. Theoretically, we provide a mathematical foundation to justify MoleX's explainability. Extensive experiments demonstrate that MoleX outperforms existing methods in molecular property prediction, establishing a new milestone in predictive performance, explainability, and efficiency. In particular, MoleX enables CPU inference and accelerates large-scale dataset processing, achieving comparable performance 300x faster with 100,000 fewer parameters than LLMs. Additionally, the calibration improves model performance by up to 12.7% without compromising explainability.
Temporal Reasoning Transfer from Text to Video
Oct 08, 2024



Video Large Language Models (Video LLMs) have shown promising capabilities in video comprehension, yet they struggle with tracking temporal changes and reasoning about temporal relationships. While previous research attributed this limitation to the ineffective temporal encoding of visual inputs, our diagnostic study reveals that video representations contain sufficient information for even small probing classifiers to achieve perfect accuracy. Surprisingly, we find that the key bottleneck in Video LLMs' temporal reasoning capability stems from the underlying LLM's inherent difficulty with temporal concepts, as evidenced by poor performance on textual temporal question-answering tasks. Building on this discovery, we introduce the Textual Temporal reasoning Transfer (T3). T3 synthesizes diverse temporal reasoning tasks in pure text format from existing image-text datasets, addressing the scarcity of video samples with complex temporal scenarios. Remarkably, without using any video data, T3 enhances LongVA-7B's temporal understanding, yielding a 5.3 absolute accuracy improvement on the challenging TempCompass benchmark, which enables our model to outperform ShareGPT4Video-8B trained on 28,000 video samples. Additionally, the enhanced LongVA-7B model achieves competitive performance on comprehensive video benchmarks. For example, it achieves a 49.7 accuracy on the Temporal Reasoning task of Video-MME, surpassing powerful large-scale models such as InternVL-Chat-V1.5-20B and VILA1.5-40B. Further analysis reveals a strong correlation between textual and video temporal task performance, validating the efficacy of transferring temporal reasoning abilities from text to video domains.
Enhancing Data Quality through Self-learning on Imbalanced Financial Risk Data
Sep 15, 2024



In the financial risk domain, particularly in credit default prediction and fraud detection, accurate identification of high-risk class instances is paramount, as their occurrence can have significant economic implications. Although machine learning models have gained widespread adoption for risk prediction, their performance is often hindered by the scarcity and diversity of high-quality data. This limitation stems from factors in datasets such as small risk sample sizes, high labeling costs, and severe class imbalance, which impede the models' ability to learn effectively and accurately forecast critical events. This study investigates data pre-processing techniques to enhance existing financial risk datasets by introducing TriEnhance, a straightforward technique that entails: (1) generating synthetic samples specifically tailored to the minority class, (2) filtering using binary feedback to refine samples, and (3) self-learning with pseudo-labels. Our experiments across six benchmark datasets reveal the efficacy of TriEnhance, with a notable focus on improving minority class calibration, a key factor for developing more robust financial risk prediction systems.
Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts
Aug 28, 2024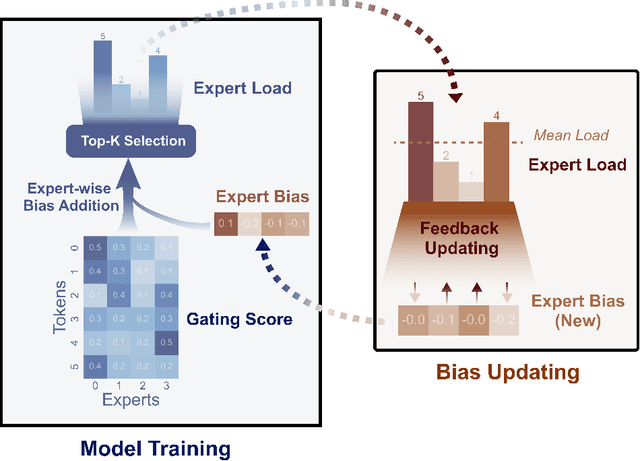
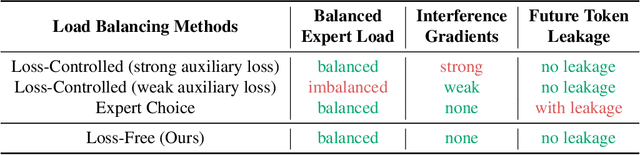
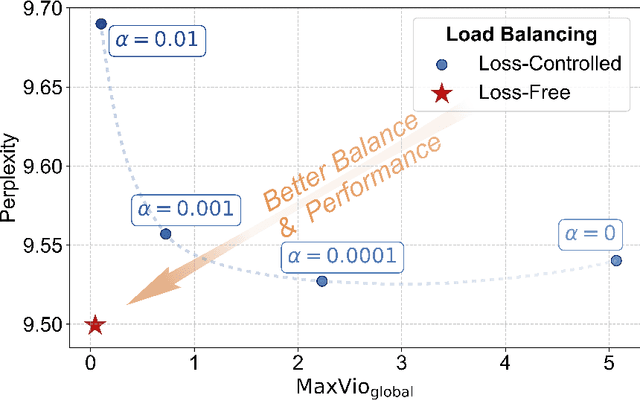
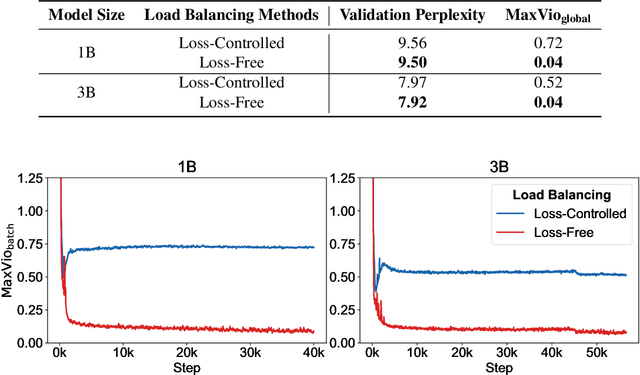
For Mixture-of-Experts (MoE) models, an unbalanced expert load will lead to routing collapse or increased computational overhead. Existing methods commonly employ an auxiliary loss to encourage load balance, but a large auxiliary loss will introduce non-negligible interference gradients into training and thus impair the model performance. In order to control load balance while not producing undesired gradients during training, we propose Loss-Free Balancing, featured by an auxiliary-loss-free load balancing strategy. To be specific, before the top-K routing decision, Loss-Free Balancing will first apply an expert-wise bias to the routing scores of each expert. By dynamically updating the bias of each expert according to its recent load, Loss-Free Balancing can consistently maintain a balanced distribution of expert load. In addition, since Loss-Free Balancing does not produce any interference gradients, it also elevates the upper bound of model performance gained from MoE training. We validate the performance of Loss-Free Balancing on MoE models with up to 3B parameters trained on up to 200B tokens. Experimental results show that Loss-Free Balancing achieves both better performance and better load balance compared with traditional auxiliary-loss-controlled load balancing strategies.
DeCo: Decoupling Token Compression from Semantic Abstraction in Multimodal Large Language Models
May 31, 2024



The visual projector, which bridges the vision and language modalities and facilitates cross-modal alignment, serves as a crucial component in MLLMs. However, measuring the effectiveness of projectors in vision-language alignment remains under-explored, which currently can only be inferred from the performance of MLLMs on downstream tasks. Motivated by the problem, this study examines the projector module by interpreting the vision-language semantic flow within MLLMs. Specifically, we trace back the semantic relevance flow from generated language tokens to raw visual encoder patches and the intermediate outputs produced by projectors. Our findings reveal that compressive projectors (e.g., QFormer), abstract visual patches into a limited set of semantic concepts, such as objects or attributes, resulting in a 'double abstraction' phenomenon. This involves a first visual semantic abstraction by the projector referring to pre-defined query tokens, and a second extraction by the LLM based on text instructions. The double abstraction is inefficient in training and will result in cumulative vision semantics deficiency. To mitigate this issue, we propose the key insight of 'Decouple Compression from Abstraction (DeCo), that is compressing the visual token number at the patch level by projectors and allowing the LLM to handle visual semantic abstraction entirely. Consequently, we adopt a simple compressor, i.e., 2D Adaptive Pooling, to downsample visual patches in a parameter-free manner. Empirical evaluation demonstrates that DeCo surpasses traditional compressive projectors regarding both performance and efficiency. It achieves performance gains of 0.9%, 7.1%, and 2.9% across the MLLM Benchmarks, Visual Localization, and Open-ended VQA tasks with fewer trainable parameters and faster convergence speed.
InstructAvatar: Text-Guided Emotion and Motion Control for Avatar Generation
May 24, 2024



Recent talking avatar generation models have made strides in achieving realistic and accurate lip synchronization with the audio, but often fall short in controlling and conveying detailed expressions and emotions of the avatar, making the generated video less vivid and controllable. In this paper, we propose a novel text-guided approach for generating emotionally expressive 2D avatars, offering fine-grained control, improved interactivity, and generalizability to the resulting video. Our framework, named InstructAvatar, leverages a natural language interface to control the emotion as well as the facial motion of avatars. Technically, we design an automatic annotation pipeline to construct an instruction-video paired training dataset, equipped with a novel two-branch diffusion-based generator to predict avatars with audio and text instructions at the same time. Experimental results demonstrate that InstructAvatar produces results that align well with both conditions, and outperforms existing methods in fine-grained emotion control, lip-sync quality, and naturalness. Our project page is https://wangyuchi369.github.io/InstructAvatar/.
LaDiC: Are Diffusion Models Really Inferior to Autoregressive Counterparts for Image-to-Text Generation?
Apr 16, 2024



Diffusion models have exhibited remarkable capabilities in text-to-image generation. However, their performance in image-to-text generation, specifically image captioning, has lagged behind Auto-Regressive (AR) models, casting doubt on their applicability for such tasks. In this work, we revisit diffusion models, highlighting their capacity for holistic context modeling and parallel decoding. With these benefits, diffusion models can alleviate the inherent limitations of AR methods, including their slow inference speed, error propagation, and unidirectional constraints. Furthermore, we identify the prior underperformance of diffusion models stemming from the absence of an effective latent space for image-text alignment, and the discrepancy between continuous diffusion processes and discrete textual data. In response, we introduce a novel architecture, LaDiC, which utilizes a split BERT to create a dedicated latent space for captions and integrates a regularization module to manage varying text lengths. Our framework also includes a diffuser for semantic image-to-text conversion and a Back&Refine technique to enhance token interactivity during inference. LaDiC achieves state-of-the-art performance for diffusion-based methods on the MS COCO dataset with 38.2 BLEU@4 and 126.2 CIDEr, demonstrating exceptional performance without pre-training or ancillary modules. This indicates strong competitiveness with AR models, revealing the previously untapped potential of diffusion models in image-to-text generation.