 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriveGenVLM: Real-world Video Generation for Vision Language Model based Autonomous Driving
Aug 29, 2024



The advancement of autonomous driving technologies necessitates increasingly sophisticated methods for understanding and predicting real-world scenarios. Vision language models (VLMs) are emerging as revolutionary tools with significant potential to influence autonomous driving. In this paper, we propose the DriveGenVLM framework to generate driving videos and use VLMs to understand them. To achieve this, we employ a video generation framework grounded in denoising diffusion probabilistic models (DDPM) aimed at predicting real-world video sequences. We then explore the adequacy of our generated videos for use in VLMs by employing a pre-trained model known as Efficient In-context Learning on Egocentric Videos (EILEV). The diffusion model is trained with the Waymo open dataset and evaluated using the Fr\'echet Video Distance (FVD) score to ensure the quality and realism of the generated videos. Corresponding narrations are provided by EILEV for these generated videos, which may be beneficial in the autonomous driving domain. These narrations can enhance traffic scene understanding, aid in navigation, and improve planning capabilities. The integration of video generation with VLMs in the DriveGenVLM framework represents a significant step forward in leveraging advanced AI models to address complex challenges in autonomous driving.
Can LLMs Understand Social Norms in Autonomous Driving Games?
Aug 22, 2024



Social norm is defined as a shared standard of acceptable behavior in a society. The emergence of social norms fosters coordination among agents without any hard-coded rules, which is crucial for the large-scale deployment of AVs in an intelligent transportation system. This paper explores the application of LLMs in understanding and modeling social norms in autonomous driving games. We introduce LLMs into autonomous driving games as intelligent agents who make decisions according to text prompts. These agents are referred to as LLM-based agents. Our framework involves LLM-based agents playing Markov games in a multi-agent system (MAS), allowing us to investigate the emergence of social norms among individual agents. We aim to identify social norms by designing prompts and utilizing LLMs on textual information related to the environment setup and the observations of LLM-based agents. Using the OpenAI Chat API powered by GPT-4.0, we conduct experiments to simulate interactions and evaluate the performance of LLM-based agents in two driving scenarios: unsignalized intersection and highway platoon. The results show that LLM-based agents can handle dynamically changing environments in Markov games, and social norms evolve among LLM-based agents in both scenarios. In the intersection game, LLM-based agents tend to adopt a conservative driving policy when facing a potential car crash. The advantage of LLM-based agents in games lies in their strong operability and analyzability, which facilitate experimental design.
Pluto and Charon: A Time and Memory Efficient Collaborative Edge AI Framework for Personal LLMs Fine-Tuning
Aug 20, 2024Large language models (LLMs) have unlocked a plethora of powerful applications at the network edge, such as intelligent personal assistants. Data privacy and security concerns have prompted a shift towards edge-based fine-tuning of personal LLMs, away from cloud reliance. However, this raises issues of computational intensity and resource scarcity, hindering training efficiency and feasibility. While current studies investigate parameter-efficient fine-tuning (PEFT) techniques to mitigate resource constraints, our analysis indicates that these techniques are not sufficiently resource-efficient for edge devices. To tackle these challenges, we propose Pluto and Charon (PAC), a time and memory efficient collaborative edge AI framework for personal LLMs fine-tuning. PAC breaks the resource wall of personal LLMs fine-tuning with a sophisticated algorithm-system co-design. (1) Algorithmically, PAC implements a personal LLMs fine-tuning technique that is efficient in terms of parameters, time, and memory. It utilizes Parallel Adapters to circumvent the need for a full backward pass through the LLM backbone. Additionally, an activation cache mechanism further streamlining the process by negating the necessity for repeated forward passes across multiple epochs. (2) Systematically, PAC leverages edge devices in close proximity, pooling them as a collective resource for in-situ personal LLMs fine-tuning, utilizing a hybrid data and pipeline parallelism to orchestrate distributed training. The use of the activation cache eliminates the need for forward pass through the LLM backbone,enabling exclusive fine-tuning of the Parallel Adapters using data parallelism. Extensive evaluation based on prototype implementation demonstrates that PAC remarkably outperforms state-of-the-art approaches, achieving up to 8.64x end-to-end speedup and up to 88.16% reduction in memory footprint.
Asteroid: Resource-Efficient Hybrid Pipeline Parallelism for Collaborative DNN Training on Heterogeneous Edge Devices
Aug 15, 2024



On-device Deep Neural Network (DNN) training has been recognized as crucial for privacy-preserving machine learning at the edge. However, the intensive training workload and limited onboard computing resources pose significant challenges to the availability and efficiency of model training. While existing works address these challenges through native resource management optimization, we instead leverage our observation that edge environments usually comprise a rich set of accompanying trusted edge devices with idle resources beyond a single terminal. We propose Asteroid, a distributed edge training system that breaks the resource walls across heterogeneous edge devices for efficient model training acceleration. Asteroid adopts a hybrid pipeline parallelism to orchestrate distributed training, along with a judicious parallelism planning for maximizing throughput under certain resource constraints. Furthermore, a fault-tolerant yet lightweight pipeline replay mechanism is developed to tame the device-level dynamics for training robustness and performance stability. We implement Asteroid on heterogeneous edge devices with both vision and language models, demonstrating up to 12.2x faster training than conventional parallelism methods and 2.1x faster than state-of-the-art hybrid parallelism methods through evaluations. Furthermore, Asteroid can recover training pipeline 14x faster than baseline methods while preserving comparable throughput despite unexpected device exiting and failure.
Stochastic Semi-Gradient Descent for Learning Mean Field Games with Population-Aware Function Approximation
Aug 15, 2024



Mean field games (MFGs) model the interactions within a large-population multi-agent system using the population distribution. Traditional learning methods for MFGs are based on fixed-point iteration (FPI), which calculates best responses and induced population distribution separately and sequentially. However, FPI-type methods suffer from inefficiency and instability, due to oscillations caused by the forward-backward procedure. This paper considers an online learning method for MFGs, where an agent updates its policy and population estimates simultaneously and fully asynchronously, resulting in a simple stochastic gradient descent (SGD) type method called SemiSGD. Not only does SemiSGD exhibit numerical stability and efficiency, but it also provides a novel perspective by treating the value function and population distribution as a unified parameter. We theoretically show that SemiSGD directs this unified parameter along a descent direction to the mean field equilibrium. Motivated by this perspective, we develop a linear function approximation (LFA) for both the value function and the population distribution, resulting in the first population-aware LFA for MFGs on continuous state-action space. Finite-time convergence and approximation error analysis are provided for SemiSGD equipped with population-aware LFA.
MMRole: A Comprehensive Framework for Developing and Evaluating Multimodal Role-Playing Agents
Aug 08, 2024



Recently, Role-Playing Agents (RPAs) have garnered increasing attention for their potential to deliver emotional value and facilitate sociological research. However, existing studies are primarily confined to the textual modality, unable to simulate humans' multimodal perceptual capabilities. To bridge this gap, we introduce the concept of Multimodal Role-Playing Agents (MRPAs), and propose a comprehensive framework, MMRole, for their development and evaluation, which comprises a personalized multimodal dataset and a robust evaluation method. Specifically, we construct a large-scale, high-quality dataset, MMRole-Data, consisting of 85 characters, 11K images, and 14K single or multi-turn dialogues. Additionally, we present a robust evaluation method, MMRole-Eval, encompassing eight metrics across three dimensions, where a reward model is trained to score MRPAs with the constructed ground-truth data for comparison. Moreover, we develop the first specialized MRPA, MMRole-Agent. Extensive evaluation results demonstrate the improved performance of MMRole-Agent and highlight the primary challenges in developing MRPAs, emphasizing the need for enhanced multimodal understanding and role-playing consistency. The data, code, and models will be available at https://github.com/YanqiDai/MMRole.
Cool-Fusion: Fuse Large Language Models without Training
Jul 29, 2024



We focus on the problem of fusing two or more heterogeneous large language models (LLMs) to facilitate their complementary strengths. One of the challenges on model fusion is high computational load, i.e. to fine-tune or to align vocabularies via combinatorial optimization. To this end, we propose \emph{Cool-Fusion}, a simple yet effective approach that fuses the knowledge of heterogeneous source LLMs to leverage their complementary strengths. \emph{Cool-Fusion} is the first method that does not require any type of training like the ensemble approaches. But unlike ensemble methods, it is applicable to any set of source LLMs that have different vocabularies. The basic idea is to have each source LLM individually generate tokens until the tokens can be decoded into a text segment that ends at word boundaries common to all source LLMs. Then, the source LLMs jointly rerank the generated text segment and select the best one, which is the fused text generation in one step. Extensive experiments are conducted across a variety of benchmark datasets. On \emph{GSM8K}, \emph{Cool-Fusion} increases accuracy from three strong source LLMs by a significant 8\%-17.8\%.
Towards Effective and Efficient Continual Pre-training of Large Language Models
Jul 26, 2024



Continual pre-training (CPT) has been an important approach for adapting language models to specific domains or tasks. To make the CPT approach more traceable, this paper presents a technical report for continually pre-training Llama-3 (8B), which significantly enhances the Chinese language ability and scientific reasoning ability of the backbone model. To enhance the new abilities while retaining the original abilities, we design specific data mixture and curriculum strategies by utilizing existing datasets and synthesizing high-quality datasets. Specifically, we synthesize multidisciplinary scientific question and answer (QA) pairs based on related web pages, and subsequently incorporate these synthetic data to improve the scientific reasoning ability of Llama-3. We refer to the model after CPT as Llama-3-SynE (Synthetic data Enhanced Llama-3). We also present the tuning experiments with a relatively small model -- TinyLlama, and employ the derived findings to train the backbone model. Extensive experiments on a number of evaluation benchmarks show that our approach can largely improve the performance of the backbone models, including both the general abilities (+8.81 on C-Eval and +6.31 on CMMLU) and the scientific reasoning abilities (+12.00 on MATH and +4.13 on SciEval), without hurting the original capacities. Our model, data, and codes are available at https://github.com/RUC-GSAI/Llama-3-SynE.
Towards Robust Recommendation via Decision Boundary-aware Graph Contrastive Learning
Jul 14, 2024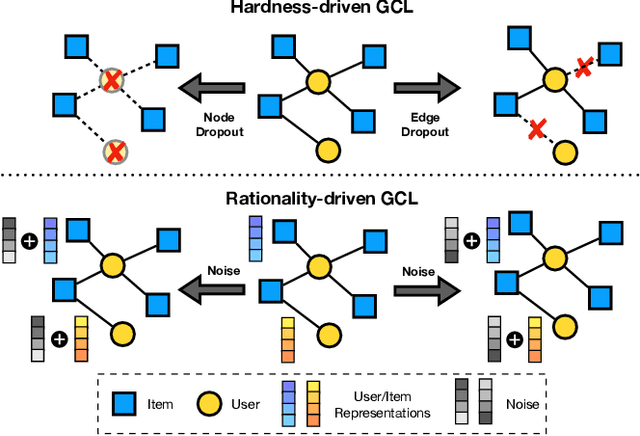
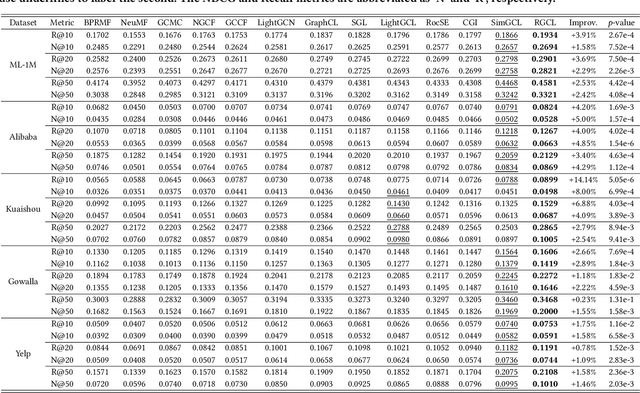
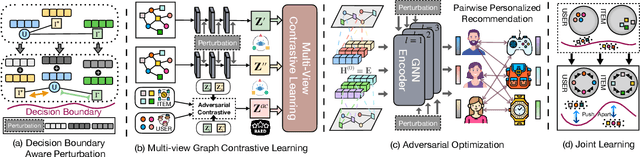

In recent years, graph contrastive learning (GCL) has received increasing attention in recommender systems due to its effectiveness in reducing bias caused by data sparsity. However, most existing GCL models rely on heuristic approaches and usually assume entity independence when constructing contrastive views. We argue that these methods struggle to strike a balance between semantic invariance and view hardness across the dynamic training process, both of which are critical factors in graph contrastive learning. To address the above issues, we propose a novel GCL-based recommendation framework RGCL, which effectively maintains the semantic invariance of contrastive pairs and dynamically adapts as the model capability evolves through the training process. Specifically, RGCL first introduces decision boundary-aware adversarial perturbations to constrain the exploration space of contrastive augmented views, avoiding the decrease of task-specific information. Furthermore, to incorporate global user-user and item-item collaboration relationships for guiding on the generation of hard contrastive views, we propose an adversarial-contrastive learning objective to construct a relation-aware view-generator. Besides, considering that unsupervised GCL could potentially narrower margins between data points and the decision boundary, resulting in decreased model robustness, we introduce the adversarial examples based on maximum perturbations to achieve margin maximization. We also provide theoretical analyses on the effectiveness of our designs. Through extensive experiments on five public datasets, we demonstrate the superiority of RGCL compared against twelve baseline models.
Resource Management for Low-latency Cooperative Fine-tuning of Foundation Models at the Network Edge
Jul 13, 2024



The emergence of large-scale foundation models (FoMo's) that can perform human-like intelligence motivates their deployment at the network edge for devices to access state-of-the-art artificial intelligence. For better user experiences, the pre-trained FoMo's need to be adapted to specialized downstream tasks through fine-tuning techniques. To transcend a single device's memory and computation limitations, we advocate multi-device cooperation within the device-edge cooperative fine-tuning (DEFT) paradigm, where edge devices cooperate to simultaneously optimize different parts of fine-tuning parameters within a FoMo. However, the parameter blocks reside at different depths within a FoMo architecture, leading to varied computation latency-and-memory cost due to gradient backpropagation-based calculations. The heterogeneous on-device computation and memory capacities and channel conditions necessitate an integrated communication-and-computation allocation of local computation loads and communication resources to achieve low-latency (LoLa) DEFT. To this end, we consider the depth-ware DEFT block allocation problem. The involved optimal block-device matching is tackled by the proposed low-complexity Cutting-RecoUNting-CHecking (CRUNCH) algorithm, which is designed by exploiting the monotone-increasing property between block depth and computation latency-and-memory cost. Next, the joint bandwidth-and-block allocation makes the problem more sophisticated. We observe a splittable Lagrangian expression through the transformation and analysis of the original problem, where the variables indicating device involvement are introduced. Then, the dual ascent method is employed to tackle this problem iteratively. Through extensive experiments conducted on the GLUE benchmark, our results demonstrate significant latency reduction achievable by LoLa DEFT for fine-tuning a RoBERTa model.