 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAM-Net: Expressive Linear Attention with Selectively Addressable Memory
Feb 12, 2026While linear attention architectures offer efficient inference, compressing unbounded history into a fixed-size memory inherently limits expressivity and causes information loss. To address this limitation, we introduce Random Access Memory Network (RAM-Net), a novel architecture designed to bridge the gap between the representational capacity of full attention and the memory efficiency of linear models. The core of RAM-Net maps inputs to high-dimensional sparse vectors serving as explicit addresses, allowing the model to selectively access a massive memory state. This design enables exponential state size scaling without additional parameters, which significantly mitigates signal interference and enhances retrieval fidelity. Moreover, the inherent sparsity ensures exceptional computational efficiency, as state updates are confined to minimal entries. Extensive experiments demonstrate that RAM-Net consistently surpasses state-of-the-art baselines in fine-grained long-range retrieval tasks and achieves competitive performance in standard language modeling and zero-shot commonsense reasoning benchmarks, validating its superior capability to capture complex dependencies with significantly reduced computational overhead.
Reasoning with Autoregressive-Diffusion Collaborative Thoughts
Feb 02, 2026Autoregressive and diffusion models represent two complementary generative paradigms. Autoregressive models excel at sequential planning and constraint composition, yet struggle with tasks that require explicit spatial or physical grounding. Diffusion models, in contrast, capture rich spatial structure through high-dimensional generation, but lack the stepwise logical control needed to satisfy complex, multi-stage constraints or to reliably identify and correct errors. We introduce Collaborative Thoughts, a unified collaborative framework that enables autoregressive and diffusion models to reason and generate jointly through a closed-loop interaction. In Collaborative Thoughts, autoregressive models perform structured planning and constraint management, diffusion models instantiate these constraints as intermediate visual thoughts, and a vision-based critic module evaluates whether the visual thoughts satisfy the intended structural and physical requirements. This feedback is then used to iteratively refine subsequent planning and generation steps, mitigating error propagation across modalities. Importantly, Collaborative Thoughts uses the same collaborative loop regardless of whether the task is autoregressive question answering or diffusion-based visual generation. Through representative examples, we illustrate how Collaborative Thoughts can improve the reliability of spatial reasoning and the controllability of generation.
ContextAgent: Context-Aware Proactive LLM Agents with Open-World Sensory Perceptions
May 20, 2025Recent advances in Large Language Models (LLMs) have propelled intelligent agents from reactive responses to proactive support. While promising, existing proactive agents either rely exclusively on observations from enclosed environments (e.g., desktop UIs) with direct LLM inference or employ rule-based proactive notifications, leading to suboptimal user intent understanding and limited functionality for proactive service. In this paper, we introduce ContextAgent, the first context-aware proactive agent that incorporates extensive sensory contexts to enhance the proactive capabilities of LLM agents. ContextAgent first extracts multi-dimensional contexts from massive sensory perceptions on wearables (e.g., video and audio) to understand user intentions. ContextAgent then leverages the sensory contexts and the persona contexts from historical data to predict the necessity for proactive services. When proactive assistance is needed, ContextAgent further automatically calls the necessary tools to assist users unobtrusively. To evaluate this new task, we curate ContextAgentBench, the first benchmark for evaluating context-aware proactive LLM agents, covering 1,000 samples across nine daily scenarios and twenty tools. Experiments on ContextAgentBench show that ContextAgent outperforms baselines by achieving up to 8.5% and 6.0% higher accuracy in proactive predictions and tool calling, respectively. We hope our research can inspire the development of more advanced, human-centric, proactive AI assistants.
An LLM-Empowered Low-Resolution Vision System for On-Device Human Behavior Understanding
May 03, 2025The rapid advancements in Large Vision Language Models (LVLMs) offer the potential to surpass conventional labeling by generating richer, more detailed descriptions of on-device human behavior understanding (HBU) in low-resolution vision systems, such as depth, thermal, and infrared. However, existing large vision language model (LVLM) approaches are unable to understand low-resolution data well as they are primarily designed for high-resolution data, such as RGB images. A quick fixing approach is to caption a large amount of low-resolution data, but it requires a significant amount of labor-intensive annotation efforts. In this paper, we propose a novel, labor-saving system, Llambda, designed to support low-resolution HBU. The core idea is to leverage limited labeled data and a large amount of unlabeled data to guide LLMs in generating informative captions, which can be combined with raw data to effectively fine-tune LVLM models for understanding low-resolution videos in HBU. First, we propose a Contrastive-Oriented Data Labeler, which can capture behavior-relevant information from long, low-resolution videos and generate high-quality pseudo labels for unlabeled data via contrastive learning. Second, we propose a Physical-Knowledge Guided Captioner, which utilizes spatial and temporal consistency checks to mitigate errors in pseudo labels. Therefore, it can improve LLMs' understanding of sequential data and then generate high-quality video captions. Finally, to ensure on-device deployability, we employ LoRA-based efficient fine-tuning to adapt LVLMs for low-resolution data. We evaluate Llambda using a region-scale real-world testbed and three distinct low-resolution datasets, and the experiments show that Llambda outperforms several state-of-the-art LVLM systems up to $40.03\%$ on average Bert-Score.
OpenTCM: A GraphRAG-Empowered LLM-based System for Traditional Chinese Medicine Knowledge Retrieval and Diagnosis
Apr 28, 2025Traditional Chinese Medicine (TCM) represents a rich repository of ancient medical knowledge that continues to play an important role in modern healthcare. Due to the complexity and breadth of the TCM literature, the integration of AI technologies is critical for its modernization and broader accessibility. However, this integration poses considerable challenges, including the interpretation of obscure classical Chinese texts and the modeling of intricate semantic relationships among TCM concepts. In this paper, we develop OpenTCM, an LLM-based system that combines a domain-specific TCM knowledge graph and Graph-based Retrieval-Augmented Generation (GraphRAG). First, we extract more than 3.73 million classical Chinese characters from 68 gynecological books in the Chinese Medical Classics Database, with the help of TCM and gynecology experts. Second, we construct a comprehensive multi-relational knowledge graph comprising more than 48,000 entities and 152,000 interrelationships, using customized prompts and Chinese-oriented LLMs such as DeepSeek and Kimi to ensure high-fidelity semantic understanding. Last, we integrate OpenTCM with this knowledge graph, enabling high-fidelity ingredient knowledge retrieval and diagnostic question-answering without model fine-tuning. Experimental evaluations demonstrate that our prompt design and model selection significantly improve knowledge graph quality, achieving a precision of 98. 55% and an F1 score of 99. 55%. In addition, OpenTCM achieves mean expert scores of 4.5 in ingredient information retrieval and 3.8 in diagnostic question-answering tasks, outperforming state-of-the-art solutions in real-world TCM use cases.
SHADE-AD: An LLM-Based Framework for Synthesizing Activity Data of Alzheimer's Patients
Mar 03, 2025



Alzheimer's Disease (AD) has become an increasingly critical global health concern, which necessitates effective monitoring solutions in smart health applications. However, the development of such solutions is significantly hindered by the scarcity of AD-specific activity datasets. To address this challenge, we propose SHADE-AD, a Large Language Model (LLM) framework for Synthesizing Human Activity Datasets Embedded with AD features. Leveraging both public datasets and our own collected data from 99 AD patients, SHADE-AD synthesizes human activity videos that specifically represent AD-related behaviors. By employing a three-stage training mechanism, it broadens the range of activities beyond those collected from limited deployment settings. We conducted comprehensive evaluations of the generated dataset, demonstrating significant improvements in downstream tasks such as Human Activity Recognition (HAR) detection, with enhancements of up to 79.69%. Detailed motion metrics between real and synthetic data show strong alignment, validating the realism and utility of the synthesized dataset. These results underscore SHADE-AD's potential to advance smart health applications by providing a cost-effective, privacy-preserving solution for AD monitoring.
SocialMind: LLM-based Proactive AR Social Assistive System with Human-like Perception for In-situ Live Interactions
Dec 05, 2024

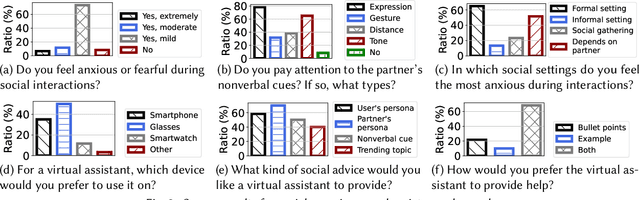
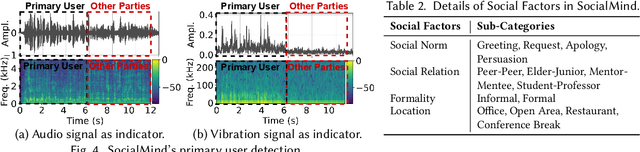
Social interactions are fundamental to human life. The recent emergence of large language models (LLMs)-based virtual assistants has demonstrated their potential to revolutionize human interactions and lifestyles. However, existing assistive systems mainly provide reactive services to individual users, rather than offering in-situ assistance during live social interactions with conversational partners. In this study, we introduce SocialMind, the first LLM-based proactive AR social assistive system that provides users with in-situ social assistance. SocialMind employs human-like perception leveraging multi-modal sensors to extract both verbal and nonverbal cues, social factors, and implicit personas, incorporating these social cues into LLM reasoning for social suggestion generation. Additionally, SocialMind employs a multi-tier collaborative generation strategy and proactive update mechanism to display social suggestions on Augmented Reality (AR) glasses, ensuring that suggestions are timely provided to users without disrupting the natural flow of conversation. Evaluations on three public datasets and a user study with 20 participants show that SocialMind achieves 38.3% higher engagement compared to baselines, and 95% of participants are willing to use SocialMind in their live social interactions.
Asteroid: Resource-Efficient Hybrid Pipeline Parallelism for Collaborative DNN Training on Heterogeneous Edge Devices
Aug 15, 2024



On-device Deep Neural Network (DNN) training has been recognized as crucial for privacy-preserving machine learning at the edge. However, the intensive training workload and limited onboard computing resources pose significant challenges to the availability and efficiency of model training. While existing works address these challenges through native resource management optimization, we instead leverage our observation that edge environments usually comprise a rich set of accompanying trusted edge devices with idle resources beyond a single terminal. We propose Asteroid, a distributed edge training system that breaks the resource walls across heterogeneous edge devices for efficient model training acceleration. Asteroid adopts a hybrid pipeline parallelism to orchestrate distributed training, along with a judicious parallelism planning for maximizing throughput under certain resource constraints. Furthermore, a fault-tolerant yet lightweight pipeline replay mechanism is developed to tame the device-level dynamics for training robustness and performance stability. We implement Asteroid on heterogeneous edge devices with both vision and language models, demonstrating up to 12.2x faster training than conventional parallelism methods and 2.1x faster than state-of-the-art hybrid parallelism methods through evaluations. Furthermore, Asteroid can recover training pipeline 14x faster than baseline methods while preserving comparable throughput despite unexpected device exiting and failure.
DrHouse: An LLM-empowered Diagnostic Reasoning System through Harnessing Outcomes from Sensor Data and Expert Knowledge
May 21, 2024Large language models (LLMs) have the potential to transform digital healthcare, as evidenced by recent advances in LLM-based virtual doctors. However, current approaches rely on patient's subjective descriptions of symptoms, causing increased misdiagnosis. Recognizing the value of daily data from smart devices, we introduce a novel LLM-based multi-turn consultation virtual doctor system, DrHouse, which incorporates three significant contributions: 1) It utilizes sensor data from smart devices in the diagnosis process, enhancing accuracy and reliability. 2) DrHouse leverages continuously updating medical databases such as Up-to-Date and PubMed to ensure our model remains at diagnostic standard's forefront. 3) DrHouse introduces a novel diagnostic algorithm that concurrently evaluates potential diseases and their likelihood, facilitating more nuanced and informed medical assessments. Through multi-turn interactions, DrHouse determines the next steps, such as accessing daily data from smart devices or requesting in-lab tests, and progressively refines its diagnoses. Evaluations on three public datasets and our self-collected datasets show that DrHouse can achieve up to an 18.8% increase in diagnosis accuracy over the state-of-the-art baselines. The results of a 32-participant user study show that 75% medical experts and 91.7% patients are willing to use DrHouse.
Soar: Design and Deployment of A Smart Roadside Infrastructure System for Autonomous Driving
Apr 21, 2024



Recently,smart roadside infrastructure (SRI) has demonstrated the potential of achieving fully autonomous driving systems. To explore the potential of infrastructure-assisted autonomous driving, this paper presents the design and deployment of Soar, the first end-to-end SRI system specifically designed to support autonomous driving systems. Soar consists of both software and hardware components carefully designed to overcome various system and physical challenges. Soar can leverage the existing operational infrastructure like street lampposts for a lower barrier of adoption. Soar adopts a new communication architecture that comprises a bi-directional multi-hop I2I network and a downlink I2V broadcast service, which are designed based on off-the-shelf 802.11ac interfaces in an integrated manner. Soar also features a hierarchical DL task management framework to achieve desirable load balancing among nodes and enable them to collaborate efficiently to run multiple data-intensive autonomous driving applications. We deployed a total of 18 Soar nodes on existing lampposts on campus, which have been operational for over two years. Our real-world evaluation shows that Soar can support a diverse set of autonomous driving applications and achieve desirable real-time performance and high communication reliability. Our findings and experiences in this work offer key insights into the development and deployment of next-generation smart roadside infrastructure and autonomous driving systems.