 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImitation Learning for Non-Autoregressive Neural Machine Translation
Jul 18, 2019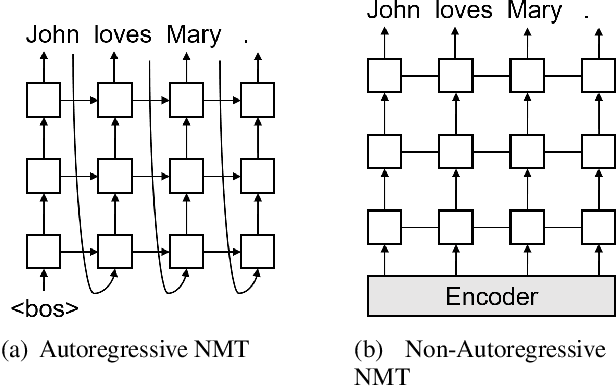
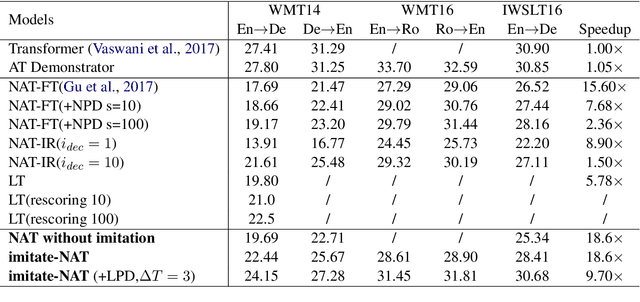
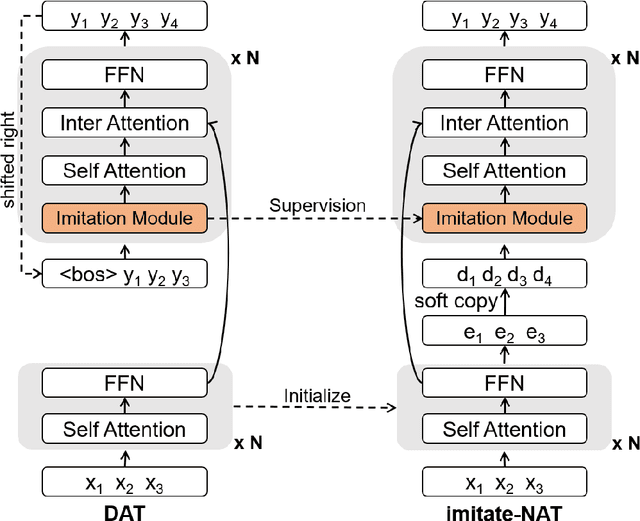
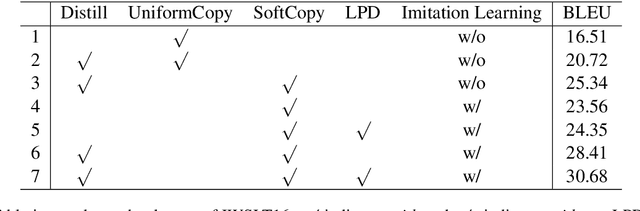
Non-autoregressive translation models (NAT) have achieved impressive inference speedup. A potential issue of the existing NAT algorithms, however, is that the decoding is conducted in parallel, without directly considering previous context. In this paper, we propose an imitation learning framework for non-autoregressive machine translation, which still enjoys the fast translation speed but gives comparable translation performance compared to its auto-regressive counterpart. We conduct experiments on the IWSLT16, WMT14 and WMT16 datasets. Our proposed model achieves a significant speedup over the autoregressive models, while keeping the translation quality comparable to the autoregressive models. By sampling sentence length in parallel at inference time, we achieve the performance of 31.85 BLEU on WMT16 Ro$\rightarrow$En and 30.68 BLEU on IWSLT16 En$\rightarrow$De.
PKUSEG: A Toolkit for Multi-Domain Chinese Word Segmentation
Jun 28, 2019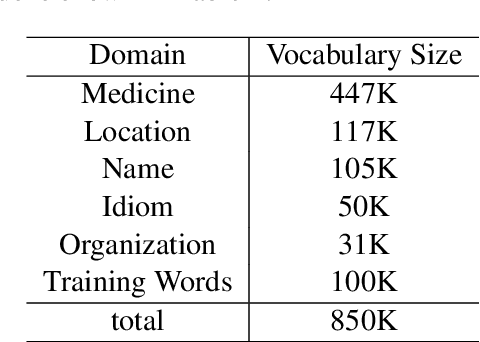


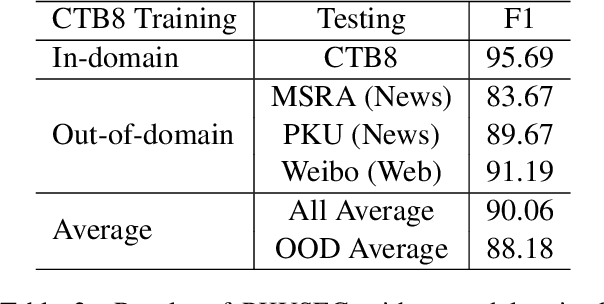
Chinese word segmentation (CWS) is a fundamental step of Chinese natural language processing. In this paper, we build a new toolkit, named PKUSEG, for multi-domain word segmentation. Unlike existing single-model toolkits, PKUSEG targets at multi-domain word segmentation and provides separate models for different domains, such as web, medicine, and tourism. The new toolkit also supports POS tagging and model training to adapt to various application scenarios. Experiments show that PKUSEG achieves high performance on multiple domains. The toolkit is now freely and publicly available for the usage of research and industry.
A Hierarchical Reinforced Sequence Operation Method for Unsupervised Text Style Transfer
Jun 05, 2019Unsupervised text style transfer aims to alter text styles while preserving the content, without aligned data for supervision. Existing seq2seq methods face three challenges: 1) the transfer is weakly interpretable, 2) generated outputs struggle in content preservation, and 3) the trade-off between content and style is intractable. To address these challenges, we propose a hierarchical reinforced sequence operation method, named Point-Then-Operate (PTO), which consists of a high-level agent that proposes operation positions and a low-level agent that alters the sentence. We provide comprehensive training objectives to control the fluency, style, and content of the outputs and a mask-based inference algorithm that allows for multi-step revision based on the single-step trained agents. Experimental results on two text style transfer datasets show that our method significantly outperforms recent methods and effectively addresses the aforementioned challenges.
Memorized Sparse Backpropagation
Jun 01, 2019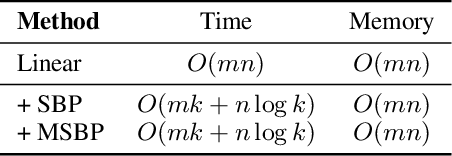

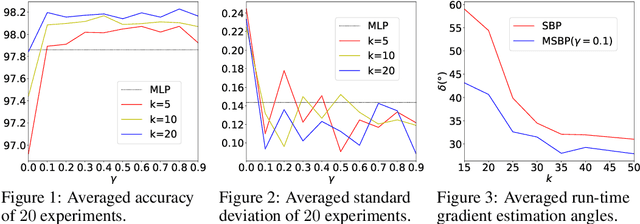

Neural network learning is typically slow since backpropagation needs to compute full gradients and backpropagate them across multiple layers. Despite its success of existing work in accelerating propagation through sparseness, the relevant theoretical characteristics remain unexplored and we empirically find that they suffer from the loss of information contained in unpropagated gradients. To tackle these problems, in this work, we present a unified sparse backpropagation framework and provide a detailed analysis of its theoretical characteristics. Analysis reveals that when applied to a multilayer perceptron, our framework essentially performs gradient descent using an estimated gradient similar enough to the true gradient, resulting in convergence in probability under certain conditions. Furthermore, a simple yet effective algorithm named memorized sparse backpropagation (MSBP) is proposed to remedy the problem of information loss by storing unpropagated gradients in memory for the next learning. The experiments demonstrate that the proposed MSBP is able to effectively alleviate the information loss in traditional sparse backpropagation while achieving comparable acceleration.
Aligning Visual Regions and Textual Concepts: Learning Fine-Grained Image Representations for Image Captioning
May 26, 2019
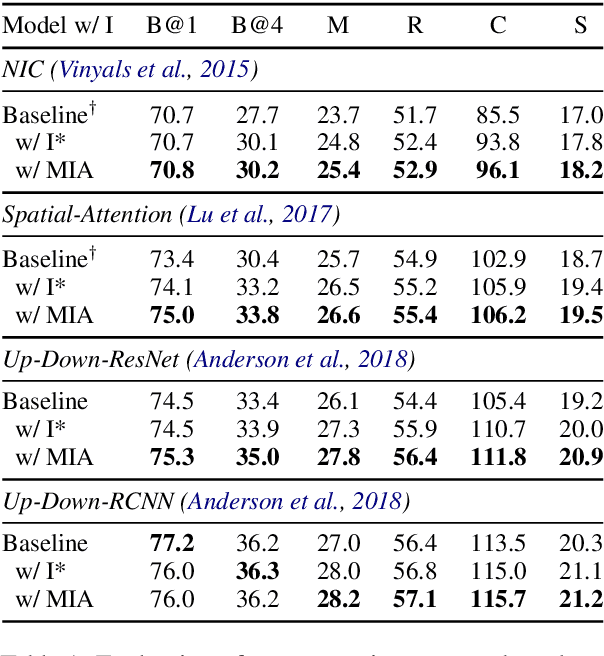
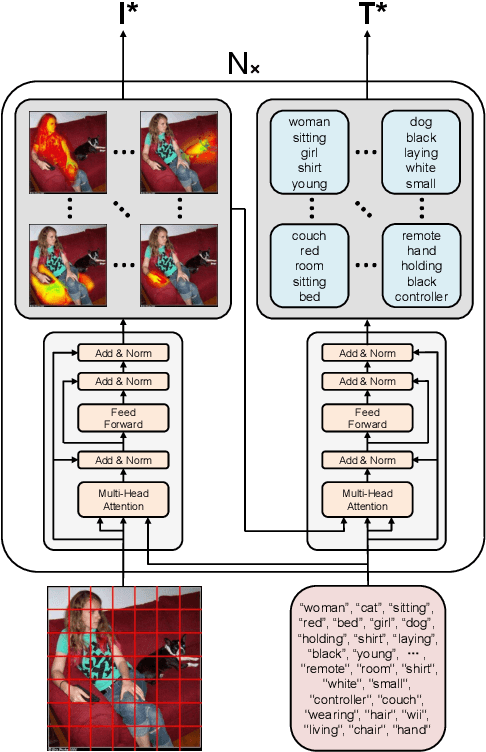
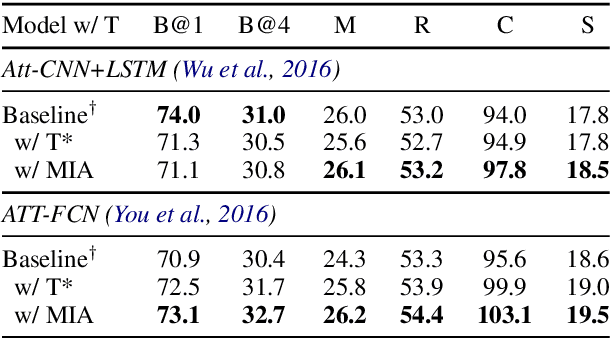
In image-grounded text generation, fine-grained representations of the image are considered to be of paramount importance. Most of the current systems incorporate visual features and textual concepts as a sketch of an image. However, plainly inferred representations are usually undesirable in that they are composed of separate components, the relations of which are elusive. In this work, we aim at representing an image with a set of integrated visual regions and corresponding textual concepts. To this end, we build the Mutual Iterative Attention (MIA) module, which integrates correlated visual features and textual concepts, respectively, by aligning the two modalities. We evaluate the proposed approach on the COCO dataset for image captioning. Extensive experiments show that the refined image representations boost the baseline models by up to 12% in terms of CIDEr, demonstrating that our method is effective and generalizes well to a wide range of models.
A Dual Reinforcement Learning Framework for Unsupervised Text Style Transfer
May 24, 2019
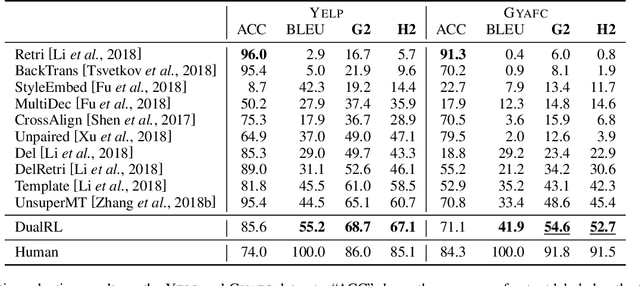
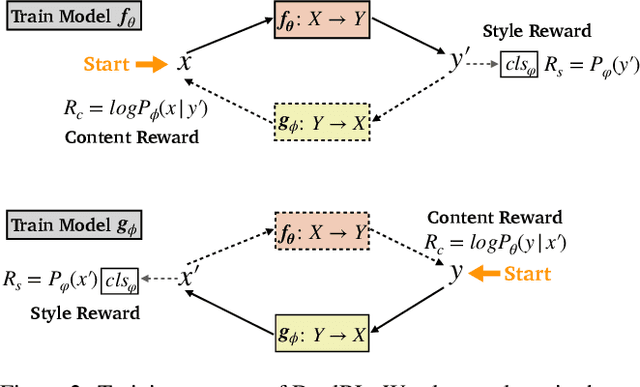
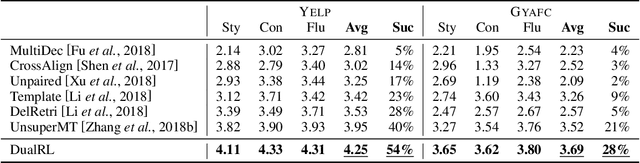
Unsupervised text style transfer aims to transfer the underlying style of text but keep its main content unchanged without parallel data. Most existing methods typically follow two steps: first separating the content from the original style, and then fusing the content with the desired style. However, the separation in the first step is challenging because the content and style interact in subtle ways in natural language. Therefore, in this paper, we propose a dual reinforcement learning framework to directly transfer the style of the text via a one-step mapping model, without any separation of content and style. Specifically, we consider the learning of the source-to-target and target-to-source mappings as a dual task, and two rewards are designed based on such a dual structure to reflect the style accuracy and content preservation, respectively. In this way, the two one-step mapping models can be trained via reinforcement learning, without any use of parallel data. Automatic evaluations show that our model outperforms the state-of-the-art systems by a large margin, especially with more than 8 BLEU points improvement averaged on two benchmark datasets. Human evaluations also validate the effectiveness of our model in terms of style accuracy, content preservation and fluency. Our code and data, including outputs of all baselines and our model are available at https://github.com/luofuli/DualLanST.
Adaptive Gradient Methods with Dynamic Bound of Learning Rate
Feb 26, 2019


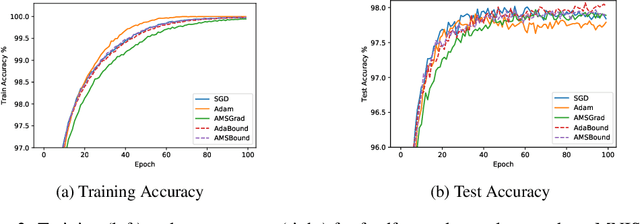
Adaptive optimization methods such as AdaGrad, RMSprop and Adam have been proposed to achieve a rapid training process with an element-wise scaling term on learning rates. Though prevailing, they are observed to generalize poorly compared with SGD or even fail to converge due to unstable and extreme learning rates. Recent work has put forward some algorithms such as AMSGrad to tackle this issue but they failed to achieve considerable improvement over existing methods. In our paper, we demonstrate that extreme learning rates can lead to poor performance. We provide new variants of Adam and AMSGrad, called AdaBound and AMSBound respectively, which employ dynamic bounds on learning rates to achieve a gradual and smooth transition from adaptive methods to SGD and give a theoretical proof of convergence. We further conduct experiments on various popular tasks and models, which is often insufficient in previous work. Experimental results show that new variants can eliminate the generalization gap between adaptive methods and SGD and maintain higher learning speed early in training at the same time. Moreover, they can bring significant improvement over their prototypes, especially on complex deep networks. The implementation of the algorithm can be found at https://github.com/Luolc/AdaBound .
Learning Personalized End-to-End Goal-Oriented Dialog
Nov 12, 2018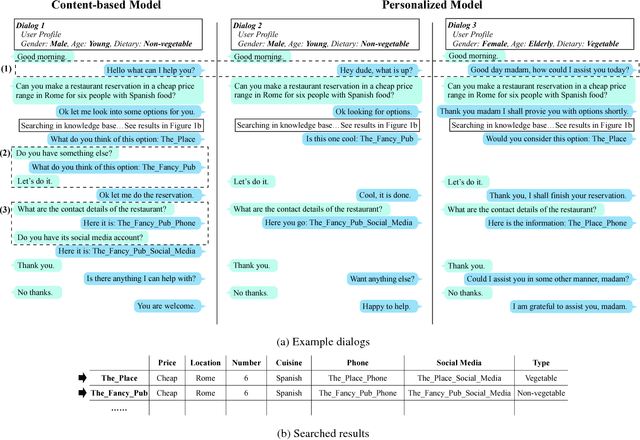
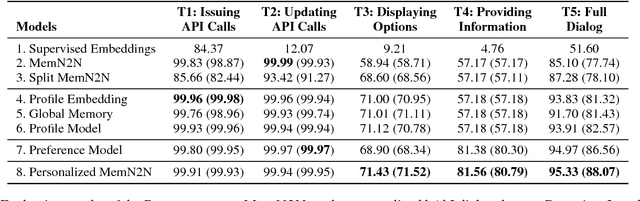
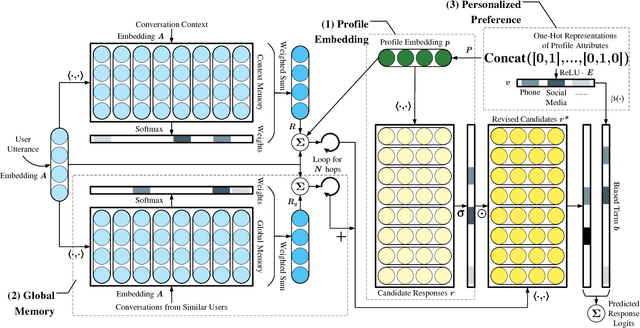

Most existing works on dialog systems only consider conversation content while neglecting the personality of the user the bot is interacting with, which begets several unsolved issues. In this paper, we present a personalized end-to-end model in an attempt to leverage personalization in goal-oriented dialogs. We first introduce a Profile Model which encodes user profiles into distributed embeddings and refers to conversation history from other similar users. Then a Preference Model captures user preferences over knowledge base entities to handle the ambiguity in user requests. The two models are combined into the Personalized MemN2N. Experiments show that the proposed model achieves qualitative performance improvements over state-of-the-art methods. As for human evaluation, it also outperforms other approaches in terms of task completion rate and user satisfaction.
Learning Unsupervised Word Mapping by Maximizing Mean Discrepancy
Nov 01, 2018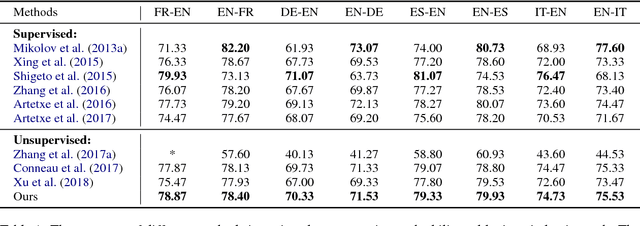
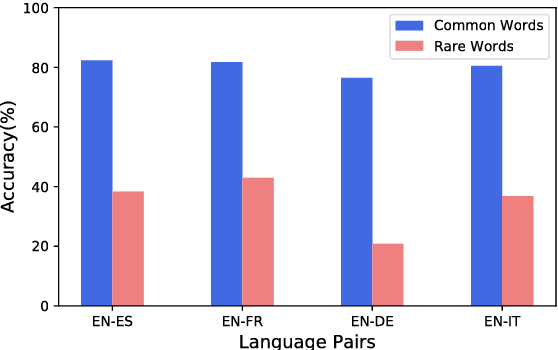
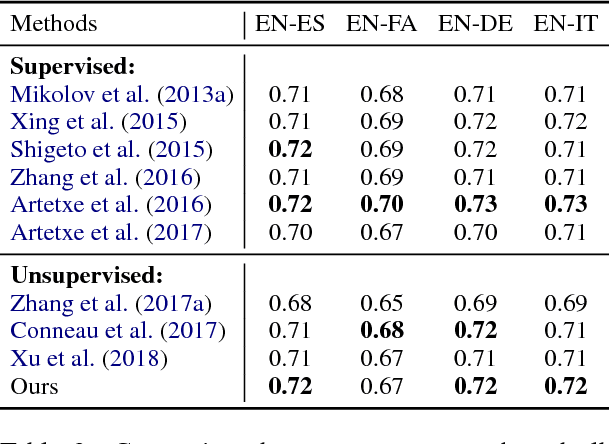
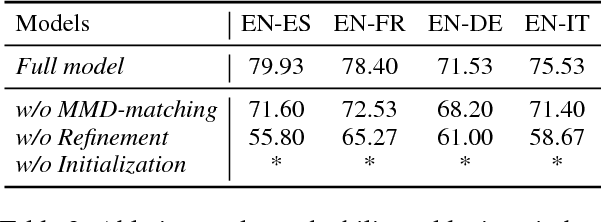
Cross-lingual word embeddings aim to capture common linguistic regularities of different languages, which benefit various downstream tasks ranging from machine translation to transfer learning. Recently, it has been shown that these embeddings can be effectively learned by aligning two disjoint monolingual vector spaces through a linear transformation (word mapping). In this work, we focus on learning such a word mapping without any supervision signal. Most previous work of this task adopts parametric metrics to measure distribution differences, which typically requires a sophisticated alternate optimization process, either in the form of \emph{minmax game} or intermediate \emph{density estimation}. This alternate optimization process is relatively hard and unstable. In order to avoid such sophisticated alternate optimization, we propose to learn unsupervised word mapping by directly maximizing the mean discrepancy between the distribution of transferred embedding and target embedding. Extensive experimental results show that our proposed model outperforms competitive baselines by a large margin.
Unsupervised Machine Commenting with Neural Variational Topic Model
Sep 13, 2018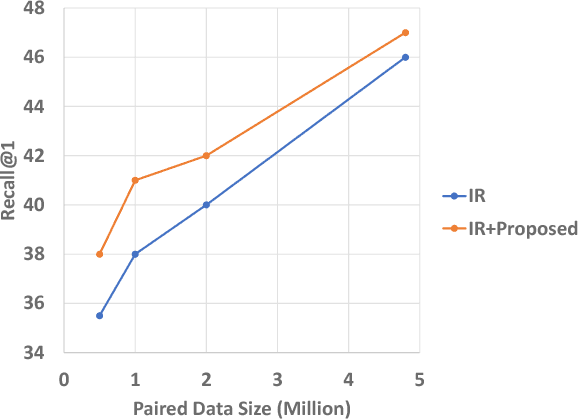
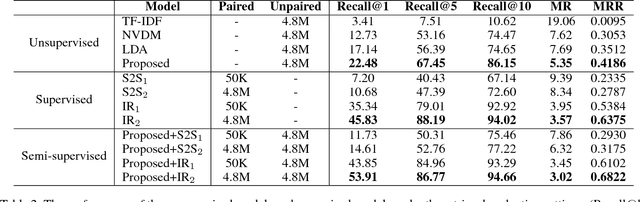
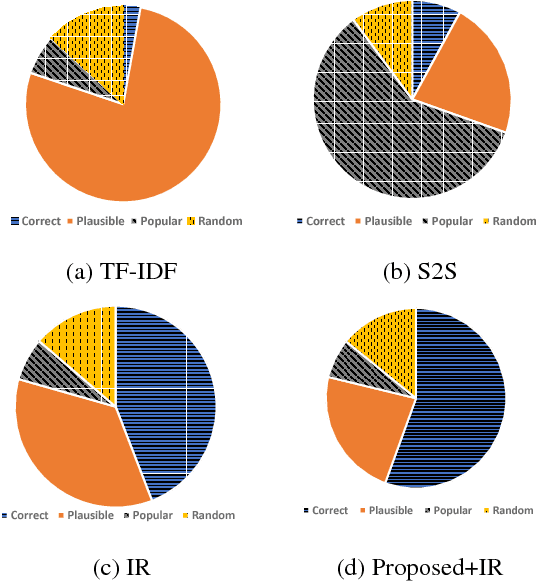
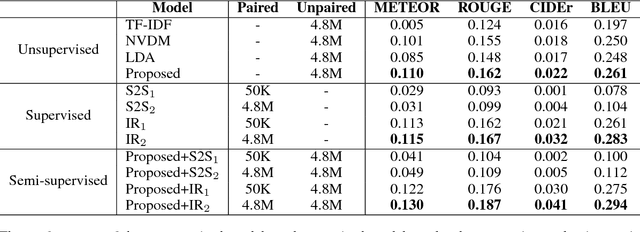
Article comments can provide supplementary opinions and facts for readers, thereby increase the attraction and engagement of articles. Therefore, automatically commenting is helpful in improving the activeness of the community, such as online forums and news websites. Previous work shows that training an automatic commenting system requires large parallel corpora. Although part of articles are naturally paired with the comments on some websites, most articles and comments are unpaired on the Internet. To fully exploit the unpaired data, we completely remove the need for parallel data and propose a novel unsupervised approach to train an automatic article commenting model, relying on nothing but unpaired articles and comments. Our model is based on a retrieval-based commenting framework, which uses news to retrieve comments based on the similarity of their topics. The topic representation is obtained from a neural variational topic model, which is trained in an unsupervised manner. We evaluate our model on a news comment dataset. Experiments show that our proposed topic-based approach significantly outperforms previous lexicon-based models. The model also profits from paired corpora and achieves state-of-the-art performance under semi-supervised scenarios.