 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDive into Ambiguity: A*-Inspired Multi-Agents Commonsense Obfuscation Attack on LLM Prompts
May 31, 2026Large language models (LLMs) excel in reasoning and knowledge-intensive tasks but remain vulnerable to prompt-level adversarial attacks that preserve intent while triggering commonsense hallucinations. This vulnerability is urgent, as LLMs are rapidly integrated into safety-critical domains where factual reliability is non-negotiable. Existing attack methods either lack efficiency or fail to capture the adaptive strategies of real-world adversaries. We propose an A*-inspired Factual Error Induction Framework, a framework for generating semantically aligned yet obfuscated prompts. At its core is a Hierarchical Rewrite Strategy guided by a dynamic semantic dispersion coefficient $γ$ that balances conservative edits early with aggressive obfuscations later, following a reverse simulated annealing schedule. To enhance interpretability, we further introduce Agentic Mechanism Labeling, which discovers and refines adversarial mechanisms, offering interpretable reverse optimization. Theoretically, we prove that prompt rewriting follows a contractive recurrence, leading to semantic collapse as $γ$ decreases. Empirically, across diverse LLMs, our method achieves higher attack success rates than exhaustive exploration while requiring fewer attempts, demonstrating both efficiency and effectiveness.
Rethinking Multi-Agent Intelligence Through the Lens of Small-World Networks
Dec 19, 2025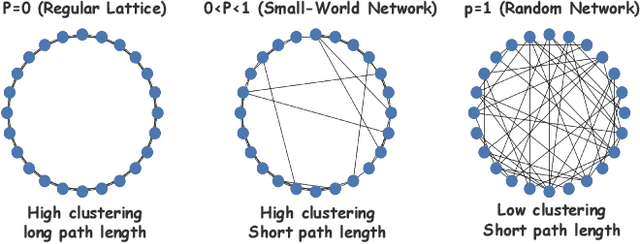



Large language models (LLMs) have enabled multi-agent systems (MAS) in which multiple agents argue, critique, and coordinate to solve complex tasks, making communication topology a first-class design choice. Yet most existing LLM-based MAS either adopt fully connected graphs, simple sparse rings, or ad-hoc dynamic selection, with little structural guidance. In this work, we revisit classic theory on small-world (SW) networks and ask: what changes if we treat SW connectivity as a design prior for MAS? We first bridge insights from neuroscience and complex networks to MAS, highlighting how SW structures balance local clustering and long-range integration. Using multi-agent debate (MAD) as a controlled testbed, experiment results show that SW connectivity yields nearly the same accuracy and token cost, while substantially stabilizing consensus trajectories. Building on this, we introduce an uncertainty-guided rewiring scheme for scaling MAS, where long-range shortcuts are added between epistemically divergent agents using LLM-oriented uncertainty signals (e.g., semantic entropy). This yields controllable SW structures that adapt to task difficulty and agent heterogeneity. Finally, we discuss broader implications of SW priors for MAS design, framing them as stabilizers of reasoning, enhancers of robustness, scalable coordinators, and inductive biases for emergent cognitive roles.
Meta-Black-Box Optimization with Bi-Space Landscape Analysis and Dual-Control Mechanism for SAEA
Nov 19, 2025Surrogate-Assisted Evolutionary Algorithms (SAEAs) are widely used for expensive Black-Box Optimization. However, their reliance on rigid, manually designed components such as infill criteria and evolutionary strategies during the search process limits their flexibility across tasks. To address these limitations, we propose Dual-Control Bi-Space Surrogate-Assisted Evolutionary Algorithm (DB-SAEA), a Meta-Black-Box Optimization (MetaBBO) framework tailored for multi-objective problems. DB-SAEA learns a meta-policy that jointly regulates candidate generation and infill criterion selection, enabling dual control. The bi-space Exploratory Landscape Analysis (ELA) module in DB-SAEA adopts an attention-based architecture to capture optimization states from both true and surrogate evaluation spaces, while ensuring scalability across problem dimensions, population sizes, and objectives. Additionally, we integrate TabPFN as the surrogate model for accurate and efficient prediction with uncertainty estimation. The framework is trained via reinforcement learning, leveraging parallel sampling and centralized training to enhance efficiency and transferability across tasks. Experimental results demonstrate that DB-SAEA not only outperforms state-of-the-art baselines across diverse benchmarks, but also exhibits strong zero-shot transfer to unseen tasks with higher-dimensional settings. This work introduces the first MetaBBO framework with dual-level control over SAEAs and a bi-space ELA that captures surrogate model information.
Chasing Consistency: Quantifying and Optimizing Human-Model Alignment in Chain-of-Thought Reasoning
Nov 09, 2025This paper presents a framework for evaluating and optimizing reasoning consistency in Large Language Models (LLMs) via a new metric, the Alignment Score, which quantifies the semantic alignment between model-generated reasoning chains and human-written reference chains in Chain-of-Thought (CoT) reasoning. Empirically, we find that 2-hop reasoning chains achieve the highest Alignment Score. To explain this phenomenon, we define four key error types: logical disconnection, thematic shift, redundant reasoning, and causal reversal, and show how each contributes to the degradation of the Alignment Score. Building on this analysis, we further propose Semantic Consistency Optimization Sampling (SCOS), a method that samples and favors chains with minimal alignment errors, significantly improving Alignment Scores by an average of 29.84% with longer reasoning chains, such as in 3-hop tasks.
OneRec-V2 Technical Report
Aug 28, 2025



Recent breakthroughs in generative AI have transformed recommender systems through end-to-end generation. OneRec reformulates recommendation as an autoregressive generation task, achieving high Model FLOPs Utilization. While OneRec-V1 has shown significant empirical success in real-world deployment, two critical challenges hinder its scalability and performance: (1) inefficient computational allocation where 97.66% of resources are consumed by sequence encoding rather than generation, and (2) limitations in reinforcement learning relying solely on reward models. To address these challenges, we propose OneRec-V2, featuring: (1) Lazy Decoder-Only Architecture: Eliminates encoder bottlenecks, reducing total computation by 94% and training resources by 90%, enabling successful scaling to 8B parameters. (2) Preference Alignment with Real-World User Interactions: Incorporates Duration-Aware Reward Shaping and Adaptive Ratio Clipping to better align with user preferences using real-world feedback. Extensive A/B tests on Kuaishou demonstrate OneRec-V2's effectiveness, improving App Stay Time by 0.467%/0.741% while balancing multi-objective recommendations. This work advances generative recommendation scalability and alignment with real-world feedback, representing a step forward in the development of end-to-end recommender systems.
OneRec Technical Report
Jun 16, 2025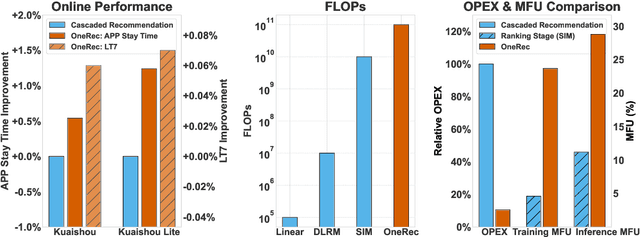

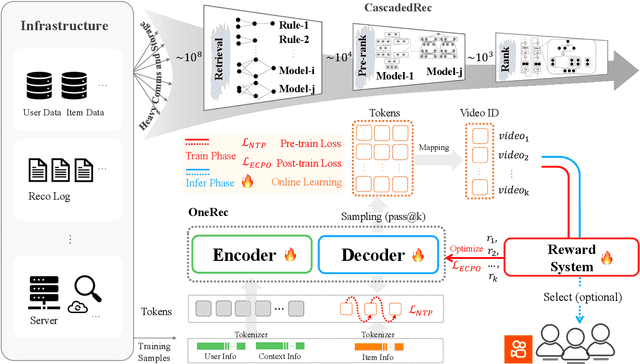
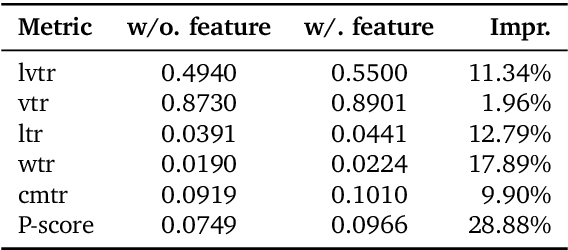
Recommender systems have been widely used in various large-scale user-oriented platforms for many years. However, compared to the rapid developments in the AI community, recommendation systems have not achieved a breakthrough in recent years. For instance, they still rely on a multi-stage cascaded architecture rather than an end-to-end approach, leading to computational fragmentation and optimization inconsistencies, and hindering the effective application of key breakthrough technologies from the AI community in recommendation scenarios. To address these issues, we propose OneRec, which reshapes the recommendation system through an end-to-end generative approach and achieves promising results. Firstly, we have enhanced the computational FLOPs of the current recommendation model by 10 $\times$ and have identified the scaling laws for recommendations within certain boundaries. Secondly, reinforcement learning techniques, previously difficult to apply for optimizing recommendations, show significant potential in this framework. Lastly, through infrastructure optimizations, we have achieved 23.7% and 28.8% Model FLOPs Utilization (MFU) on flagship GPUs during training and inference, respectively, aligning closely with the LLM community. This architecture significantly reduces communication and storage overhead, resulting in operating expense that is only 10.6% of traditional recommendation pipelines. Deployed in Kuaishou/Kuaishou Lite APP, it handles 25% of total queries per second, enhancing overall App Stay Time by 0.54% and 1.24%, respectively. Additionally, we have observed significant increases in metrics such as 7-day Lifetime, which is a crucial indicator of recommendation experience. We also provide practical lessons and insights derived from developing, optimizing, and maintaining a production-scale recommendation system with significant real-world impact.
Train Robots in a JIF: Joint Inverse and Forward Dynamics with Human and Robot Demonstrations
Mar 15, 2025Pre-training on large datasets of robot demonstrations is a powerful technique for learning diverse manipulation skills but is often limited by the high cost and complexity of collecting robot-centric data, especially for tasks requiring tactile feedback. This work addresses these challenges by introducing a novel method for pre-training with multi-modal human demonstrations. Our approach jointly learns inverse and forward dynamics to extract latent state representations, towards learning manipulation specific representations. This enables efficient fine-tuning with only a small number of robot demonstrations, significantly improving data efficiency. Furthermore, our method allows for the use of multi-modal data, such as combination of vision and touch for manipulation. By leveraging latent dynamics modeling and tactile sensing, this approach paves the way for scalable robot manipulation learning based on human demonstrations.
Position: Towards a Responsible LLM-empowered Multi-Agent Systems
Feb 03, 2025



The rise of Agent AI and Large Language Model-powered Multi-Agent Systems (LLM-MAS) has underscored the need for responsible and dependable system operation. Tools like LangChain and Retrieval-Augmented Generation have expanded LLM capabilities, enabling deeper integration into MAS through enhanced knowledge retrieval and reasoning. However, these advancements introduce critical challenges: LLM agents exhibit inherent unpredictability, and uncertainties in their outputs can compound across interactions, threatening system stability. To address these risks, a human-centered design approach with active dynamic moderation is essential. Such an approach enhances traditional passive oversight by facilitating coherent inter-agent communication and effective system governance, allowing MAS to achieve desired outcomes more efficiently.
Can LLMs Understand Social Norms in Autonomous Driving Games?
Aug 22, 2024



Social norm is defined as a shared standard of acceptable behavior in a society. The emergence of social norms fosters coordination among agents without any hard-coded rules, which is crucial for the large-scale deployment of AVs in an intelligent transportation system. This paper explores the application of LLMs in understanding and modeling social norms in autonomous driving games. We introduce LLMs into autonomous driving games as intelligent agents who make decisions according to text prompts. These agents are referred to as LLM-based agents. Our framework involves LLM-based agents playing Markov games in a multi-agent system (MAS), allowing us to investigate the emergence of social norms among individual agents. We aim to identify social norms by designing prompts and utilizing LLMs on textual information related to the environment setup and the observations of LLM-based agents. Using the OpenAI Chat API powered by GPT-4.0, we conduct experiments to simulate interactions and evaluate the performance of LLM-based agents in two driving scenarios: unsignalized intersection and highway platoon. The results show that LLM-based agents can handle dynamically changing environments in Markov games, and social norms evolve among LLM-based agents in both scenarios. In the intersection game, LLM-based agents tend to adopt a conservative driving policy when facing a potential car crash. The advantage of LLM-based agents in games lies in their strong operability and analyzability, which facilitate experimental design.