 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Video Anomaly Detection for Stereotypical Behaviours in Autism
Feb 27, 2023Monitoring and analyzing stereotypical behaviours is important for early intervention and care taking in Autism Spectrum Disorder (ASD). This paper focuses on automatically detecting stereotypical behaviours with computer vision techniques. Off-the-shelf methods tackle this task by supervised classification and activity recognition techniques. However, the unbounded types of stereotypical behaviours and the difficulty in collecting video recordings of ASD patients largely limit the feasibility of the existing supervised detection methods. As a result, we tackle these challenges from a new perspective, i.e. unsupervised video anomaly detection for stereotypical behaviours detection. The models can be trained among unlabeled videos containing only normal behaviours and unknown types of abnormal behaviours can be detected during inference. Correspondingly, we propose a Dual Stream deep model for Stereotypical Behaviours Detection, DS-SBD, based on the temporal trajectory of human poses and the repetition patterns of human actions. Extensive experiments are conducted to verify the effectiveness of our proposed method and suggest that it serves as a potential benchmark for future research.
Towards Inference Efficient Deep Ensemble Learning
Jan 29, 2023Ensemble methods can deliver surprising performance gains but also bring significantly higher computational costs, e.g., can be up to 2048X in large-scale ensemble tasks. However, we found that the majority of computations in ensemble methods are redundant. For instance, over 77% of samples in CIFAR-100 dataset can be correctly classified with only a single ResNet-18 model, which indicates that only around 23% of the samples need an ensemble of extra models. To this end, we propose an inference efficient ensemble learning method, to simultaneously optimize for effectiveness and efficiency in ensemble learning. More specifically, we regard ensemble of models as a sequential inference process and learn the optimal halting event for inference on a specific sample. At each timestep of the inference process, a common selector judges if the current ensemble has reached ensemble effectiveness and halt further inference, otherwise filters this challenging sample for the subsequent models to conduct more powerful ensemble. Both the base models and common selector are jointly optimized to dynamically adjust ensemble inference for different samples with various hardness, through the novel optimization goals including sequential ensemble boosting and computation saving. The experiments with different backbones on real-world datasets illustrate our method can bring up to 56\% inference cost reduction while maintaining comparable performance to full ensemble, achieving significantly better ensemble utility than other baselines. Code and supplemental materials are available at https://seqml.github.io/irene.
Attentive Mask CLIP
Dec 16, 2022



Image token removal is an efficient augmentation strategy for reducing the cost of computing image features. However, this efficient augmentation strategy has been found to adversely affect the accuracy of CLIP-based training. We hypothesize that removing a large portion of image tokens may improperly discard the semantic content associated with a given text description, thus constituting an incorrect pairing target in CLIP training. To address this issue, we propose an attentive token removal approach for CLIP training, which retains tokens with a high semantic correlation to the text description. The correlation scores are computed in an online fashion using the EMA version of the visual encoder. Our experiments show that the proposed attentive masking approach performs better than the previous method of random token removal for CLIP training. The approach also makes it efficient to apply multiple augmentation views to the image, as well as introducing instance contrastive learning tasks between these views into the CLIP framework. Compared to other CLIP improvements that combine different pre-training targets such as SLIP and MaskCLIP, our method is not only more effective, but also much more efficient. Specifically, using ViT-B and YFCC-15M dataset, our approach achieves $43.9\%$ top-1 accuracy on ImageNet-1K zero-shot classification, as well as $62.7/42.1$ and $38.0/23.2$ I2T/T2I retrieval accuracy on Flickr30K and MS COCO, which are $+1.1\%$, $+5.5/+0.9$, and $+4.4/+1.3$ higher than the SLIP method, while being $2.30\times$ faster. An efficient version of our approach running $1.16\times$ faster than the plain CLIP model achieves significant gains of $+5.3\%$, $+11.3/+8.0$, and $+9.5/+4.9$ on these benchmarks.
Learning Domain Invariant Prompt for Vision-Language Models
Dec 08, 2022



Prompt learning is one of the most effective and trending ways to adapt powerful vision-language foundation models like CLIP to downstream datasets by tuning learnable prompt vectors with very few samples. However, although prompt learning achieves excellent performance over in-domain data, it still faces the major challenge of generalizing to unseen classes and domains. Some existing prompt learning methods tackle this issue by adaptively generating different prompts for different tokens or domains but neglecting the ability of learned prompts to generalize to unseen domains. In this paper, we propose a novel prompt learning paradigm that directly generates domain invariant prompt generalizable to unseen domains, called MetaPrompt. Specifically, a dual-modality prompt tuning network is proposed to generate prompts for inputs from both image and text modalities. More importantly, we propose a meta-learning-based prompt tuning algorithm that explicitly constrains the prompt tuned on a specific domain or class also to achieve good performance on another domain or class. Extensive experiments on 11 datasets for base-to-new generalization and four datasets for domain generalization demonstrate that our method consistently and significantly outperforms existing methods.
Invisible Backdoor Attack with Dynamic Triggers against Person Re-identification
Nov 20, 2022In recent years, person Re-identification (ReID) has rapidly progressed with wide real-world applications, but also poses significant risks of adversarial attacks. In this paper, we focus on the backdoor attack on deep ReID models. Existing backdoor attack methods follow an all-to-one/all attack scenario, where all the target classes in the test set have already been seen in the training set. However, ReID is a much more complex fine-grained open-set recognition problem, where the identities in the test set are not contained in the training set. Thus, previous backdoor attack methods for classification are not applicable for ReID. To ameliorate this issue, we propose a novel backdoor attack on deep ReID under a new all-to-unknown scenario, called Dynamic Triggers Invisible Backdoor Attack (DT-IBA). Instead of learning fixed triggers for the target classes from the training set, DT-IBA can dynamically generate new triggers for any unknown identities. Specifically, an identity hashing network is proposed to first extract target identity information from a reference image, which is then injected into the benign images by image steganography. We extensively validate the effectiveness and stealthiness of the proposed attack on benchmark datasets, and evaluate the effectiveness of several defense methods against our attack.
Online Video Super-Resolution with Convolutional Kernel Bypass Graft
Aug 04, 2022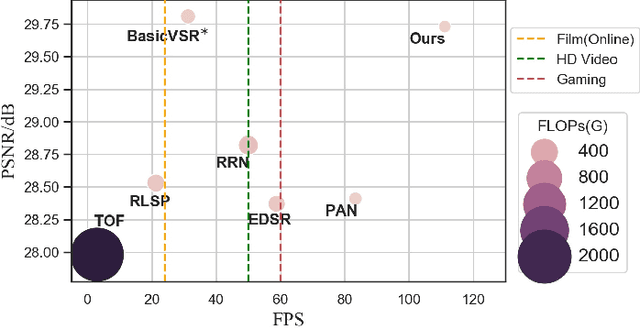

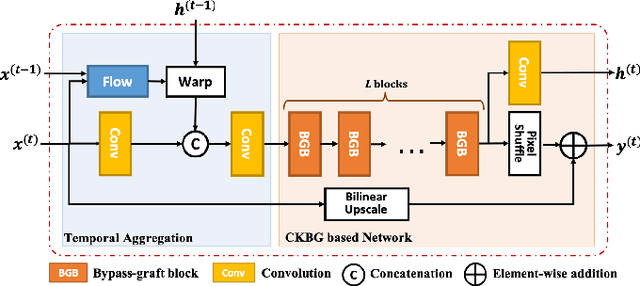
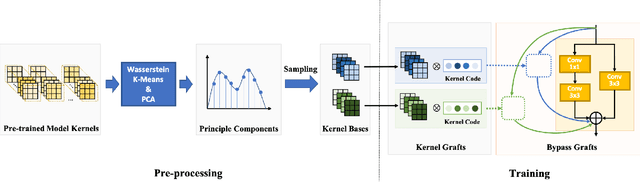
Deep learning-based models have achieved remarkable performance in video super-resolution (VSR) in recent years, but most of these models are less applicable to online video applications. These methods solely consider the distortion quality and ignore crucial requirements for online applications, e.g., low latency and low model complexity. In this paper, we focus on online video transmission, in which VSR algorithms are required to generate high-resolution video sequences frame by frame in real time. To address such challenges, we propose an extremely low-latency VSR algorithm based on a novel kernel knowledge transfer method, named convolutional kernel bypass graft (CKBG). First, we design a lightweight network structure that does not require future frames as inputs and saves extra time costs for caching these frames. Then, our proposed CKBG method enhances this lightweight base model by bypassing the original network with ``kernel grafts'', which are extra convolutional kernels containing the prior knowledge of external pretrained image SR models. In the testing phase, we further accelerate the grafted multi-branch network by converting it into a simple single-path structure. Experiment results show that our proposed method can process online video sequences up to 110 FPS, with very low model complexity and competitive SR performance.
Towards Privacy-Preserving Person Re-identification via Person Identify Shift
Jul 15, 2022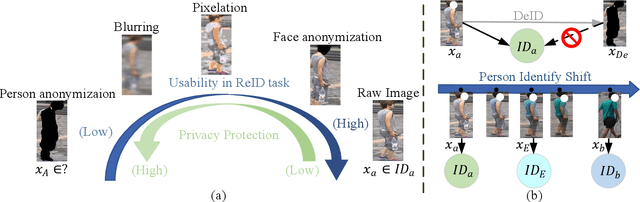
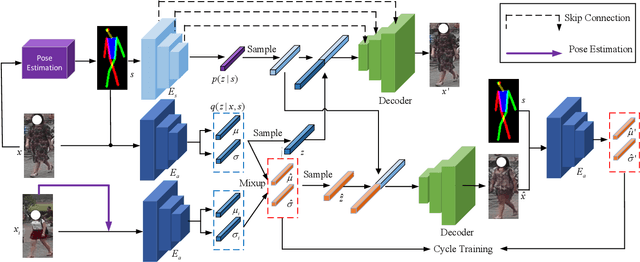


Recently privacy concerns of person re-identification (ReID) raise more and more attention and preserving the privacy of the pedestrian images used by ReID methods become essential. De-identification (DeID) methods alleviate privacy issues by removing the identity-related of the ReID data. However, most of the existing DeID methods tend to remove all personal identity-related information and compromise the usability of de-identified data on the ReID task. In this paper, we aim to develop a technique that can achieve a good trade-off between privacy protection and data usability for person ReID. To achieve this, we propose a novel de-identification method designed explicitly for person ReID, named Person Identify Shift (PIS). PIS removes the absolute identity in a pedestrian image while preserving the identity relationship between image pairs. By exploiting the interpolation property of variational auto-encoder, PIS shifts each pedestrian image from the current identity to another with a new identity, resulting in images still preserving the relative identities. Experimental results show that our method has a better trade-off between privacy-preserving and model performance than existing de-identification methods and can defend against human and model attacks for data privacy.
RendNet: Unified 2D/3D Recognizer With Latent Space Rendering
Jun 21, 2022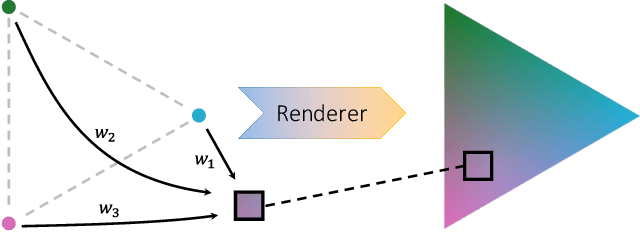
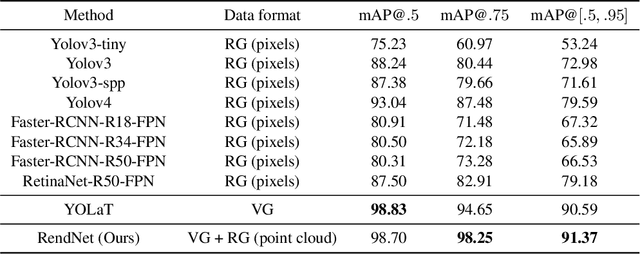
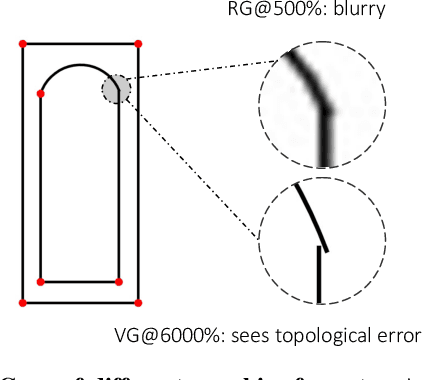
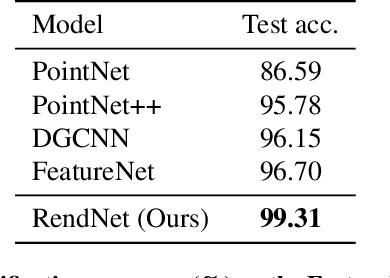
Vector graphics (VG) have been ubiquitous in our daily life with vast applications in engineering, architecture, designs, etc. The VG recognition process of most existing methods is to first render the VG into raster graphics (RG) and then conduct recognition based on RG formats. However, this procedure discards the structure of geometries and loses the high resolution of VG. Recently, another category of algorithms is proposed to recognize directly from the original VG format. But it is affected by the topological errors that can be filtered out by RG rendering. Instead of looking at one format, it is a good solution to utilize the formats of VG and RG together to avoid these shortcomings. Besides, we argue that the VG-to-RG rendering process is essential to effectively combine VG and RG information. By specifying the rules on how to transfer VG primitives to RG pixels, the rendering process depicts the interaction and correlation between VG and RG. As a result, we propose RendNet, a unified architecture for recognition on both 2D and 3D scenarios, which considers both VG/RG representations and exploits their interaction by incorporating the VG-to-RG rasterization process. Experiments show that RendNet can achieve state-of-the-art performance on 2D and 3D object recognition tasks on various VG datasets.
Privacy-preserving Online AutoML for Domain-Specific Face Detection
Mar 16, 2022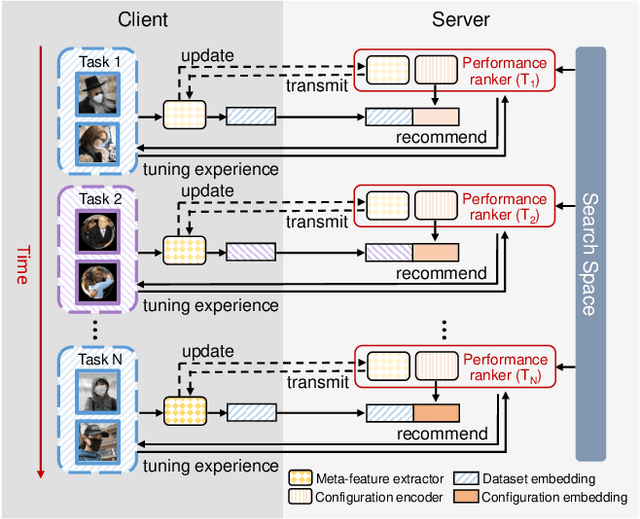
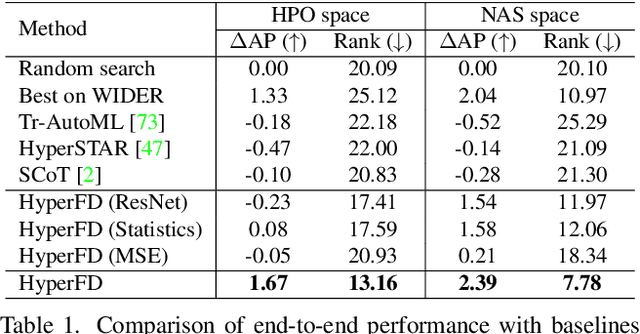
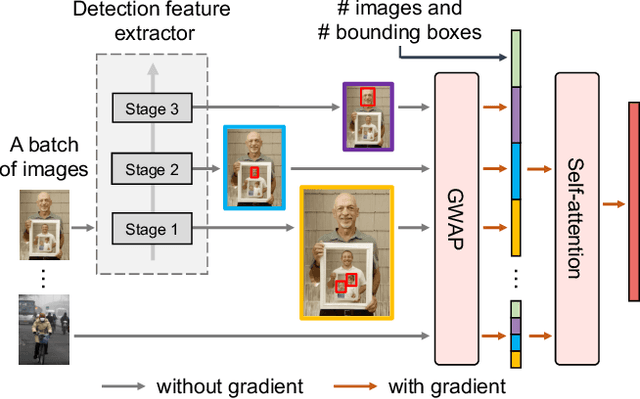
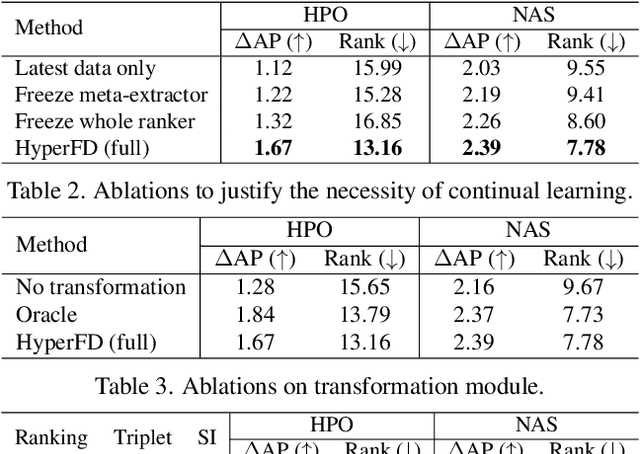
Despite the impressive progress of general face detection, the tuning of hyper-parameters and architectures is still critical for the performance of a domain-specific face detector. Though existing AutoML works can speedup such process, they either require tuning from scratch for a new scenario or do not consider data privacy. To scale up, we derive a new AutoML setting from a platform perspective. In such setting, new datasets sequentially arrive at the platform, where an architecture and hyper-parameter configuration is recommended to train the optimal face detector for each dataset. This, however, brings two major challenges: (1) how to predict the best configuration for any given dataset without touching their raw images due to the privacy concern? and (2) how to continuously improve the AutoML algorithm from previous tasks and offer a better warm-up for future ones? We introduce "HyperFD", a new privacy-preserving online AutoML framework for face detection. At its core part, a novel meta-feature representation of a dataset as well as its learning paradigm is proposed. Thanks to HyperFD, each local task (client) is able to effectively leverage the learning "experience" of previous tasks without uploading raw images to the platform; meanwhile, the meta-feature extractor is continuously learned to better trade off the bias and variance. Extensive experiments demonstrate the effectiveness and efficiency of our design.
Domain Generalization using Pretrained Models without Fine-tuning
Mar 09, 2022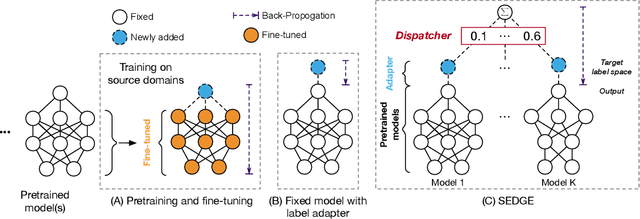
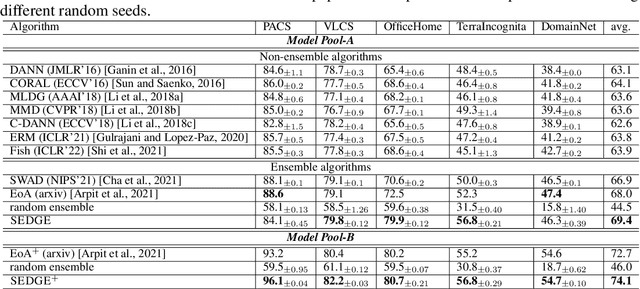
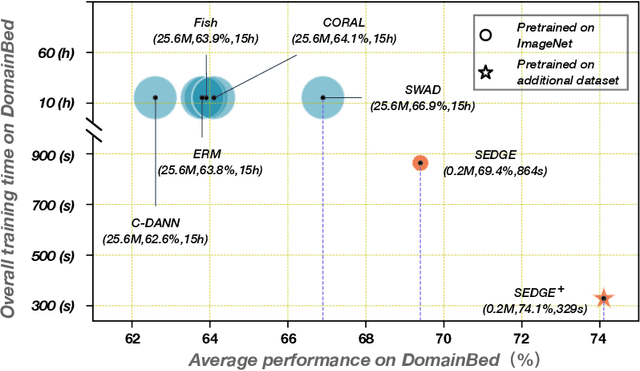

Fine-tuning pretrained models is a common practice in domain generalization (DG) tasks. However, fine-tuning is usually computationally expensive due to the ever-growing size of pretrained models. More importantly, it may cause over-fitting on source domain and compromise their generalization ability as shown in recent works. Generally, pretrained models possess some level of generalization ability and can achieve decent performance regarding specific domains and samples. However, the generalization performance of pretrained models could vary significantly over different test domains even samples, which raises challenges for us to best leverage pretrained models in DG tasks. In this paper, we propose a novel domain generalization paradigm to better leverage various pretrained models, named specialized ensemble learning for domain generalization (SEDGE). It first trains a linear label space adapter upon fixed pretrained models, which transforms the outputs of the pretrained model to the label space of the target domain. Then, an ensemble network aware of model specialty is proposed to dynamically dispatch proper pretrained models to predict each test sample. Experimental studies on several benchmarks show that SEDGE achieves significant performance improvements comparing to strong baselines including state-of-the-art method in DG tasks and reduces the trainable parameters by ~99% and the training time by ~99.5%.